因子选股模型是应用最为广泛的一种选股模型,基本原理是采用某个或某些因子作为选股的标准,满足这些因子的股票则被买入,不满足的则卖出。
因子选股模型为什么适用?举一个简单的例子:如果有一批人参加马拉松,想知道哪些人能获得不错的成绩,只需在跑前做一个身体测试即可。测试可以用一个或多个指标。对测试的结果进行排名,排名靠前的运动员获得好成绩的可能性就比较大。因子选股模型的原理与此类似,可以利用某些指标(因子)选择未来可能表现较好的股票。
常见因子从三方面:1)公司层面因子;2)外部环境因子;3)市场表现因子。
(一)公司层面因子
公司层面因子来自于公司的微观结构,与公司的生产经营息息相关,一般来自公司的财务指标,反映了公司的盈利、运营、债务和成长状况。这些因子主要有:1)价值类因子,如PE、PB;2)成长类因子,如ROE、净利润增长率;3)规模类因子,如净利润、营业收入;4)情绪类因子,如预测未来12个月的利润增长率;5)质量类因子,如资产负债率、应收账款周转率。
(二)外部环境因子
政治法律、宏观经济、社会习俗和技术发展等外部环境对一个行业和企业来说都是非常重要的。比较重要并且容易量化的外部环境因子主要是1)宏观环境因子,如经济增长率、利率等;2)行业环境,如行业集中度等。
(三)市场表现因子
市场表现因子主要体现的是股票在交易过程中的价格和交易量。这些因子主要有动量和反转类因子、资金流向和各种技术类指标等。
因子选股模型想法比较简单,几乎用不到特别复杂的数学模型。如果从数学的角度来看,因子选股模型仅仅是一个从因子到资金曲线的映射:
f(factors,parameters)=equity
其中f表示交易系统(线性或非线性),实际建模时可以用回归法或打分法进行简化处理。Factors是我们筛选出来的一些有效因子,如果这些因子有信息重叠,可以采用多元统计中的主成分分析或因子分析进行降维处理。Parameters是建模时遇到的各种参数,它们包括因子的权重、观察时间长度和持有时间长度等。Equity是资金曲线,它反映我们账户随时间的变化情况。通过对资金曲线equity的一些再处理,就可以得到一些评价指标(如年化收益率、年化夏普比率和最大回撤等),通过这些指标可以来评价该投资策略的效果。
从上面的模型可以可以看出,因子选股模型最重要的有两方面:一个是有效因子的选择,另一个是因子参数的选择。例如到底是PE有效还是ROE有效;到底是采用1个月做调仓周期还是3个月做调仓周期。这些因子和参数的获取只能通过历史数据的回测来获得。
筛选多因子的步骤可以从
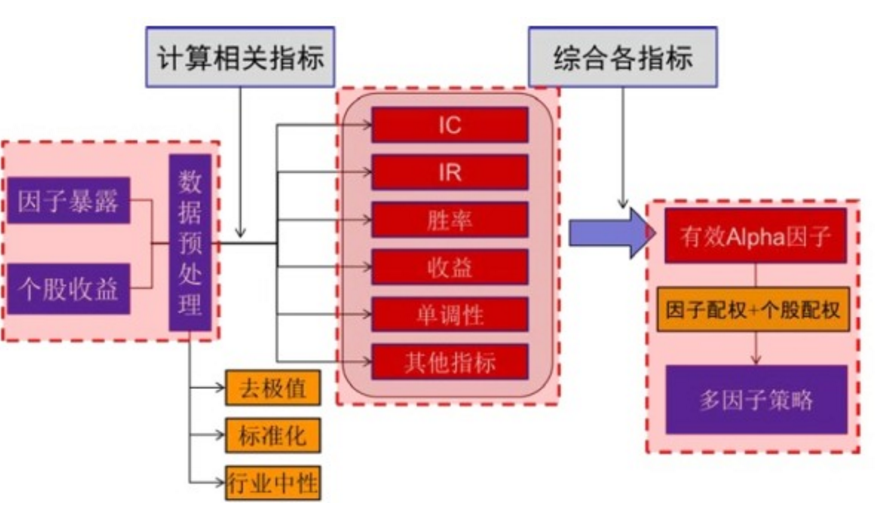
利用量化计算的因子从成百上千的股票中进行快速筛选,帮助投资者从海量的数据中快速确定符合要求的目标,以下我们以量化因子计算过程的实例来展示如何利用pandas处理数据。
首先导入一些外部模块:
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
import statsmodels.api as sm
import scipy.stats as scs
import matplotlib.pyplot as plt
每月初取所有因子
factors = ['B/M','EPS','PEG','ROE','ROA','GP/R','P/R','L/A','FAP','CMV']
#月初取出因子数值
def get_factors(fdate,factors):
stock_set = get_index_stocks('000001.XSHG',fdate)
q = query(
valuation.code,
balance.total_owner_equities/valuation.market_cap/100000000,
income.basic_eps,
valuation.pe_ratio,
income.net_profit/balance.total_owner_equities,
income.net_profit/balance.total_assets,
income.total_profit/income.operating_revenue,
income.net_profit/income.operating_revenue,
balance.total_liability/balance.total_assets,
balance.fixed_assets/balance.total_assets,
valuation.circulating_market_cap
).filter(
valuation.code.in_(stock_set),
valuation.circulating_market_cap
)
fdf = get_fundamentals(q, date=fdate)
fdf.index = fdf['code']
fdf.columns = ['code'] + factors
return fdf.iloc[:,-10:]
fdf = get_factors('2015-01-01',factors)
fdf.head()
排序:
score = fdf['B/M'].order()
score.head()
模型构建:
def score_stock(fdate):
#CMV,FAP,PEG三个因子越小收益越大,分值越大,应降序排;B/M,P/R越大收益越大应顺序排
effective_factors = {'B/M':True,'PEG':False,'P/R':True,'FAP':False,'CMV':False}
fdf = get_factors(fdate)
score = {}
for fac,value in effective_factors.items():
score[fac] = fdf[fac].rank(ascending = value,method = 'first')
print DataFrame(score).T.sum().order(ascending = False).head(5)
score_stock = list(DataFrame(score).T.sum().order(ascending = False).index)
return score_stock,fdf['CMV']
def get_factors(fdate):
factors = ['B/M','PEG','P/R','FAP','CMV']
stock_set = get_index_stocks('000001.XSHG',fdate)
q = query(
valuation.code,
balance.total_owner_equities/valuation.market_cap/100000000,
valuation.pe_ratio,
income.net_profit/income.operating_revenue,
balance.ffixed_assets/balance.total_assets,
valuation.circulating_market_cap
).filter(
valuation.code.in_(stock_set)
)
fdf = get_fundamentals(q,date = fdate)
fdf.index = fdf['code']
fdf.columns = ['code'] + factors
return fdf.iloc[:,-5:]
[score_result,CMV] = score_stock('2016-01-01')
year = ['2009','2010','2011','2012','2013','2014','2015']
month = ['01','02','03','04','05','06','07','08','09','10','11','12']
factors = ['B/M','PEG','P/R','FAP','CMV']
result = {}
for i in range(7*12):
startdate = year[i/12] + '-' + month[i%12] + '-01'
try:
enddate = year[(i+1)/12] + '-' + month[(i+1)%12] + '-01'
except IndexError:
enddate = '2016-01-01'
try:
nextdate = year[(i+2)/12] + '-' + month[(i+2)%12] + '-01'
except IndexError:
if enddate == '2016-01-01':
nextdate = '2016-02-01'
else:
nextdate = '2016-01-01'
print 'time %s'%startdate
#综合5个因子打分后,划分几个组合
df = DataFrame(np.zeros(7),index = ['Top20','port1','port2','port3','port4','port5','benchmark'])
[score,CMV] = score_stock(startdate)
port0 = score[:20]
port1 = score[: len(score)/5]
port2 = score[ len(score)/5+1: 2*len(score)/5]
port3 = score[ 2*len(score)/5+1: -2*len(score)/5]
port4 = score[ -2*len(score)/5+1: -len(score)/5]
port5 = score[ -len(score)/5+1: ]
print len(score)
df.ix['Top20'] = caculate_port_monthly_return(port1,startdate,enddate,nextdate,CMV)
df.ix['port1'] =
caculate_port_monthly_return(port1,startdate,enddate,nextdate,CMV)
df.ix['port2'] = caculate_port_monthly_return(port2,startdate,enddate,nextdate,CMV)
df.ix['port3'] = caculate_port_monthly_return(port3,startdate,enddate,nextdate,CMV)
df.ix['port4'] = caculate_port_monthly_return(port4,startdate,enddate,nextdate,CMV)
df.ix['port5'] = caculate_port_monthly_return(port5,startdate,enddate,nextdate,CMV)
df.ix['benchmark'] = caculate_benchmark_monthly_return(startdate,enddate,nextdate)
result[i+1]=df
backtest_results = pd.DataFrame(result)
回测可以在优矿上https://uqer.io/community/share/5538c7d4f9f06c3c92306684
查看回测结果
相关文献:
【研究】量化选股-因子检验和多因子模型的构建 - 知乎专栏
多因子模型水平测试题 | 科学投资
【精品优秀毕业论文】因子选股模型在中国市场的实证研究
对多因子选股感兴趣的小伙伴看过来~~ - 雪球
不可不知的量化因子模型选股策略-搜狐

