
也是看到知乎的这个问题你写过什么有趣的程序? - 面包君的回答 - 知乎,的确有很多大神写过很多好玩的东西,当年写程序的时候也是一点都不感兴趣,主要是不知道干嘛用,就像当年一直吵着要学PS,也直到美图秀秀开始盛行的时候不由自主的就去研究PS。
刚接触数据这块的时候,就尝试着希望能够把数据从搜集到保存的流程都弄清楚(最简单的网站数据模型),到现在在新浪博客上应该还可能找到当年的代码。业余时间在家也爬了些成人网站的图片,幻想着开一个草榴网站O(∩_∩)O(年少的梦想),想想也挺逗的。这里把Python爬成人色情网站的代码共享给老司机们(只供技术交流,违法违规概不负责)。
其实爬过数据的人都知道很简单,一种是urllib爬的,还是比较简单的就是beautifulsoup。
比如我们先打开一个草榴类的网站(此处跳失率应该很高!)
里面的html js代码结构是比较简单的,URL结构如下:
http://www.*****.com/tupianqu/yazhou/111111.html
第一种用beautifulsoup解析html
# encoding=utf-8
import urllib
from bs4 import BeautifulSoup
debug = True # 设置是否打印log
def log(message):
if debug:
print message
#面包收藏夹
def download_image(url, save_path):
''' 根据图片url下载图片到save_path '''
try:
urllib.urlretrieve(url, save_path)
log('Downloaded a image: ' + save_path)
except Exception, e:
print 'An error catched when download a image:', e
def load_page_html(url):
''' 得到页面的HTML文本 '''
log('Get a html page : ' + url)
return urllib.urlopen(url).read()
def down_page_images(page, save_dir):
''' 下载第page页的图片 '''
html_context = load_page_html('http://www.*****.com/tupianqu/yazhou/%d.html' % page)
soup = BeautifulSoup(html_context)
for ui_module_div in soup.findAll('div', {'class': 'ui-module'}):
img_tag = ui_module_div.find('img')
if img_tag is not None and img_tag.has_attr('alt') and img_tag.has_attr('src'):
alt = img_tag.attrs['alt'] # 图片的介绍
src = img_tag.attrs['src'] # 图片的地址
filename = '%s%s' % (alt, src[-4:]) # 取后四位(有的图片后缀是'.jpg'而有的是'.gif')
download_image(src, save_dir + filename)
def download_qbcr(frm=1, page_count=1, save_dir='./'):
for x in xrange(frm, frm + page_count):
log('Page : ' + `x`)
down_page_images(x, save_dir)
def main():
base_path = '~/temp/'
download_qbcr(frm=1, page_count=10, save_dir=base_path)
if __name__ == '__main__':
main()
debug用来控制日志是否打印,当只需要悄悄下载图片,不想要提示的时候,debug=False就好啦。
download_image()函数用来下载图片,它接收一个图片的url和保存的路径,然后下载它。
load_page_html()函数接收一个页面的url并返回其页面的HTML代码。
download_qbcr()函数是整个下载的入口,它接收下载开始的页面序号frm(比如第1页)和下载的页面数量以及需要保存的位置,然后就开始处理每一页并下载。
这段代码中,使用到BeautifulSoup的地方只有down_page_images()函数。BeautifulSoup类接受一段HTML或者XML来构造一个对象,soup.findAll('div', {'class': 'ui-module'})表示,从soup对象对应的HTML中得到所有class属性为ui-module的div,ui-module就是页面盛放图片的那些div:
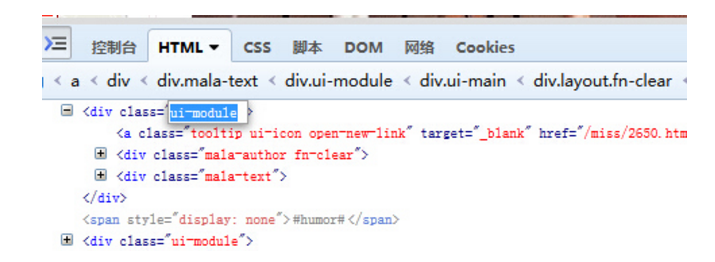
然后,对这个div里的数据简要分析+处理,就可以得出图片的介绍和链接了:
img_tag = ui_module_div.find('img')
if img_tag is not None and img_tag.has_attr('alt') and img_tag.has_attr('src'):
alt = img_tag.attrs['alt'] # 图片的介绍
src = img_tag.attrs['src'] # 图片的地址
filename = '%s%s' % (alt, src[-4:]) # 取后四位(有的图片后缀是'.jpg'而有的是'.gif')
第二种就是通过urllib爬稍微麻烦点
主要就是拿到不同的类目,url和图片地址
拿到不同类目:亚洲/欧美/卡通动漫等通过get_img_type_list
def get_img_type_list():
lst = []
result = re.findall(ur'<a.+?</a>', urllib.urlopen(WEBSITE + '/js/head.js').read())
for x in result:
if x.find('piclist') > 0:
item = (x[x.find('href='https://ask.hellobi.com/) + 6: x.rfind('"')], x[x.find('>') + 1:x.rfind('</a>')])
lst.append(item)
return lst
正常每一张图片对应着一个标签并且图片链接在src中,故以此可以构建一个分析HTML页面的解析器:
class ImagePageParser(sgmllib.SGMLParser):
''' parse a image page's image urls '''
def __init__(self):
sgmllib.SGMLParser.__init__(self)
self.imgurlList = []
def unknown_starttag(self, tag, attrs):
if tag == 'meta' and attrs[0][6] == 'description':
self.title = attrs[1][7].decode('utf-8').encode('gb2312').strip()
elif tag == 'img':
for key, value in attrs:
self.imgurlList.append(value) if key == 'src' else None
在ImagePageParser中,我们通过title保存当前页面的标题,用imgurlList保存每一个图片的地址。现在需要构建一个函数来使用ImagePageParser,并返回所有的图片地址以及这些图片的标题:
def get_image_url_list(page_url):
''''' get all image urls from a page '''
parser = ImagePageParser()
parser.feed(urllib2.urlopen(page_url).read())
return parser.imgurlList, parser.title
get_image_url_list函数返回pageUrl页面里所有图片的地址以及这个页面的标题。
得到页面所有图片地址后,再用另一个函数,一次性把一个列表中所有的图片下载下来:
def download_image(img_list, save=''):
''' download images of a list '''
if not (os.path.exists('save') and os.path.isdir(save)):
os.makedirs(save)
for x in img_list:
try:
filename = save + '\\' + x[x.rfind('/') + 1:]
print filename
urllib.urlretrieve(x, filename)
except Exception, e:
print >> open(r'C:\__temp\log.txt', 'a'), str(filename), `e` #包含图片的C盘
在download_image()函数中,我们接收一个图片地址列表和一个保存路径(非必须,如果没有则在当前目录下保存),函数开始时if是为了保证在传入的save路径不存在时,先创建一个文件夹。然后是遍历图片地址的列表,通过urllib.urlretrieve()函数来下载每一个图片。
我们在for里面使用try-except的目的是,当下载一张图片发生错误时(网络断线、文件IO出错或者任何未知错误时),不会让整个程序崩溃掉。
当电脑空闲的时候,就可以悄悄在后台跑起来下载图片了,简单粗暴。
