之前我陆陆续续写了几篇介绍在网页抓取中CSS和XPath解析工具的用法,以及实战应用,今天这一篇作为系列的一个小结,主要分享使用R语言中Rvest工具和Python中的requests库结合css表达式进行html文本解析的流程。
css和XPath在网页解析流程中各有优劣,相互结合、灵活运用,会给网络数据抓取的效率带来很大提升!
R语言:
library("rvest")
url<-'https://read.douban.com/search?q=Python'
构建网页解析函数:
getcontent<-function(url){
myresult=data.frame()
title=subtitle=author=category=price=rating=eveluate_nums=c()
for (page in seq(0,3)){
link<-paste0(url,'&start=',page*10)
result<-link %>% read_html(encoding="UTF-8")
###计算每一页有多少条书籍信息:
length=length(result %>% html_nodes("ol.ebook-list.column-list li"))
###提取图书标题信息:
title=result %>% html_nodes(".title a,h4 a") %>% html_text() %>% c(title,.)
###考虑分类,枚举出所有分类标签
category=result %>% html_nodes(".category") %>% html_text() %>% c(category,.)
###提取作者、副标题、评价、评分、价格:
author_text=subtext=eveluate_text=rating_text=price_text=rep('',length)
for (i in 1:length){
###考虑作者不唯一的情况:
author_text[i]=result %>% html_nodes(sprintf("ol li:nth-of-type(%d) div.info > p:nth-of-type(1) a,ol li:nth-of-type(%d) .author a",i,i)) %>% html_text() %>% paste(collapse ='/')
###考虑副标题是否存在
if (result %>% html_nodes(sprintf("ol li:nth-of-type(%d) .subtitle",i)) %>% length() != 0){
subtext[i]=result %>% html_nodes(sprintf("ol li:nth-of-type(%d) .subtitle",i)) %>% html_text()
}
###考虑评价是否存在:
if (result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) a.ratings-link span",i)) %>% length() !=0){
eveluate_text[i]=result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) a.ratings-link span",i)) %>% html_text()
}
###考虑评分是否存在:
if (result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.rating-average",i)) %>% length() != 0){
rating_text[i]=result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.rating-average",i)) %>% html_text()
}
###考虑价格是否存在:
if (result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.price-tag",i)) %>% length() != 0){
price_text[i]=result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.price-tag",i)) %>% html_text()
}
}
###合并以上信息
author=c(author,author_text)
subtitle=c(subtitle,subtext)
eveluate_nums=c(eveluate_nums,eveluate_text)
rating=c(rating,rating_text)
price=c(price,price_text)
###打印任务状态:
print(sprintf("page %d is over!!!",page+1))
}
###打印全局任务状态
print("everything is OK")
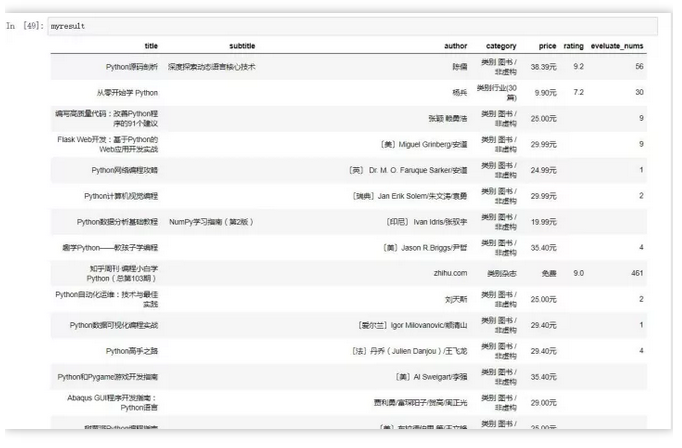
myresult=data.frame(title,subtitle,author,category,price,rating,eveluate_nums)
return (myresult)
}
运行自动抓取函数:
myresult=getcontent(url)
检查数据结构并修正:
str(myresult)
myresult$price<-myresult$price %>% sub("元|免费","",.) %>% as.numeric()
myresult$rating<-as.numeric(myresult$rating)
myresult$eveluate_nums<-as.numeric(myresult$eveluate_nums)
DT::datatable(myresult)
Python:
#! /usr/bin/env
python#coding=utf-8
import requests,re
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
url='https://read.douban.com/search?q=Python'
header ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36'}
构建网页抓取及解析函数:
def getcontent(url):
myresult={}
title=[];subtitle=[];author=[];category=[];price=[];rating=[];eveluate_nums=[]
for page in range(0,4):
link=url+'&start='+str(page*10)
content=requests.get(link,headers=header)
result=BeautifulSoup(content.text,'lxml')
###计算每一页有多少条书籍信息:
length=len(result.select("ol.ebook-list.column-list li"))
###提取图书标题信息:
title.extend([text.get_text() for text in result.select(".title a,h4 a")])
###考虑分类,枚举出所有分类标签
category.extend([text.get_text() for text in result.select(".category")])
###提取作者、副标题、评价、评分、价格:
author_text=['']*length;subtext=['']*length;eveluate_text=['']*length;rating_text=['']*length;price_text=['']*length
for i in range(1,length+1):
###考虑作者不唯一的情况:
author_text[i-1]=['/'.join(text) for text in result.select("ol li:nth-of-type({0}) div.info > p:nth-of-type(1) a,ol li:nth-of-type({0}) .author a".format(i))]
###考虑副标题是否存在
if result.select("ol li:nth-of-type({0}) .subtitle".format(i)) != []:
subtext[i-1]=result.select("ol li:nth-of-type({0}) .subtitle".format(i))[0].get_text()
###考虑评价是否存在:
if result.select("ol > li:nth-of-type({0}) a.ratings-link span".format(i)) !=[]:
eveluate_text[i-1]=[text.get_text() for text in result.select("ol > li:nth-of-type({0}) a.ratings-link span".format(i))]
###考虑评分是否存在:
if result.select("ol > li:nth-of-type({0}) span.rating-average".format(i)) != []:
rating_text[i-1]=[text.get_text() for text in result.select("ol > li:nth-of-type({0}) span.rating-average".format(i))]
###考虑价格是否存在:
if len(result.select("ol > li:nth-of-type({0}) span.price-tag".format(i))) != []:
price_text[i-1]=[text.get_text() for text in result.select("ol > li:nth-of-type({0}) span.price-tag".format(i))]
###合并以上信息
author.extend(author_text)
subtitle.extend(subtext)
eveluate_nums.extend(eveluate_text)
rating.extend(rating_text)
price.extend(price_text)
###打印任务状态:
print("page {} is over!!!".format(page+1))
###打印全局任务状态
print("everything is OK")
myresult={"title":title,"subtitle":subtitle,"author":author,"category":category,"price":price,"rating":rating,"eveluate_nums":eveluate_nums}
return myresult
运行自定义抓取函数:
myresult=getcontent(url)
查看字典内部长度
for i,m in myresult.items():
print(i+":"+str(len(m)))
title:39
subtitle:39
author:39
category:39
price:39
rating:39
eveluate_nums:39
铺平嵌套列表:
def flatten(input_list):
output_list = []
while True:
if input_list == []:
break
for index, i in enumerate(input_list):
if type(i)== list:
input_list = i + input_list[index+1:]
break
else:
output_list.append(i)
input_list.pop(index)
break
return output_list
myresult['author']=["/".join(text) for text in myresult['author']]
myresult['author']=flatten(myresult['author'])
myresult['eveluate_nums']=flatten(myresult['eveluate_nums'])
myresult['price']=flatten(myresult['price'])
myresult['rating']=flatten(myresult['rating'])
替换缺失值:
def DropNone(input_list):
for i in range(0,len(input_list)):
if len(input_list[i])==0:
input_list[i]=np.nan
else:
input_list[i]=input_list[i]
return input_list
def DropNoneToZero(input_list):
for i in range(0,len(input_list)):
if len(input_list[i])==0:
input_list[i]=0
else:
input_list[i]=input_list[i]
return input_list
清洗价格变量中的无效字符串:
def getprice(list):
aaa=['']
for i in myresult['price']:
try:
aaa.append(re.search(r"(\d{1,}\.\d{1,}).*?",i).group())
except AttributeError:
aaa.append('')
return(aaa)myresult['price']=getprice(myresult['price'])
myresult['eveluate_nums']=DropNoneToZero(myresult['eveluate_nums'])
myresult['price']=DropNone(myresult['price'])
myresult['rating']=DropNone(myresult['rating'])
转换为数据框:
mydata=pd.DataFrame(myresult)
mydata=mydata.astype({'eveluate_nums':'int','price':'float', 'rating':'float'})
mydata.columns
mydata.dtypes
在线课程请点击链接:
Hellobi Live | 9月12日 R语言可视化在商务场景中的应用
往期案例数据请移步本人GitHub:
https://github.com/ljtyduyu/DataWarehouse/tree/master/File
