list是R语言中包容性最强的数据对象,几乎可以容乃所有的其他数据类型。
但是包容性最强也也意味着他对于内部子对象的类型限制最少,甚至内部可以存在递归结构,这样给我们提取数据带来了很大的困难。
如果你对R语言的list结构非常熟悉,又熟练控制流等函数的操作,自然可以通过构建循环来完成目标数据的提取。但是在数据量大、结构及其复杂的情形下,自建循环无论是性能还是代码量上都很不经济。
好在确实有开发者在针对list数据结构进行操作上的优化,任坤老师的大作——rlist就是一个强大的list解析神器,它可以让我们像在dplyr、data.table操作data.frame一样,使用rlist轻松的实现对list数据类型的map(映射)、filter(筛选)、update(更新)、group(分组)、sort(排序)。
任坤老师的主页提供了很好地rlist实践方案,同时该包配套有非常详细的document,是你数据清洗工具箱中不可多得的list操纵神奇,配合tidyverse工具箱,你的数据warpping技能一定会得到大大扩展与提升。
在R语言环境中,我们最常遇到的list操作场景大概有以下三类(当然不含全部):
1、统计模型的输出结果:
因为统计模型在跑完之后,通过会输出一系列各种指标,比如及置信区间、判定指标和拟合值等,这些对象因为大小和长度不等,类型不一但是又必须输出,所以只能交给list这个容器来盛。
2、地理信息数据源:
无论是基于s3标准的sp空间数据结构,还是基于s4标准的sf空间数据结构,都容纳着大量的list对象。不过这些数据结构因为用途比较特殊,都有对应包来进行结构化处理(我们无须担心),rgdal可以很好的识别sp对象,sf包可以高效处理sf对象。
3、基于web的api访问返回的json数据包:
这种情形,尝试过网络数据抓取的小伙伴可能会频繁遇到,虽然这样省去了解析html/xml的麻烦,但是倘若原始的json内部结构比较复杂,解析起来非常麻烦。当然已经有好几个成熟的json结构包来进行json与R内置数据类型的转化,但是除非结构非常规整,否则仍然严重依赖lsit处理。
这一篇就以网络上获取到的json数据结构为例进行演示,当然rlist包内置函数数量非常庞大,一篇根本不足以涵盖所有的,仅以几个高频应用函数为例。
library("rlist")
library("pipeR")
第一类是I/O函数,也就是读写list结构。
如果本地有一个非关系型的json数据文件,可以用list.load无障碍加载(保存)。
###加载json文件(相当于jsonlite包中的fromJSON函数)
mydata<-list.load("E:/git/DataWarehouse/File/indy.json")
###保存list数据为json文件(相当于jsonlite包中的toJSON函数)
list.save(mydata,"E:/git/DataWarehouse/File/indy.json")
第二类是映射与筛选函数:
mydata<-mydata %>>% `[[`(1)
###%>>%是 一个与magrittr包中的%>>%函数功能一样的管道操作函数,
###任坤大大推荐在使用rlist的时候搭配pipR中的%>>%一起使用。
###(当然使用%>%也是可以的)。

###查看mydata的数据结构
class(mydata)
[1] "list"
str(mydata)

可以看到mydata的含有3个子list,每一个子list中有包含6个子对象。
mydara
映射(mapping)
list.map函数提供了list中元素的映射功能。
###将mydata的子list映射到name变量:
list.map(mydata,name)
[[1]]
[1] "Raiders of the Lost Ark"
[[2]]
[1] "Indiana Jones and the Temple of Doom"
[[3]]
[1] "Indiana Jones and the Last Crusade"
###将每个元素映射到制片人的数量:
list.map(mydata,length(producers))
[[1]]
[1] 3
[[2]]
[1] 1
[[3]]
[1] 2
索引函数:list.select
list.select(mydata,name,year)

虽然索引函数能够达到的目的与list.map类似,但是两者设计的初衷是不一样的,list.select可以完全类比dplyr中的select函数。
筛选(filtering)
筛选出上映年份在82年以后的影片:
str(list.filter(mydata, year>=1982))
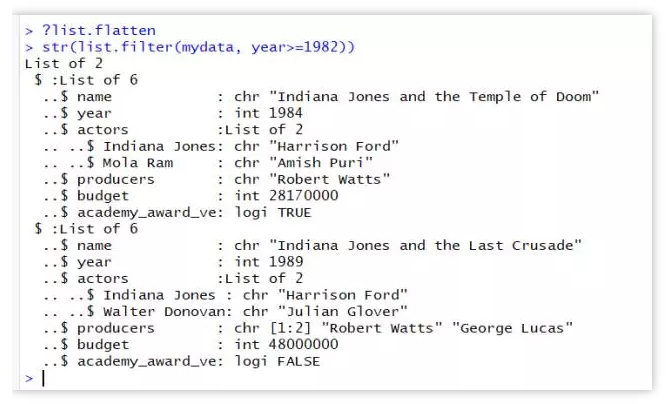
筛选出了两部上映年份为84年和89年的影片信息。
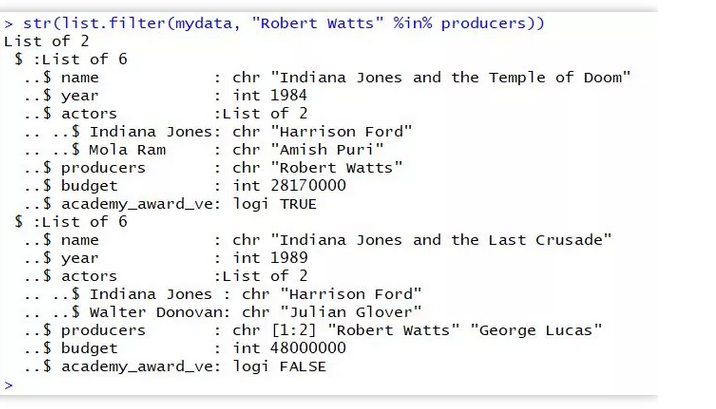
筛选出制片人中含有Robert Watts的电影记录:
str(list.filter(mydata, "Robert Watts" %in% producers))
分组(grouping)
按照年份做互斥分组:
str(list.group(mydata, year))
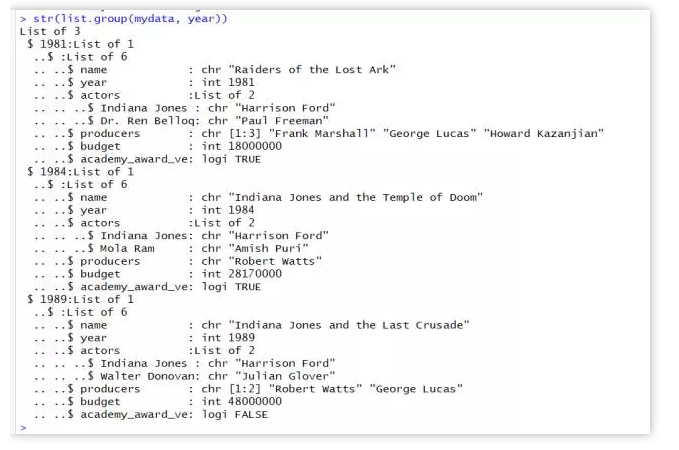
可以看到,当使用年份进行分组时,相当于又给mydata做了一次父级标签分类(类别即为我们选定的分组变量——年份)。
按照获奖与否做互斥分组:
str(list.group(mydata, academy_award_ve))
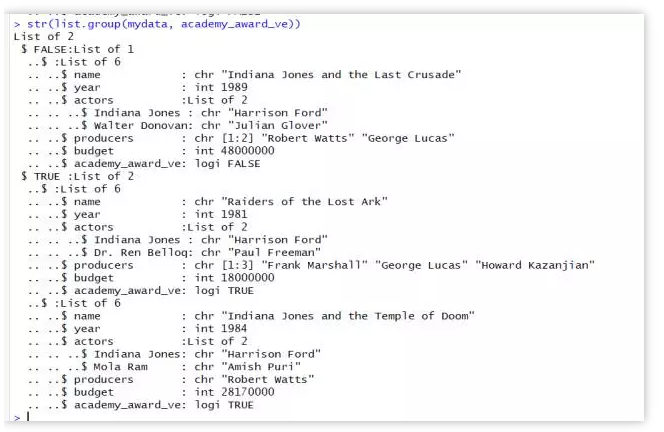
因为有两部电影获奖,一部没有获奖,最终输出结果即为按照获奖与否将mydata从新分成两组,组别标签即为是否获奖。
排序(sorting)
按照年份升序排列:
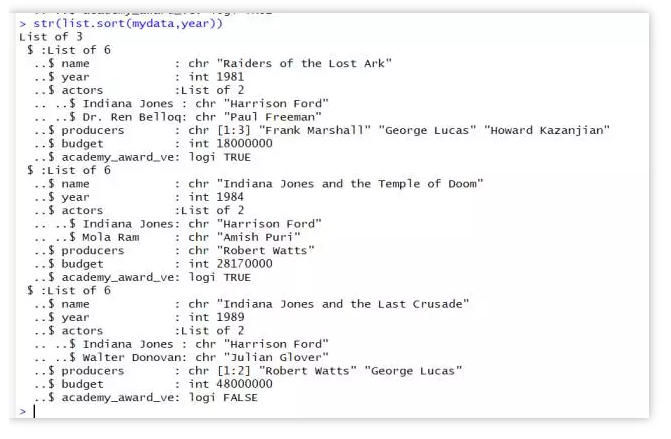
str(list.sort(mydata,year))
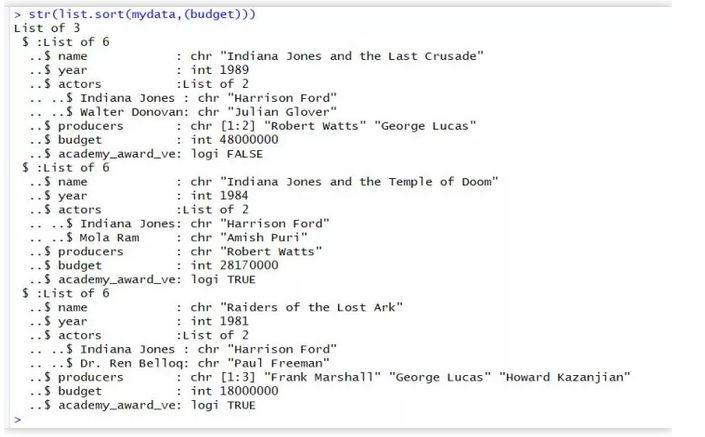
按照预算金额排序:
str(list.sort(mydata,(budget)))
#默认升序,加圆括号代表降序(多么清新脱俗到的设定呀)
第三类是合并与重塑函数:
就是如何将list在vector与data.frame之间进行转化。
list.stack #按行进行堆栈
list.rbind #这个与list.stack函数类似,也可以达到相同的效果
list.cbind #按列合并
list.flatten #将多层嵌套的递归结构转换为单层结构
list.stack
list.update(mydata,actors=NULL, producers=NULL) %>>% list.stack
#list.stack函数虽然也类似堆栈操作,但是它眼球要求更为严格,
#必须保持内部机构一致和list长度一致,为了达到这个目的,
#我们使用list.update函数现将存在递归和长度不等两个变量删除,
#然后使用list.rbind函数进行操作。
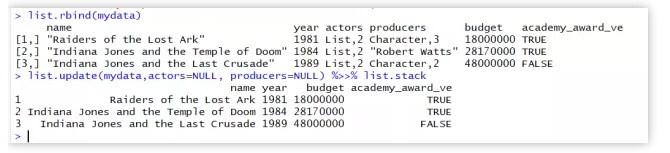
list.rbind(mydata)
#list.stack完成的效果就是将每一个子list按照names进行纵向堆积。
#(允许内部存在递归结构)

list.cbind
a<-1:10
b<-sample(LETTERS,10)
c<-rep(c(TRUE,FALSE),each=5)
mylist<-list(ID=a,NAME=b,ACCET=c)
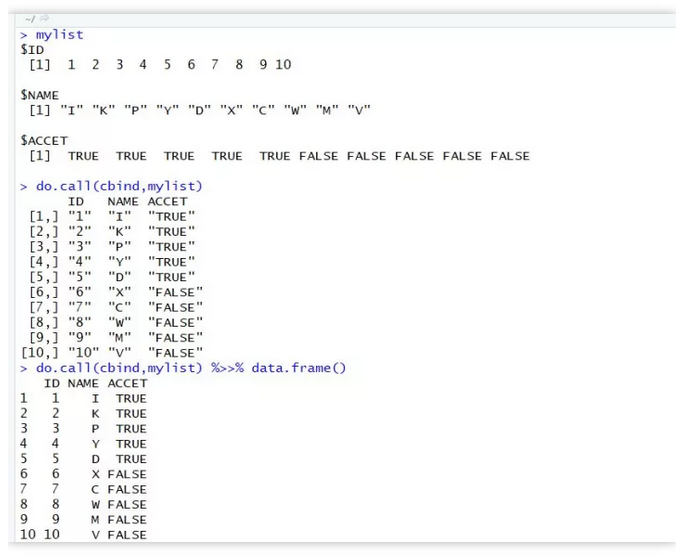
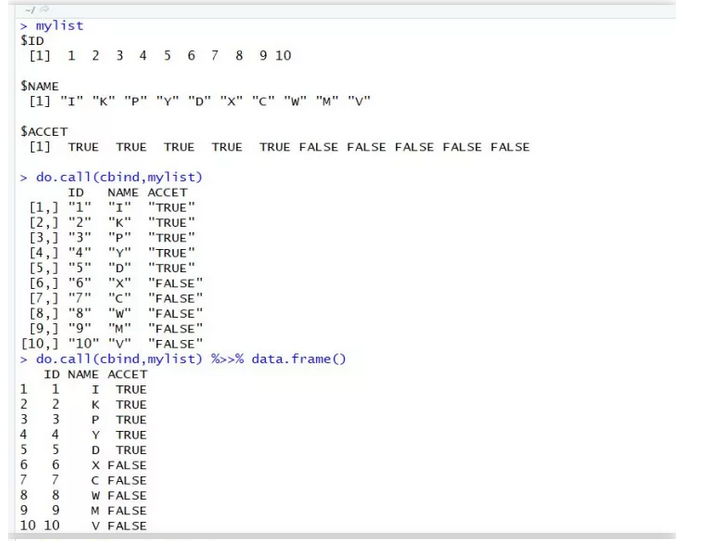
mylist对象有三个子list,每一个长度都为10,按照其实际意义,可以按列合并为data.frame。
do.call(cbind,mylist) %>>% data.frame()
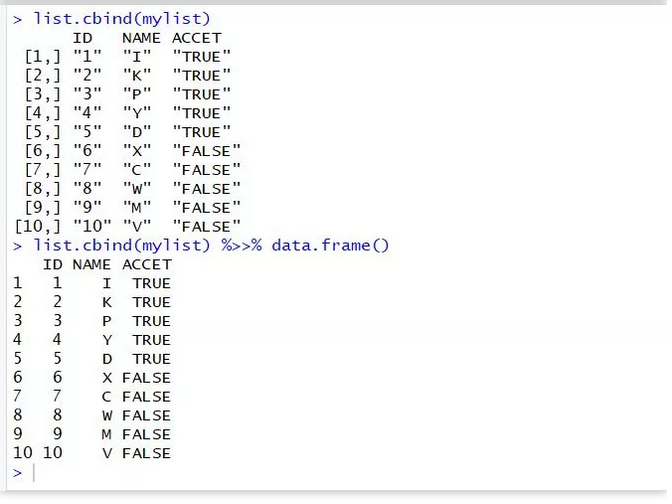
list.cbind(mylist) %>>% data.frame()
#list.cbind就更好理解了,它可以直接将子list按照列进行合并,
#使之成为规整的矩阵或者数据框(其意义与作用于cbind函数并无不同)。
list.flatten函数可以清除掉递归结构,有点儿类似于unlist函数。
list.flatten(mydata)
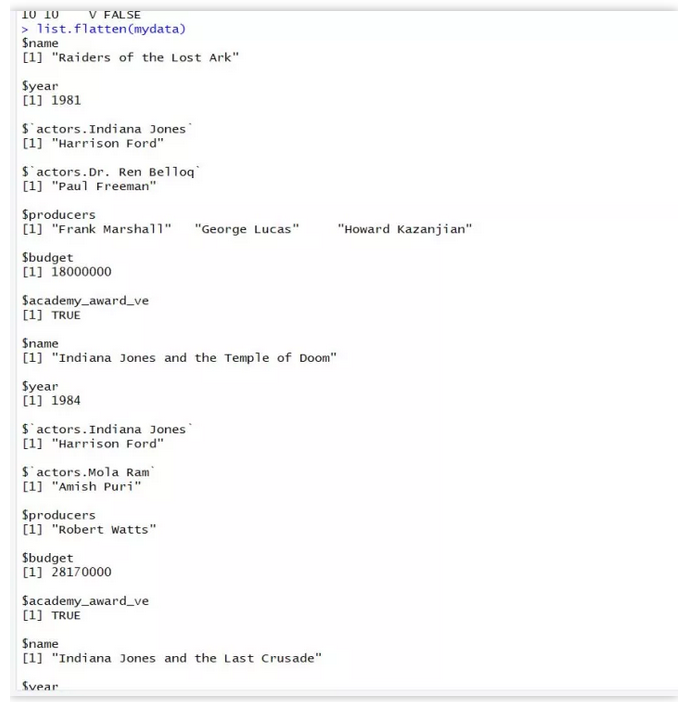
但是麻烦的是,list.flatten是毁灭式的清除,就是清除之后,相当于遍历了所有子节点,每一个子节点都会被识别为一个单独的字符串,这样我们下一步的数据清洗工作几乎没法进行了,所以慎用。(除非是很规整的递归结构,铺平之后你也许还有希望使用matrix结构进行合适的行列调整,还原这个数据表,但是那样也很费事)。
除此之外,rlist还有大量的list.find、list.merge、list.serch、list.extrct等让人眼花缭乱的高效list操纵函数(据说还支持lamda表达式),甚至可以直接解析XML文档,简直是list操纵的绝世神器呀!绝对值得一学!
如果你打算入手noSQL,那么R语言中的list就是很好地对标工具(Python中也许是dict吧)。
至于更为详细的rlist操纵技巧,请参考起官方文档或者任坤老师的主页!!!
参考资料:
https://cosx.org/2014/07/rlist-package
https://cran.r-project.org/web/packages/rlist/rlist.pdf
在线课程请点击R语言可视化在商务场景中的应用:
往期案例数据请移步本人GitHub:
https://github.com/ljtyduyu/DataWarehouse/tree/master/File

