

从零起步,构建Spark集群经典四部曲:
第一步:搭建Hadoop单机和伪分布式环境;
第二步:构造分布式Hadoop集群;
第三步:构造分布式的Spark集群;
第四步:测试Spark集群;
本文内容为构建Spark集群经典四部曲,从零起步构建Hadoop单机版本和伪分布式的开发环境,涉及:
开发Hadoop需要的基本软件;
安装每个软件;
配置Hadoop单机模式并运行Wordcount示例;
配置Hadoop伪分布式模式并运行Wordcount示例;
第一步:开发Hadoop需要的基本软件
我们的开发环境是在Windows 7上面构建Hadoop,此时需要Vmware虚拟机、Ubuntu的ISO镜像文件,Java SDK的支持、Eclipse IDE平台、Hadoop安装包等;
1、Vmware虚拟机,这里使用的是VMware Workstation 9.0.2 for Windows, 具体的下载地址是https://my.vmware.com/cn/web/vmware/details?downloadGroup=WKST-902-WIN&productId=293&rPId=3526 如下图所示:
可以看出里面多了一个keys.txt文件,这个是安装Vwware时需要的序列码,读者需要从网络上下载;
2、Ubuntu的ISO镜像文件,家林这里使用的ubuntu-12.10-desktop-i386,具体下载地址为:其他选择方案 如下图所示:
3、Java SDK的支持,使用的是最新的“jdk-7u60-linux-i586.tar.gz”,具体的下载地址Java SE Development Kit 7 如下图所示:
4、下载最新稳定版本的Hadoop,下载的是“hadoop-1.1.2-bin.tar.gz ”,具体官方下载地址为http://mirrors.cnnic.cn/apache/hadoop/common/stable/ 下载后在本地的保存为:
在VMWare 中准备第二、第三台运行Ubuntu系统的机器;
在VMWare中构建第二、三台运行Ubuntu的机器和构建第一台机器完全一样,再次不在赘述。。
与安装第一台Ubuntu机器不同的几点是:
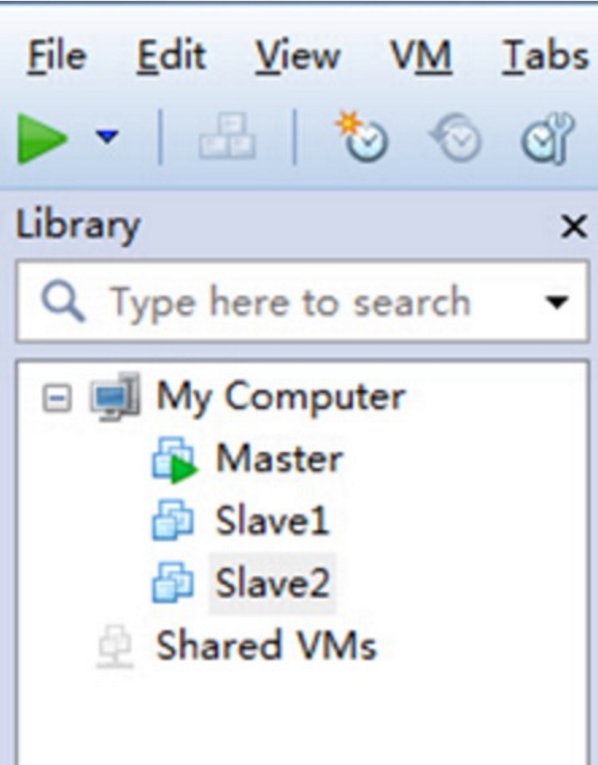
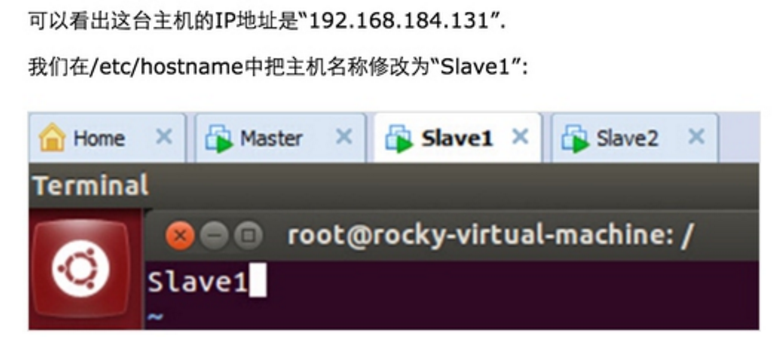
第一点:我们把第二、三台Ubuntu机器命名为了Slave1、Slave2,如下图所示:
创建完的VMware中就有三台虚拟机了:
第二点:为了简化Hadoop的配置,保持最小化的Hadoop集群,在构建第二、三台机器的时候使用相同的root超级用户的方式登录系统。
2.按照配置伪分布式模式的方式配置新创建运行Ubuntu系统的机器;
按照配置伪分布式模式的方式配置新创建运行Ubuntu系统的机器和配置第一台机器完全相同,
下图是家林完全安装好后的截图:
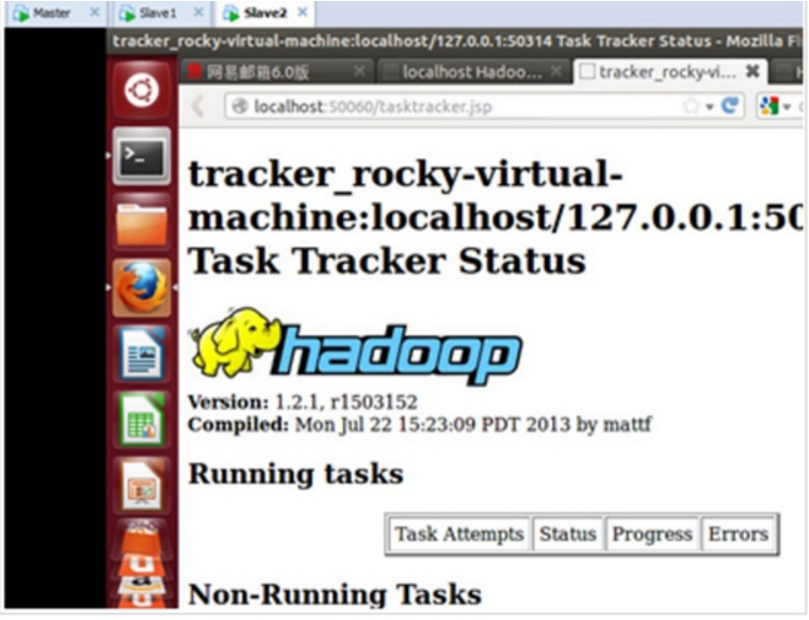
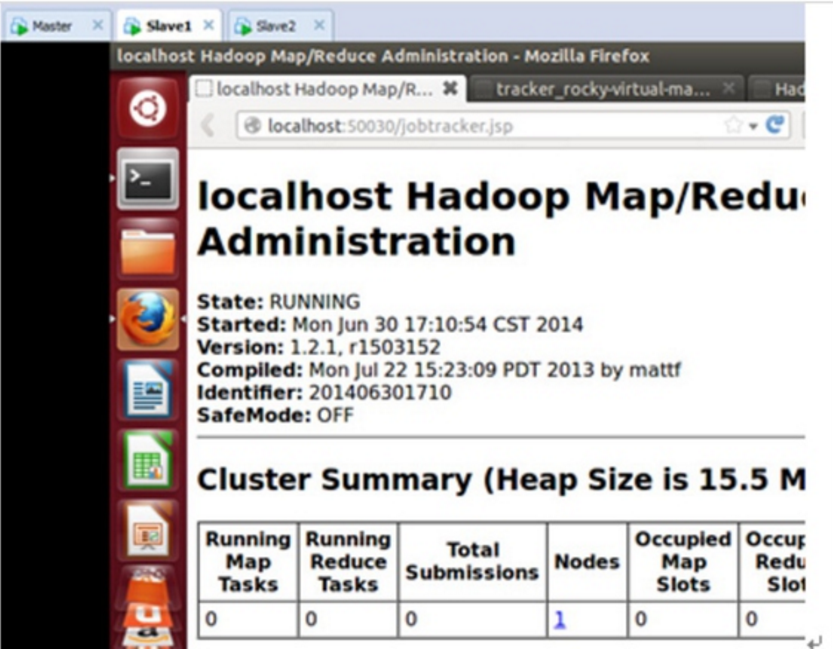
3. 配置Hadoop分布式集群环境;
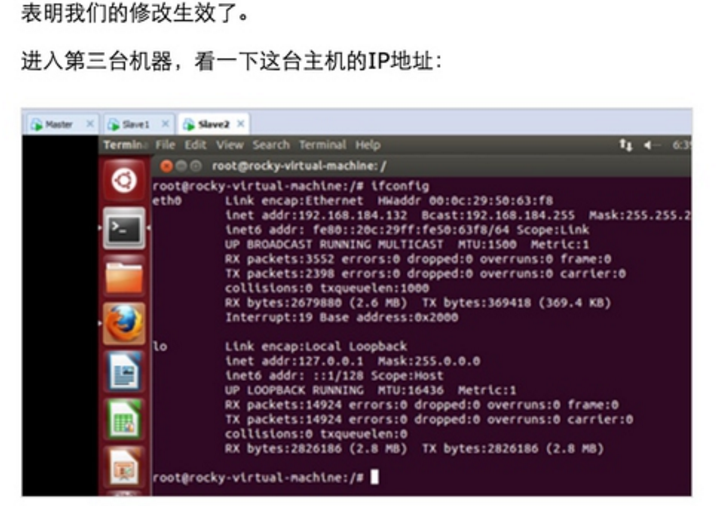
根据前面的配置,我们现在已经有三台运行在VMware中装有Ubuntu系统的机器,分别是:Master、Slave1、Slave2;
下面开始配置Hadoop分布式集群环境:
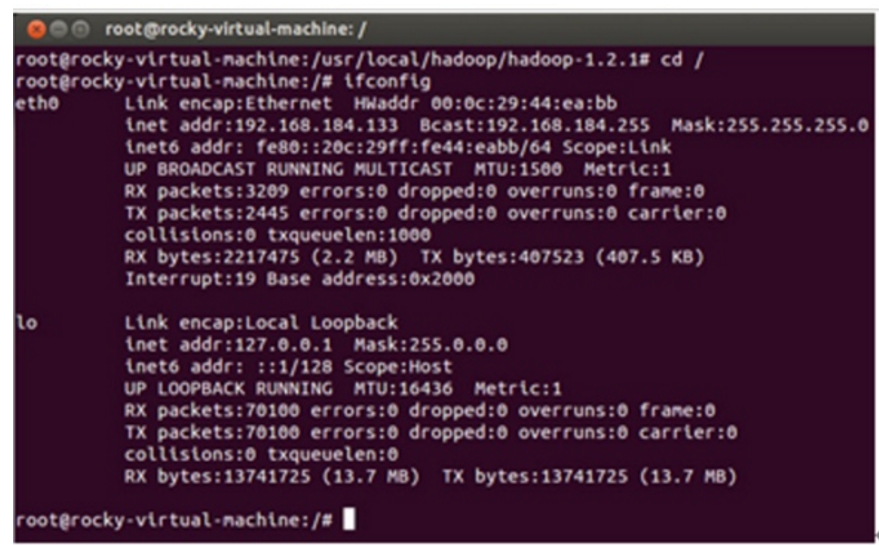
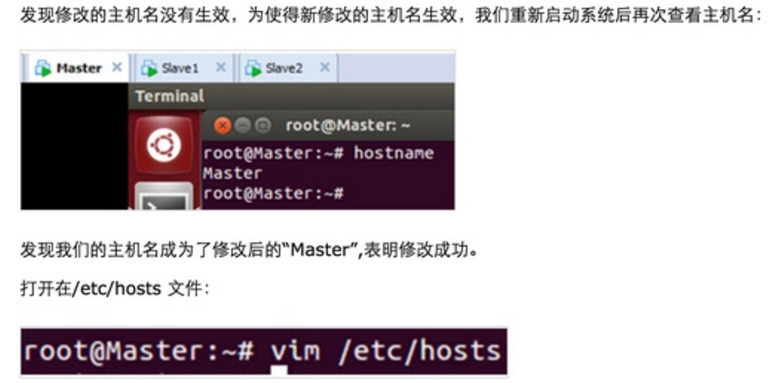
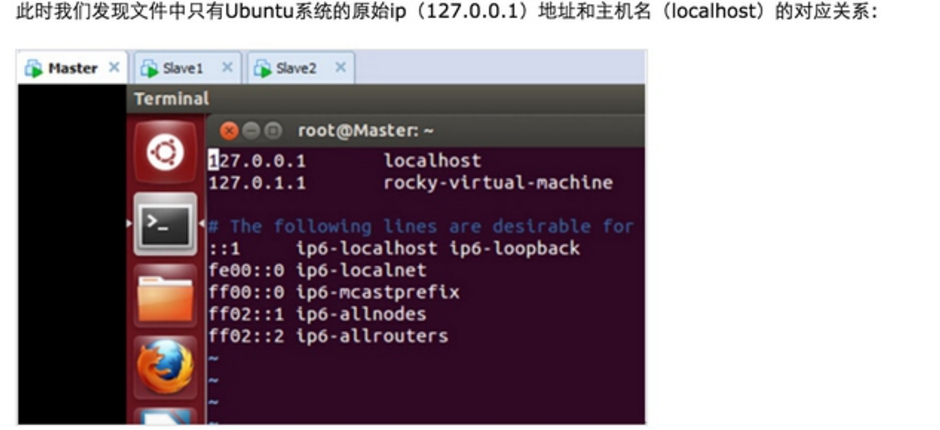
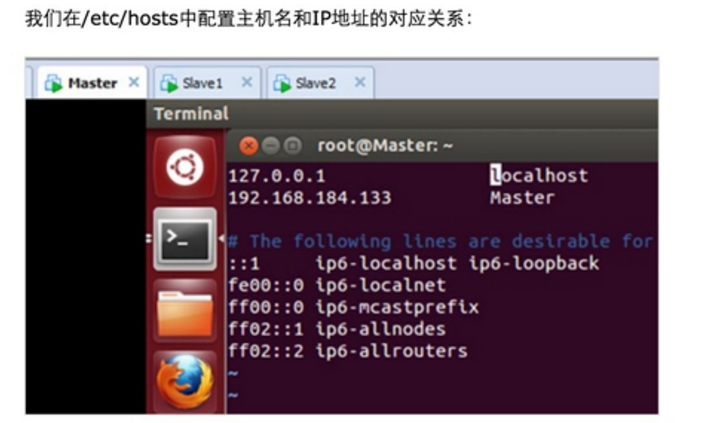
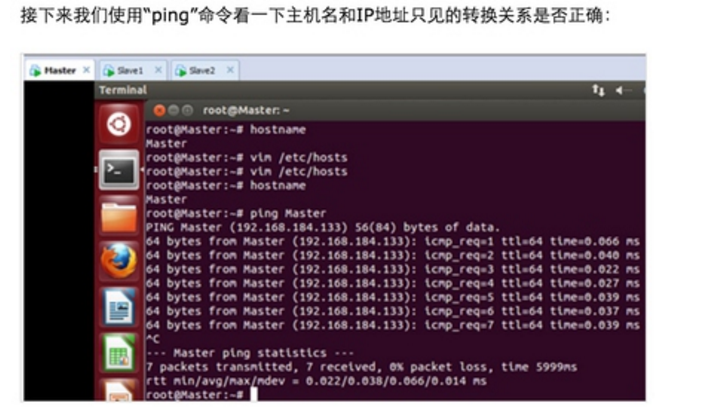
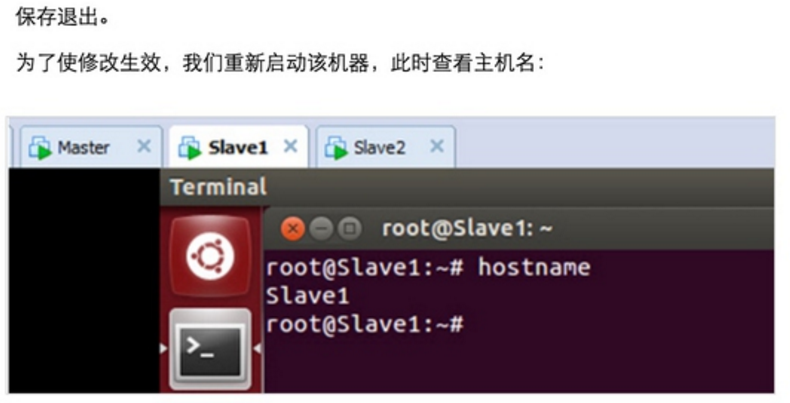
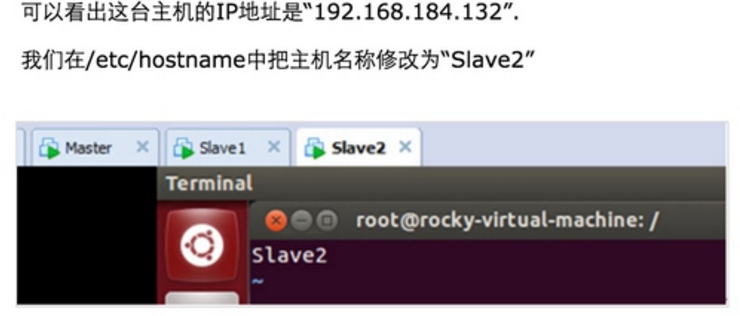
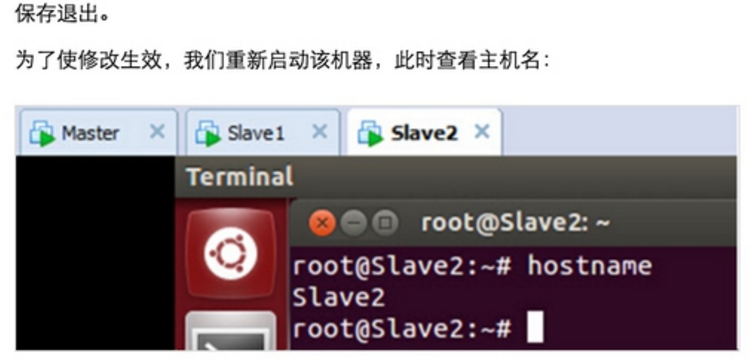
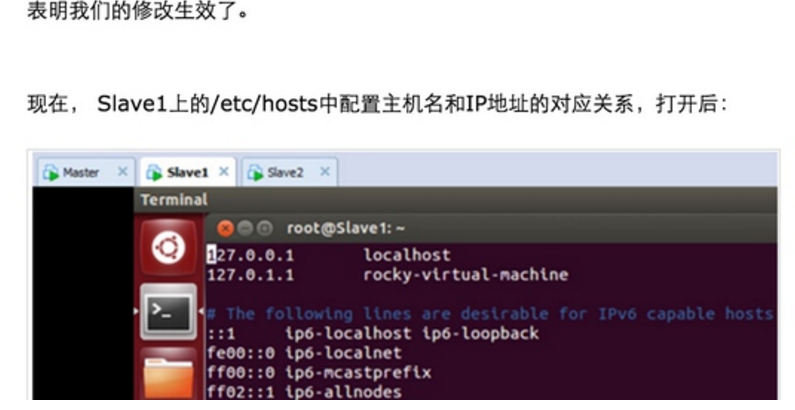
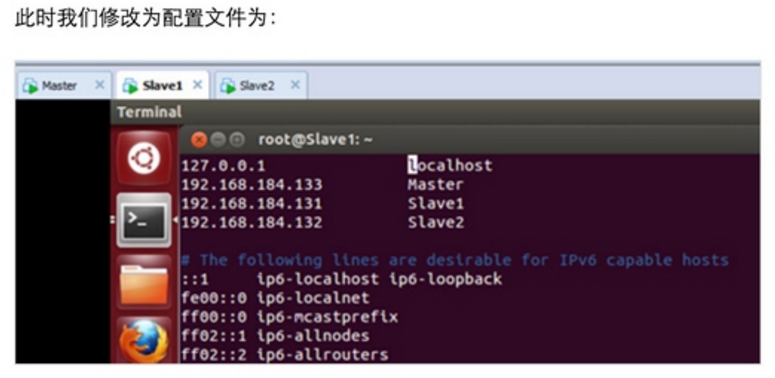
Step 1:在/etc/hostname中修改主机名并在/etc/hosts中配置主机名和IP地址的对应关系:
我们把Master这台机器作为Hadoop的主节点,首先看一下Master这台机器的IP地址:

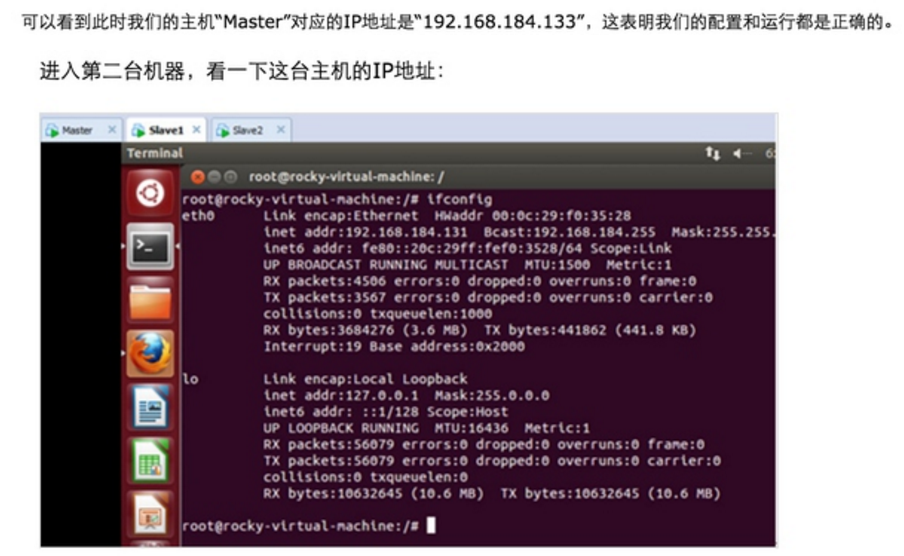
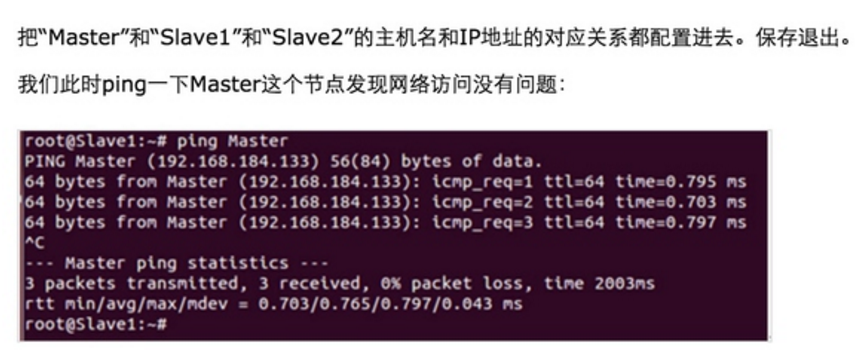
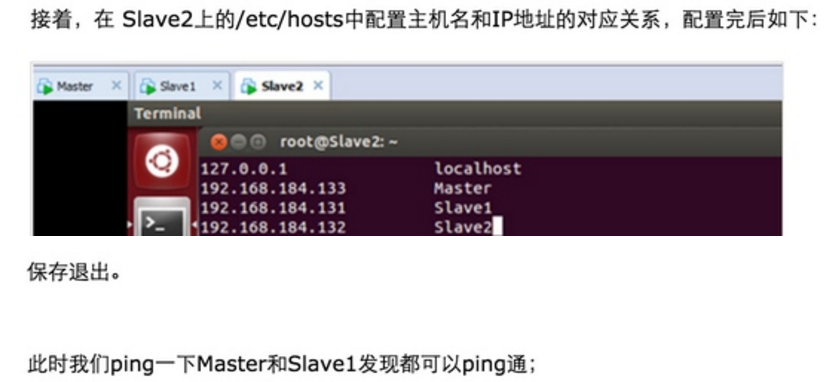
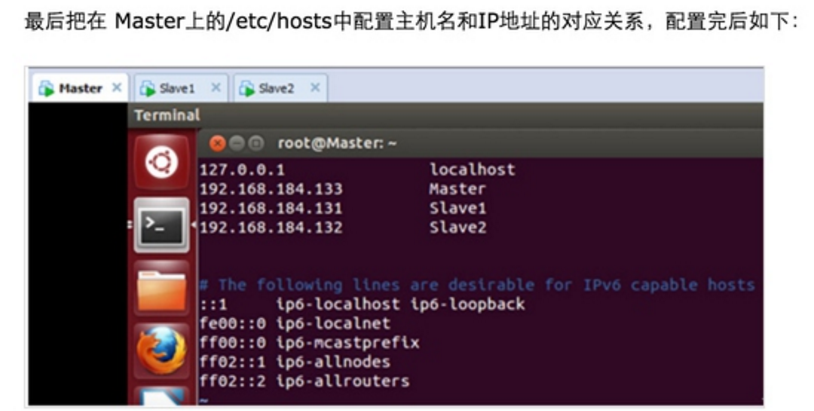
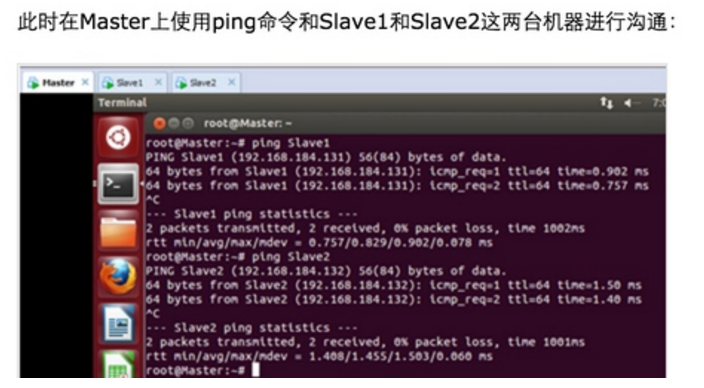
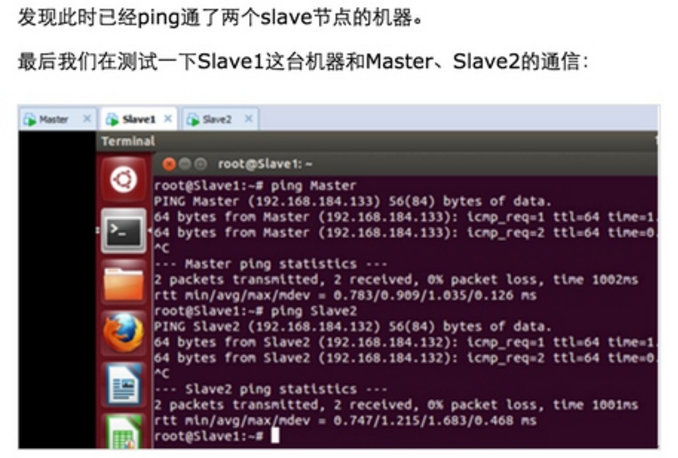
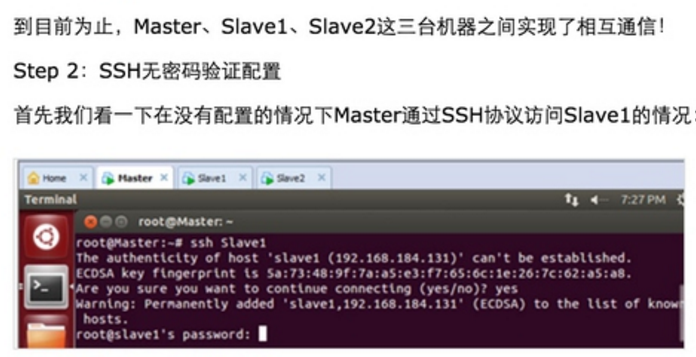
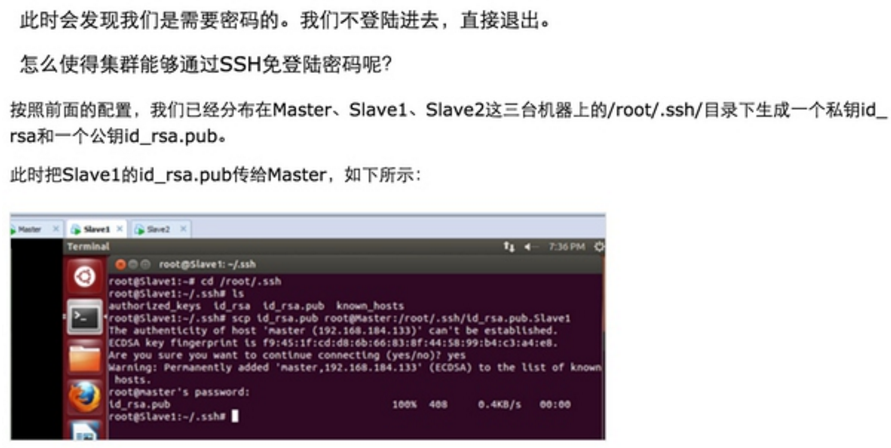
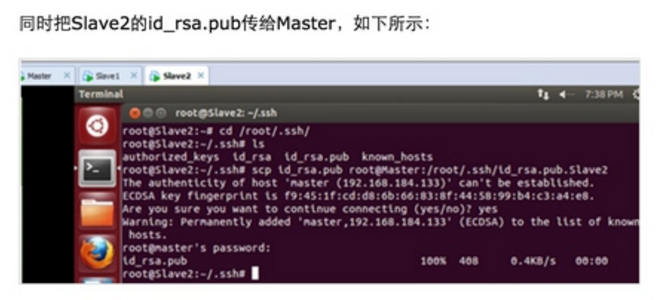
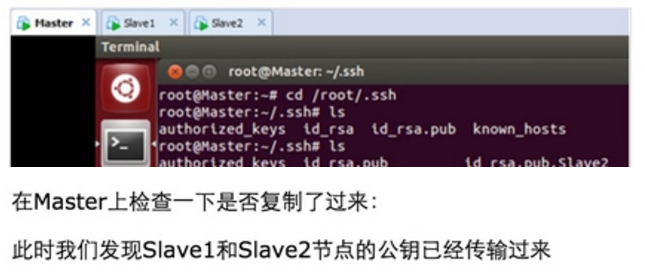
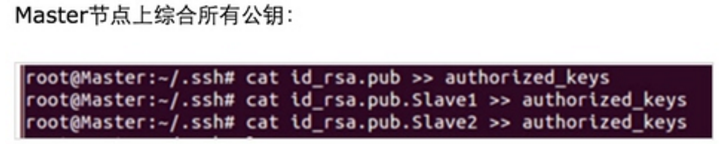
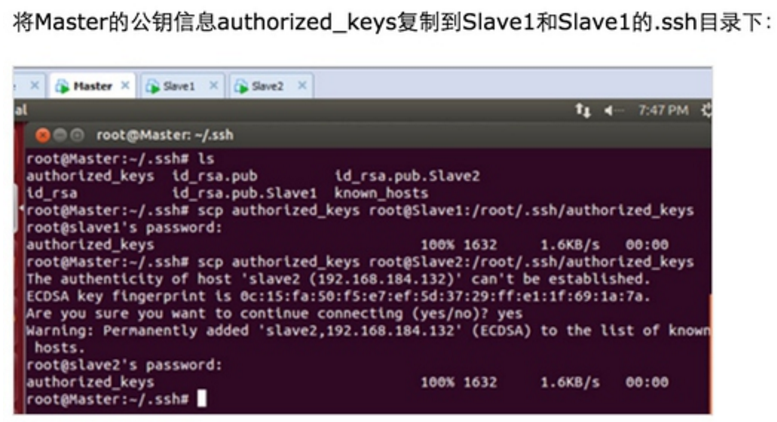
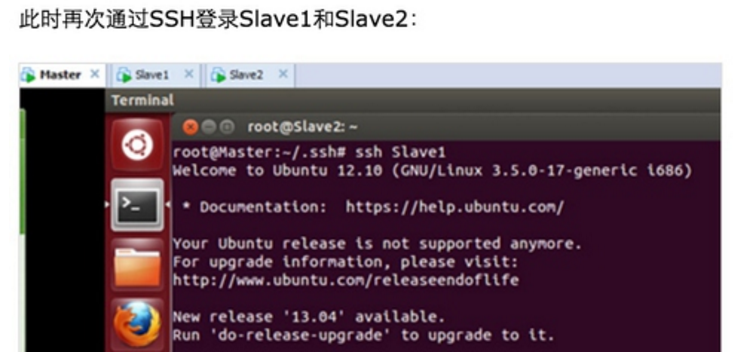
此时Master通过SSH登录Slave1和Slave2已经不需要密码,同样的Slave1或者Slave2通过SSH协议登录另外两台机器也不需要密码了。
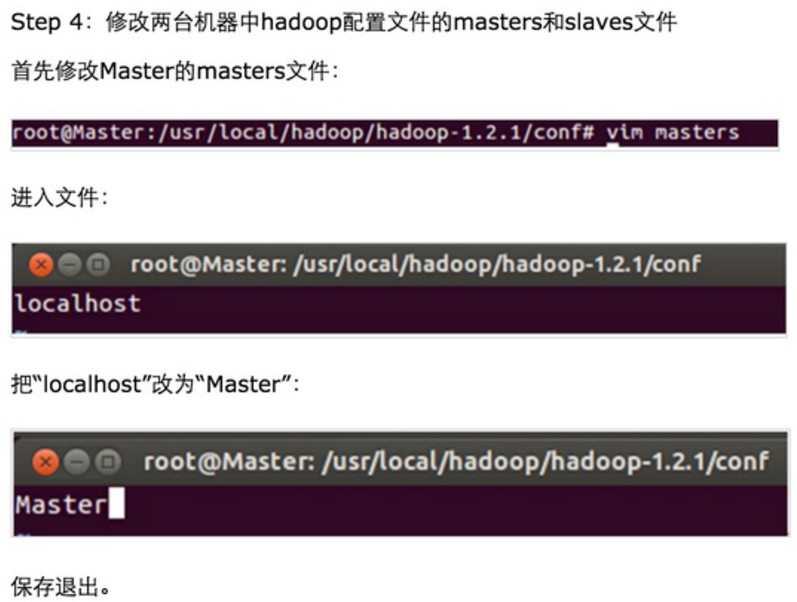
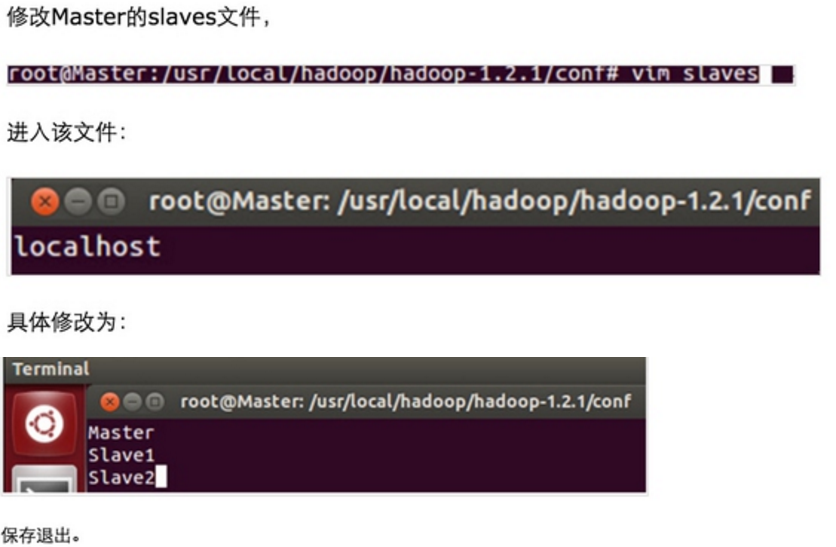
Step 3:修改Master、Slave1、Slave2的配置文件
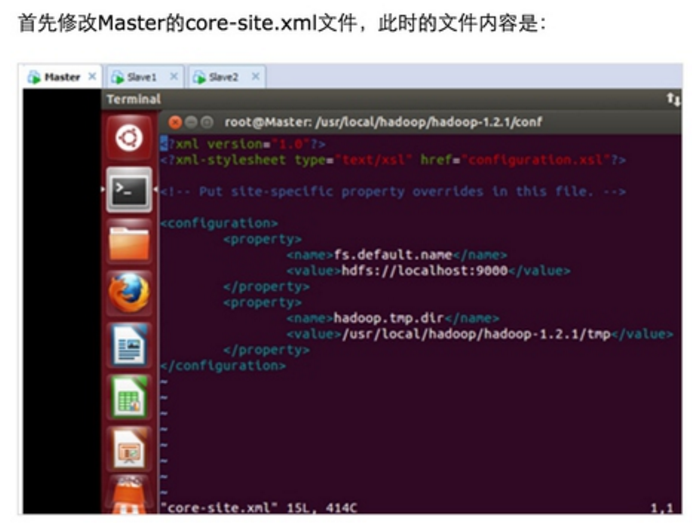
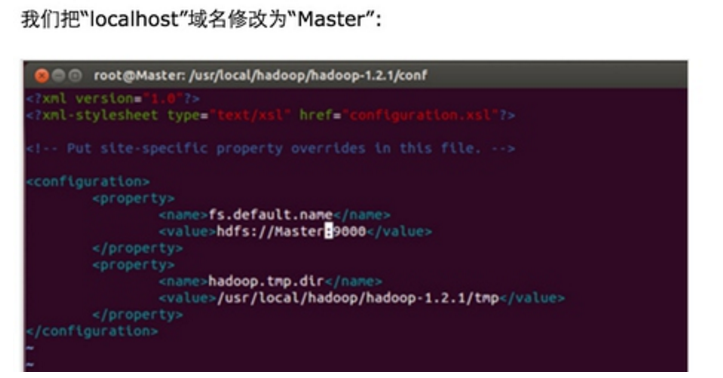
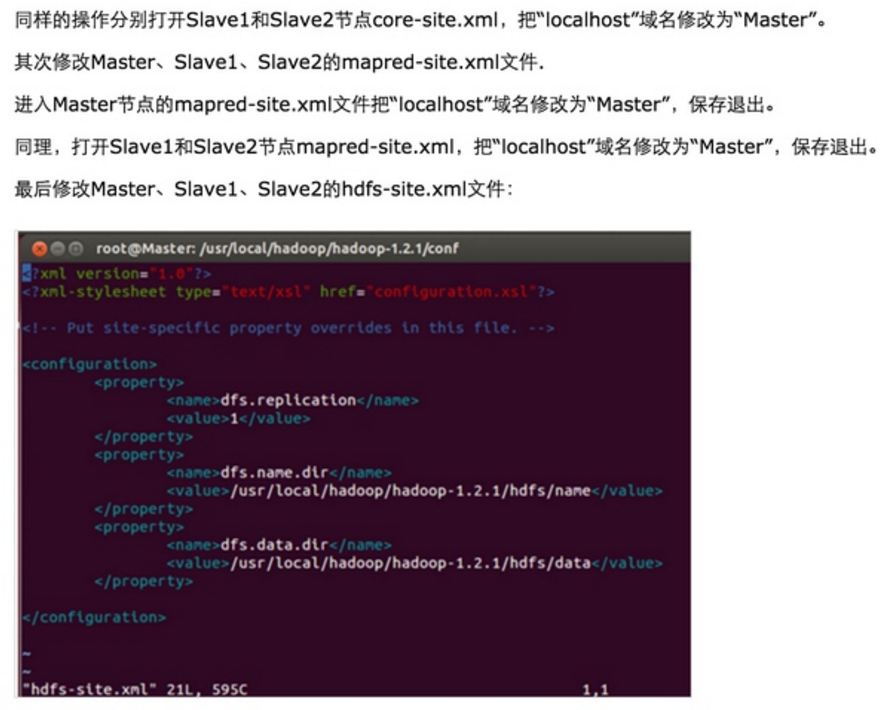
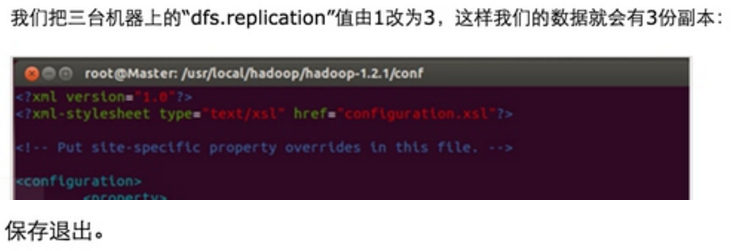
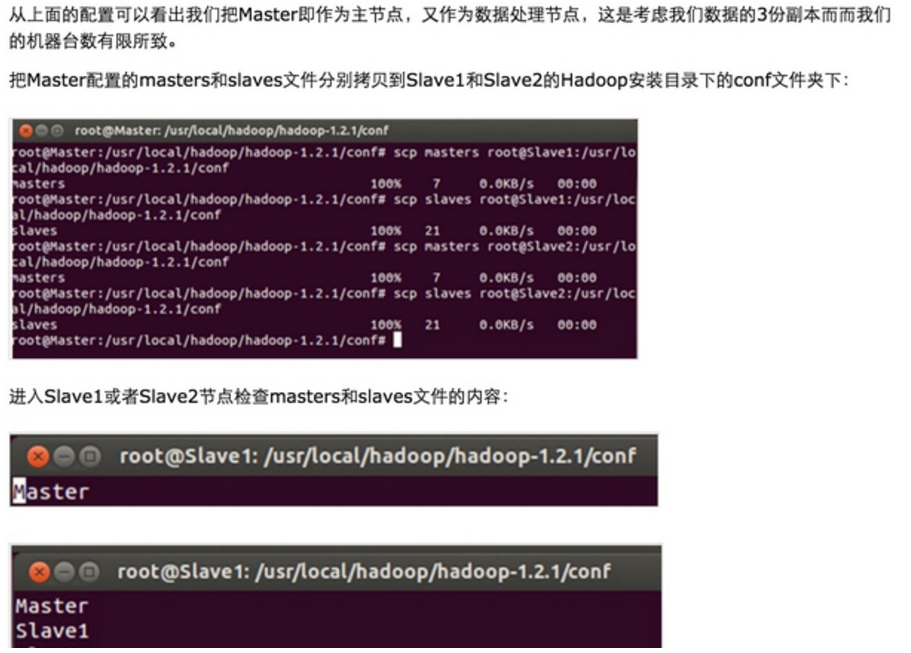
发现拷贝完全正确。
至此Hadoop的集群环境终于配置完成!
4.测试Hadoop分布式集群环境;
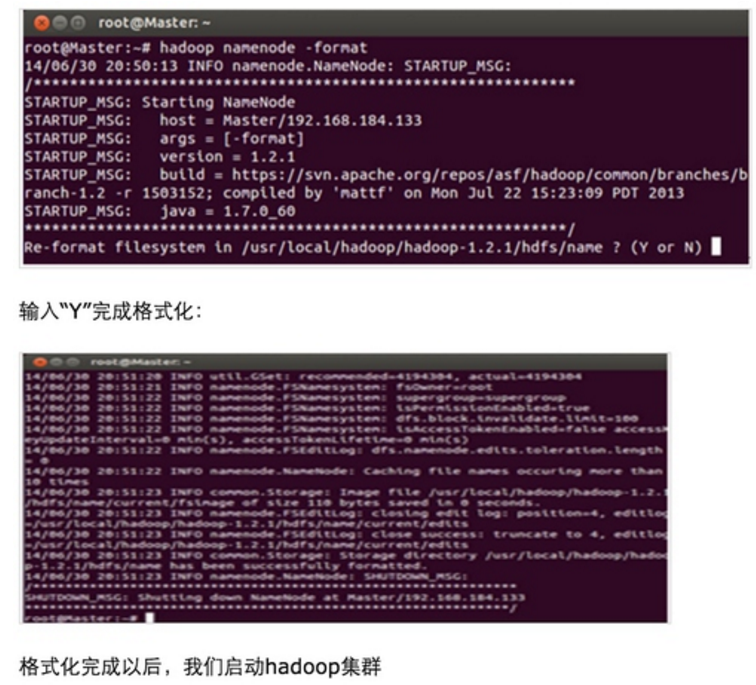
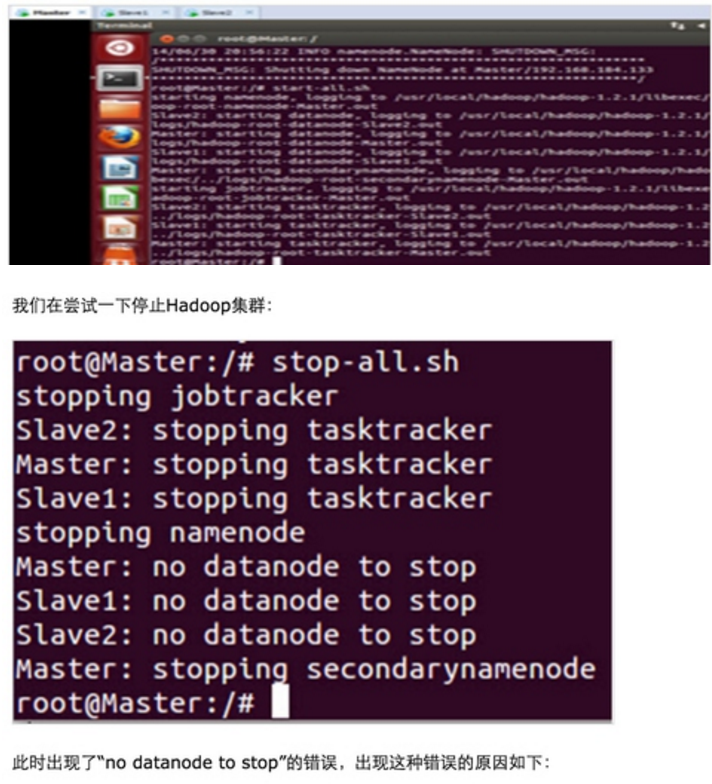
首先在通过Master节点格式化集群的文件系统
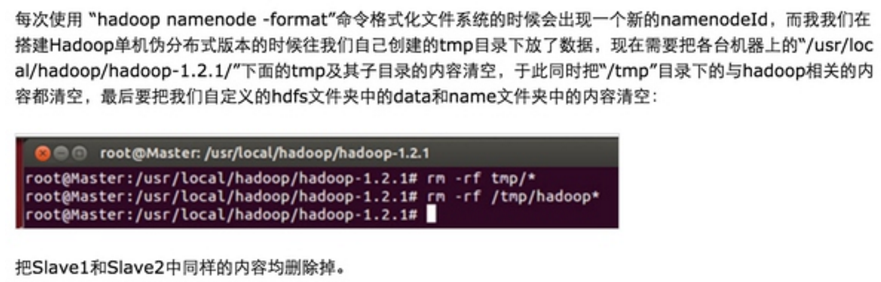
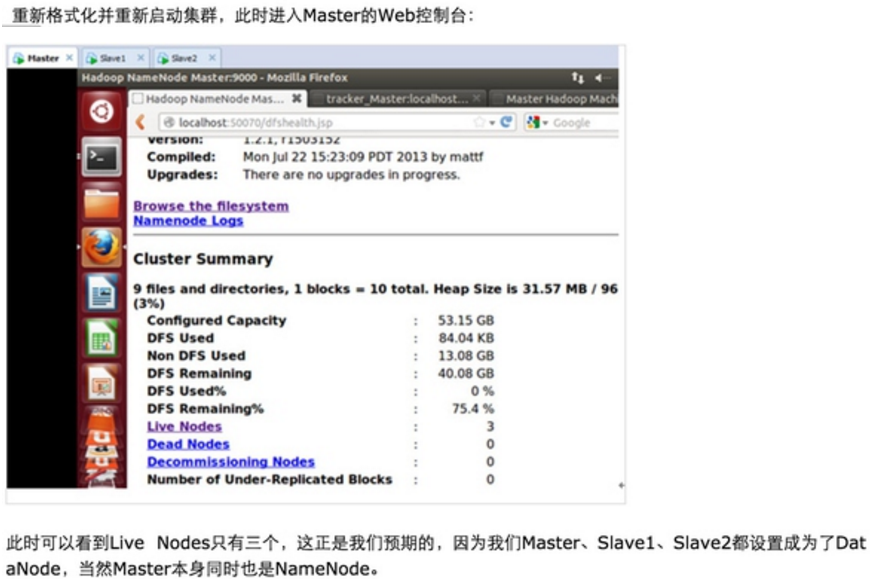
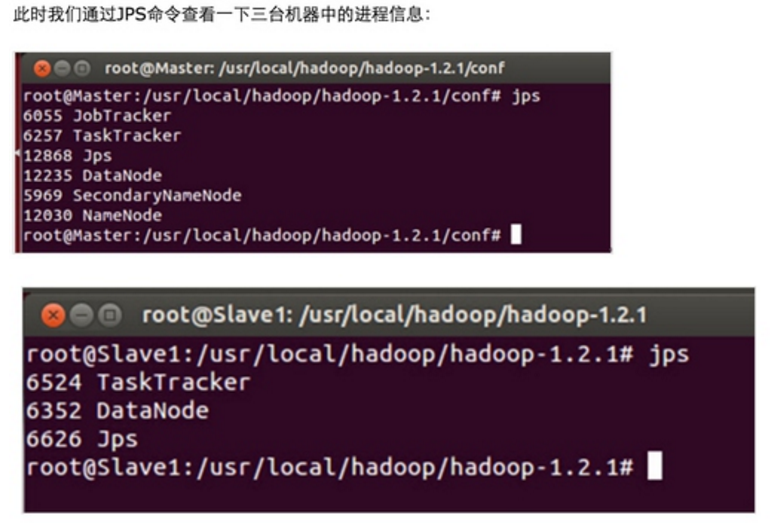

第一步:Spark集群需要的软件;
在1、2讲的从零起步构建好的Hadoop集群的基础上构建Spark集群,我们这里采用2014年5月30日发布的Spark 1.0.0版本,也就是Spark的最新版本,要想基于Spark 1.0.0构建Spark集群,需要的软件如下:
1.Spark 1.0.0,笔者这里使用的是spark-1.0.0-bin-hadoop1.tgz, 具体的下载地址是http://d3kbcqa49mib13.cloudfront.net/spark-1.0.0-bin-hadoop1.tgz
如下图所示:
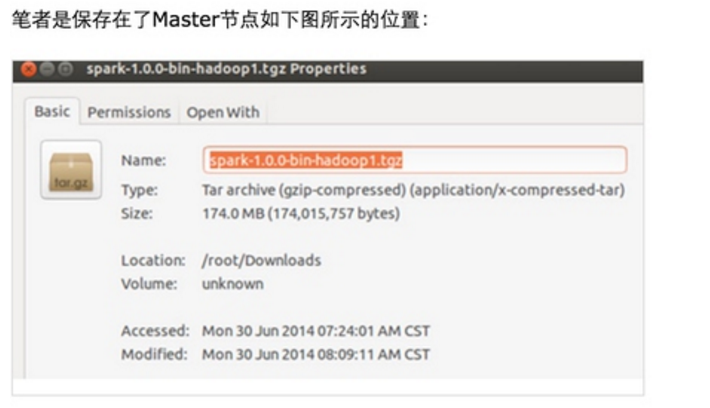
2.下载和Spark 1.0.0对应的Scala版本,官方要求的是Scala必须为Scala 2.10.x:
笔者下载的是“Scala 2.10.4”,具体官方下载地址为Scala 2.10.4 下载后在Master节点上保存为:
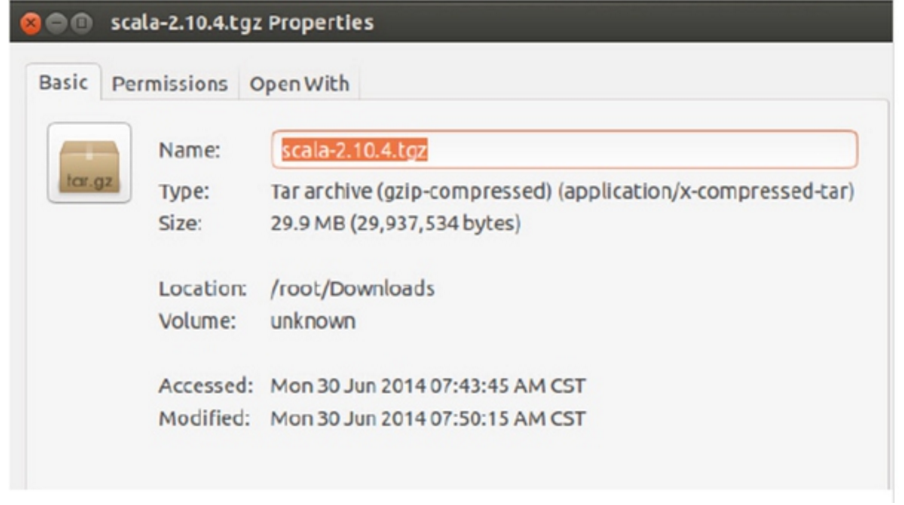
第二步:安装每个软件
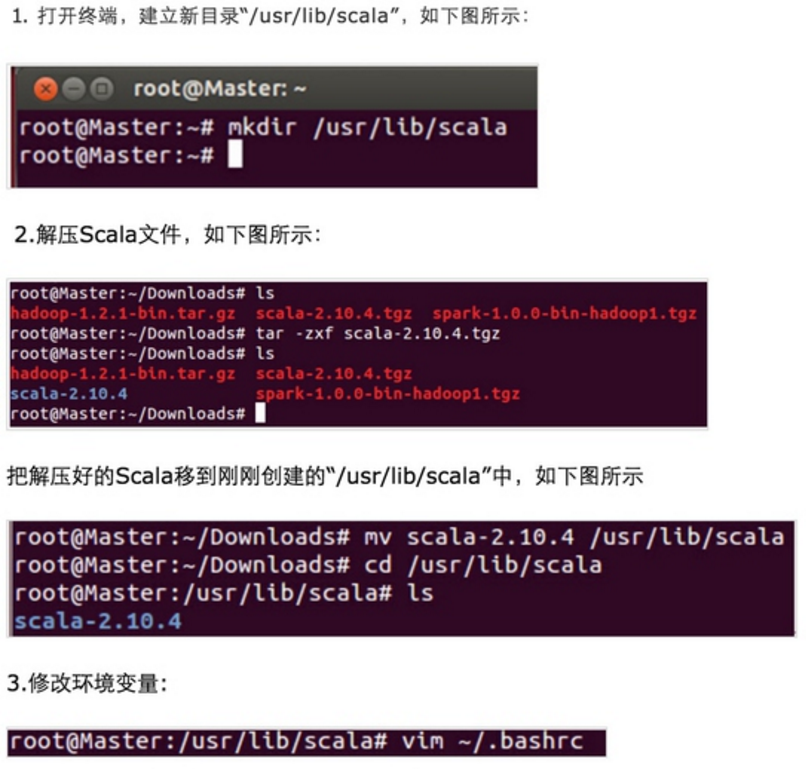
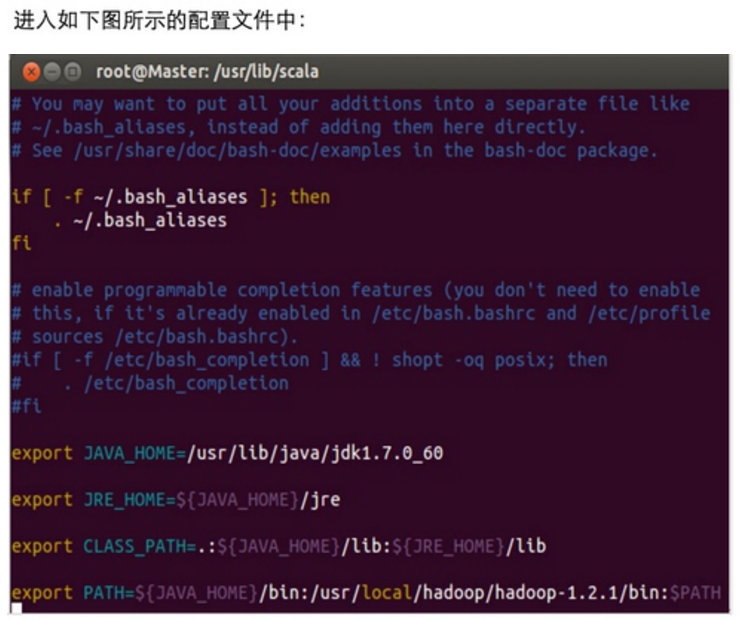
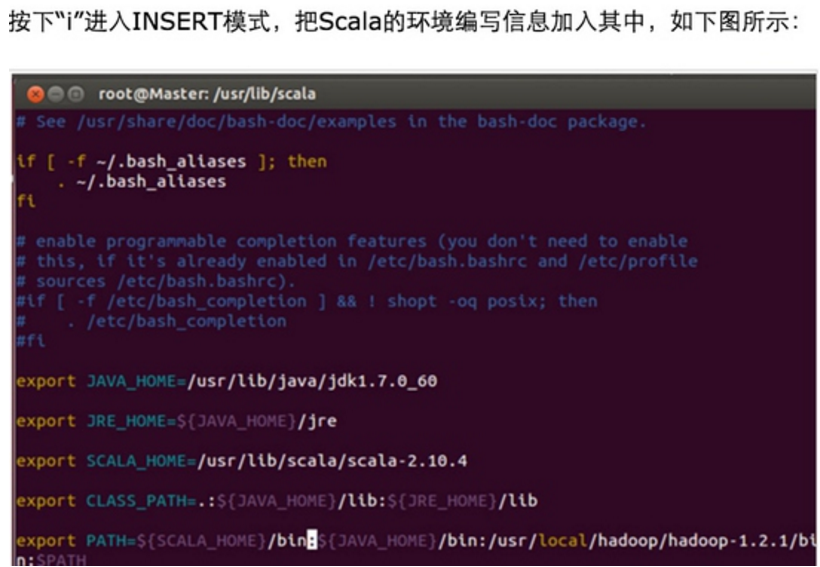
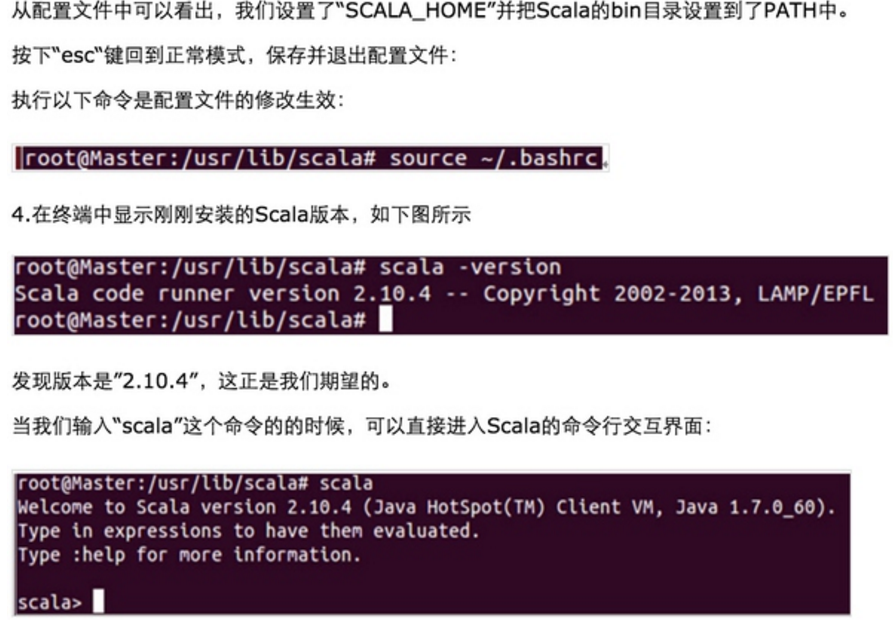
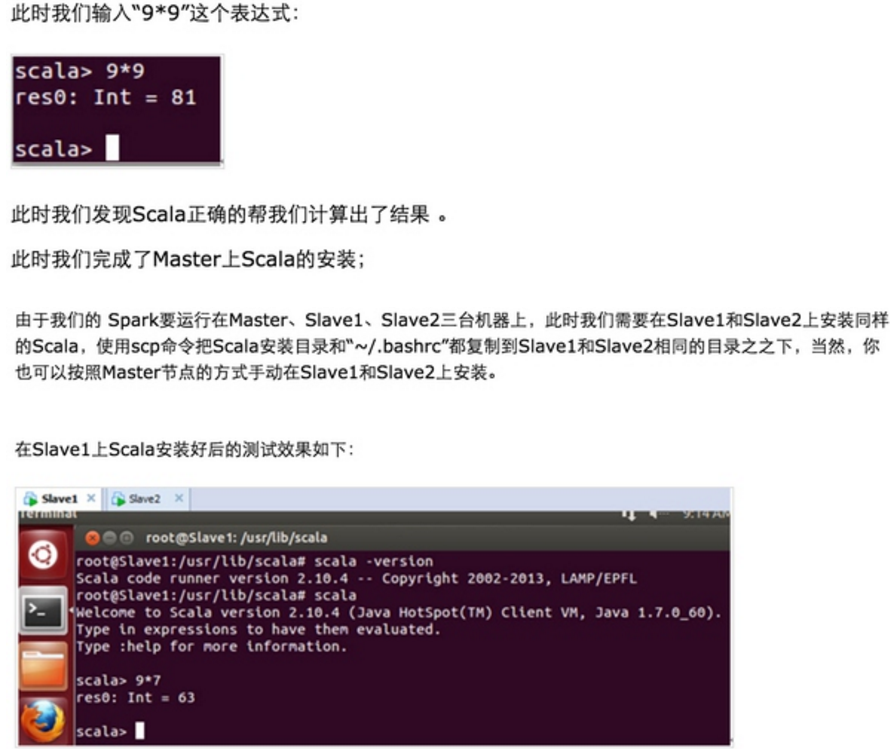
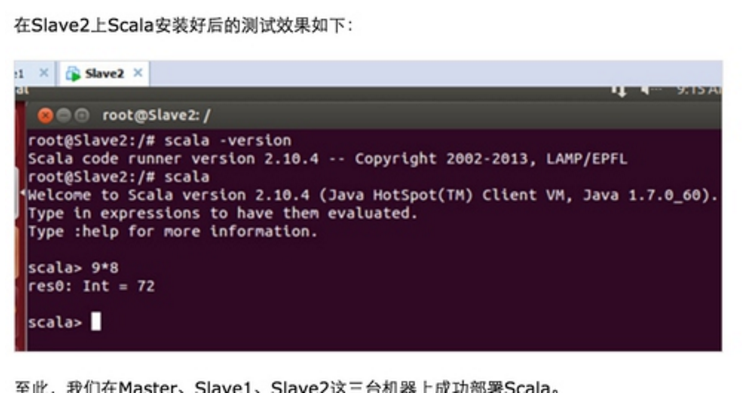
安装Spark
Master、Slave1、Slave2这三台机器上均需要安装Spark。
首先在Master上安装Spark,具体步骤如下:
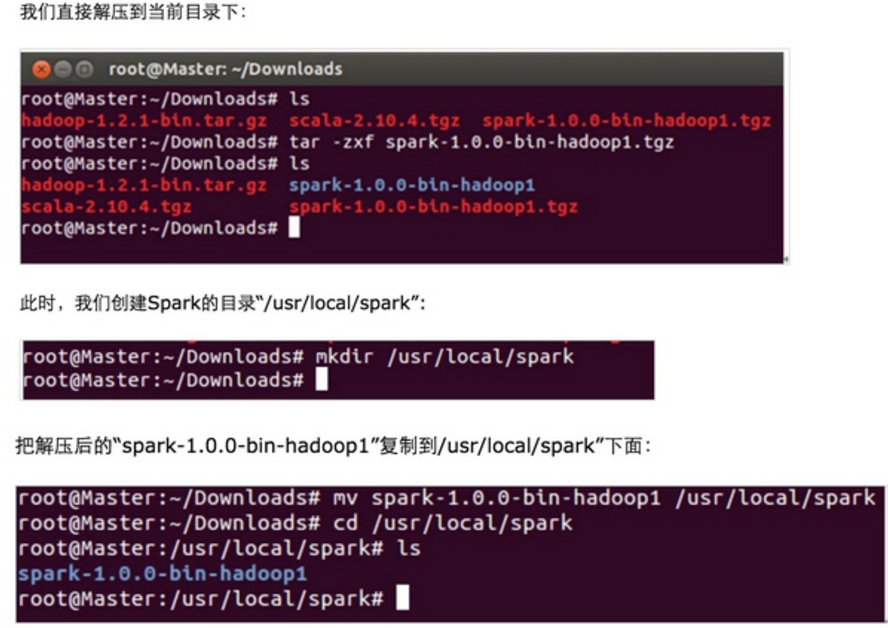
第一步:把Master上的Spark解压:
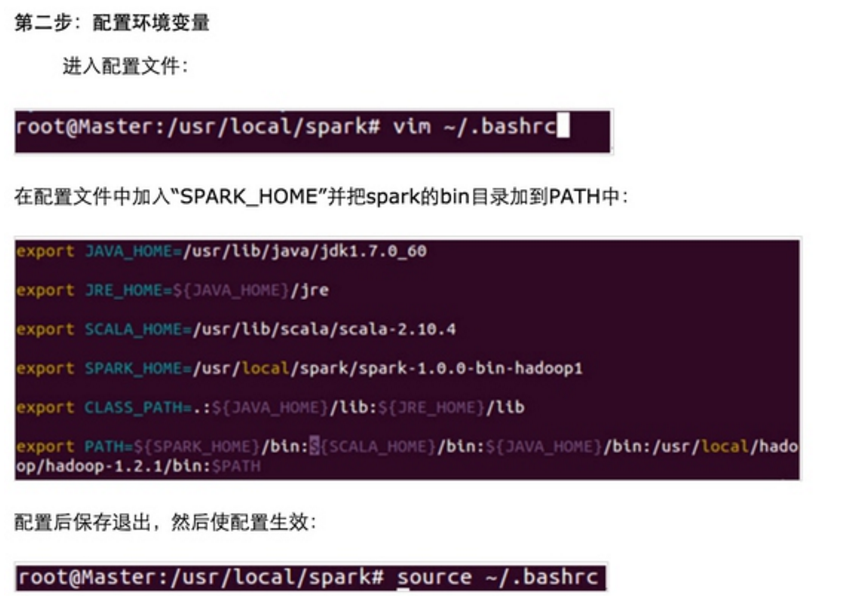
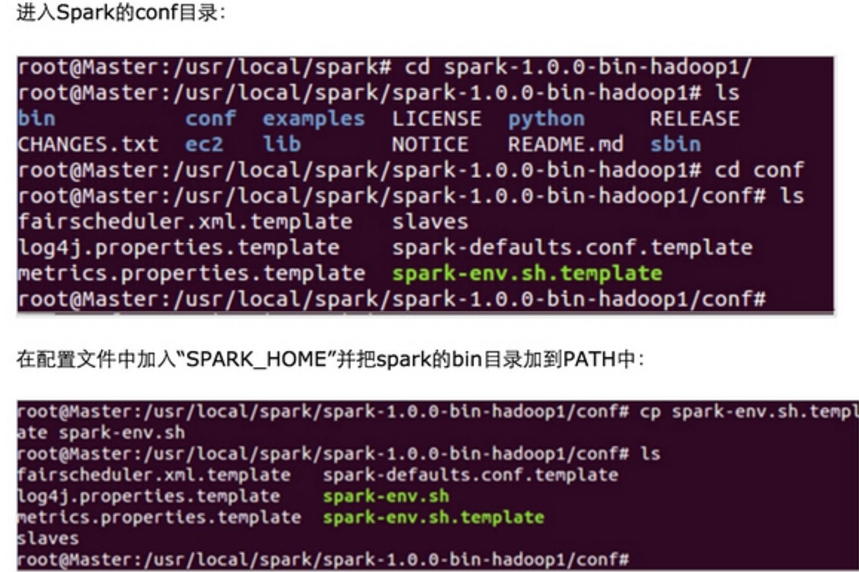
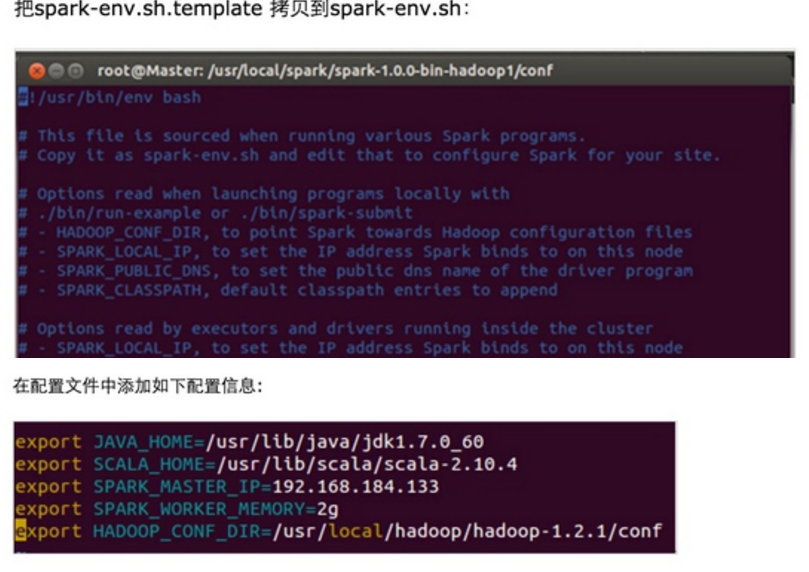
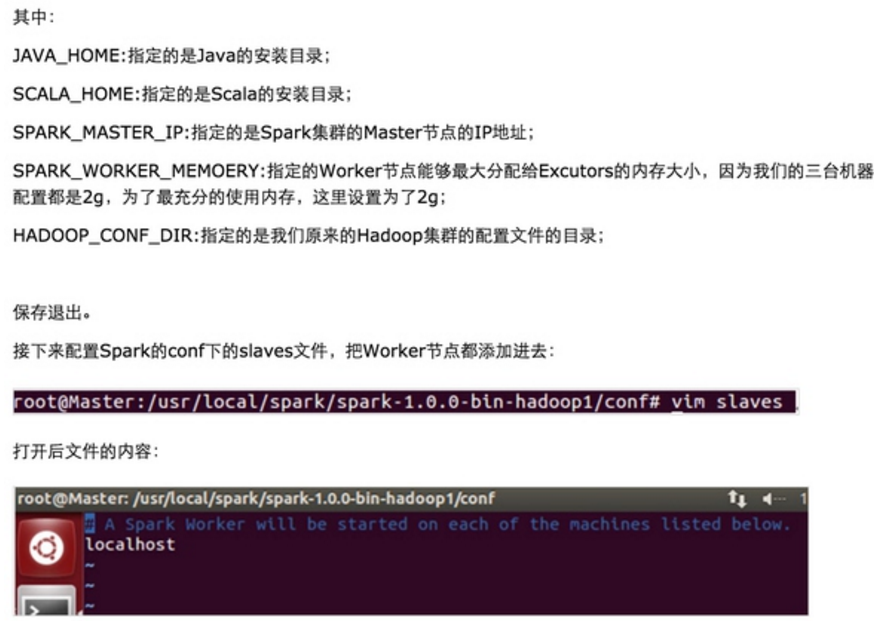
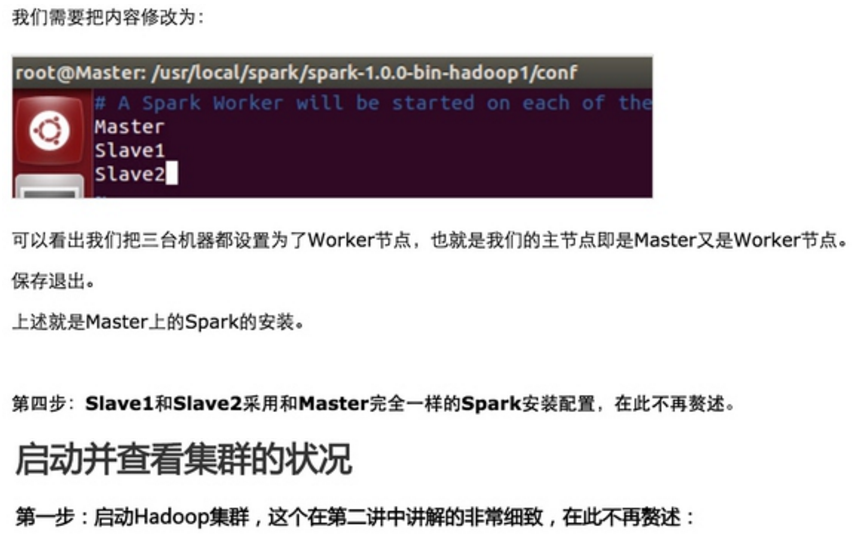
第三步:配置Spark
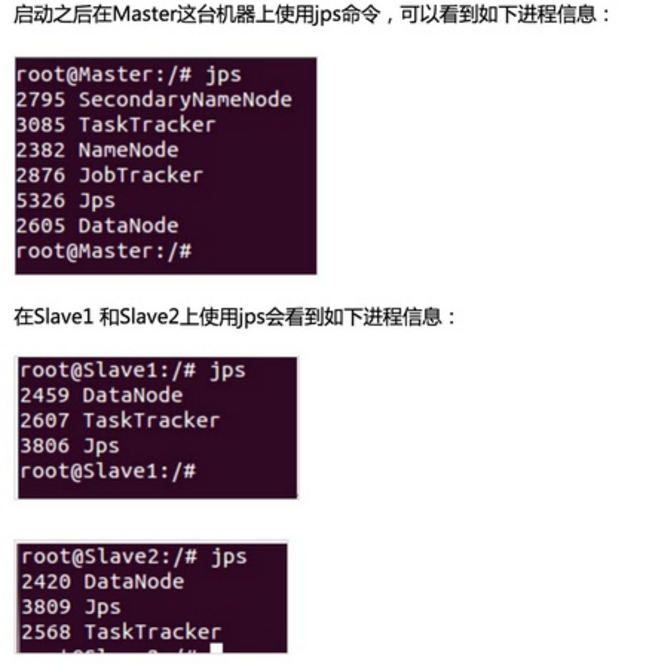
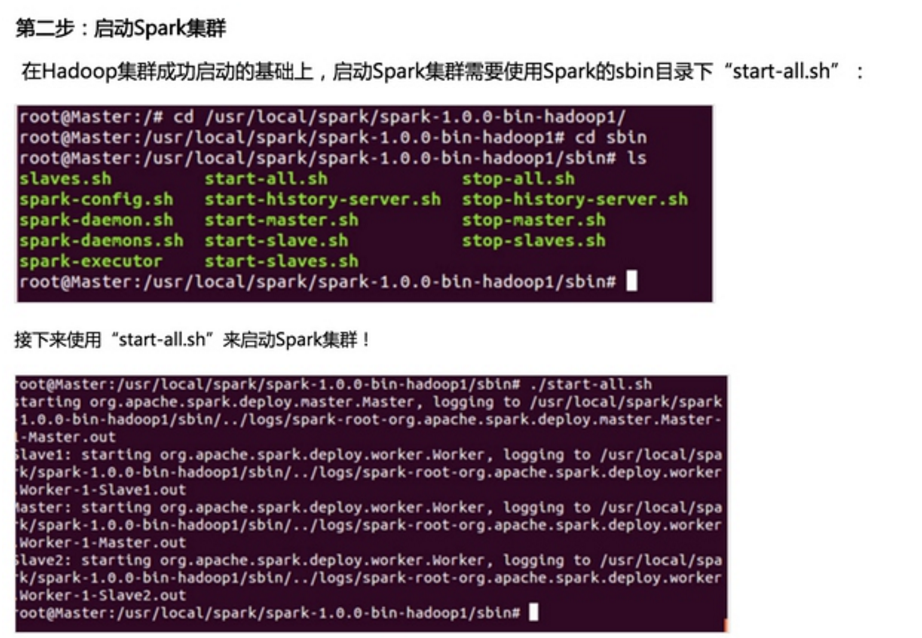
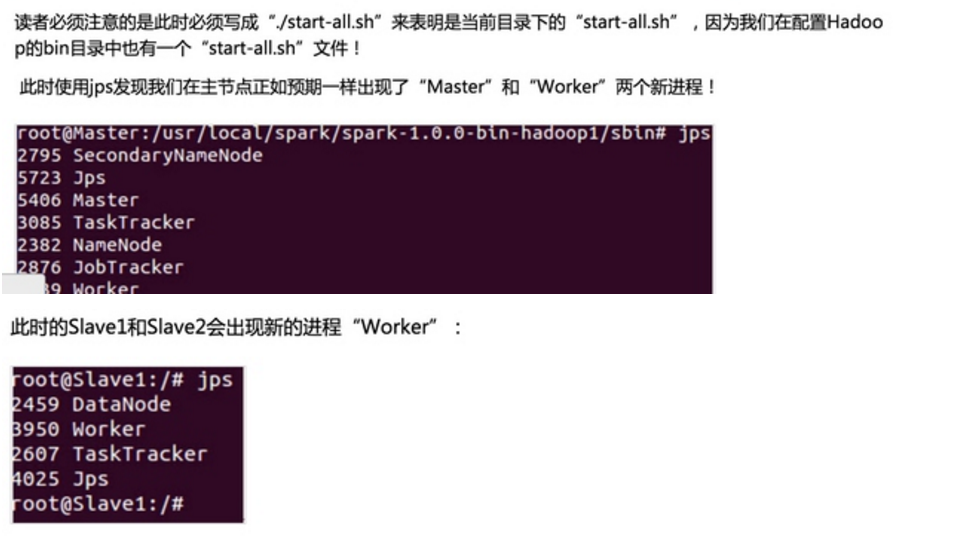

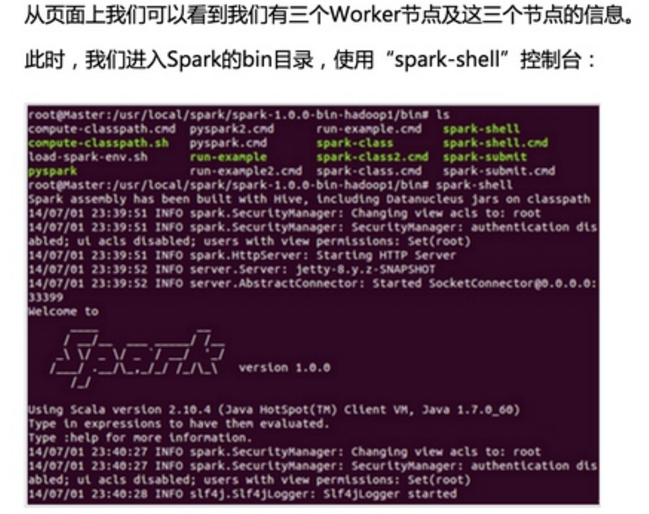
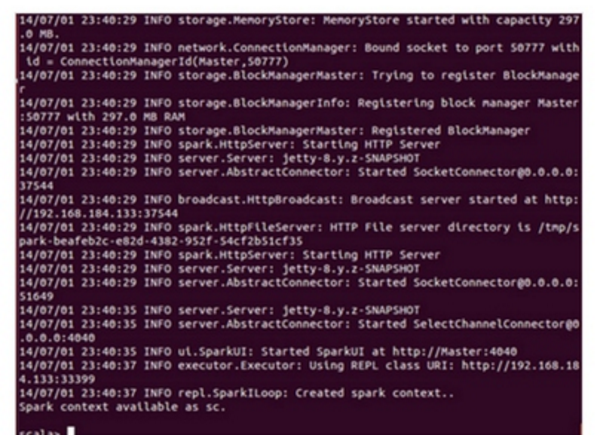
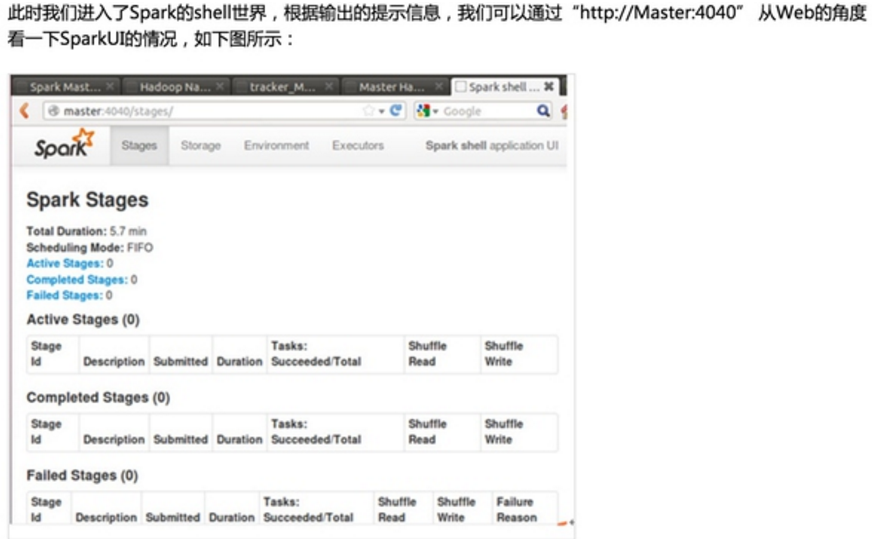
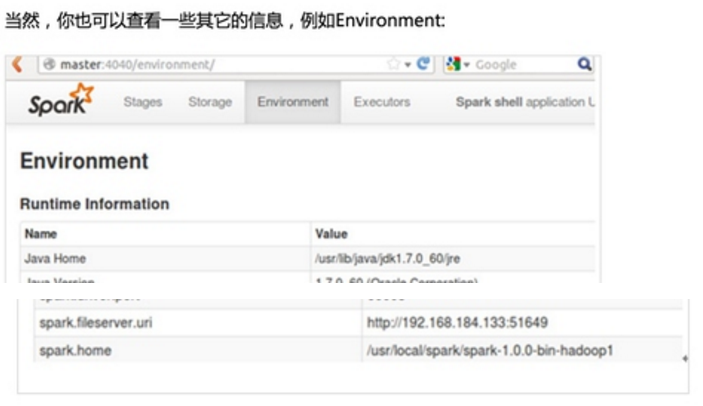
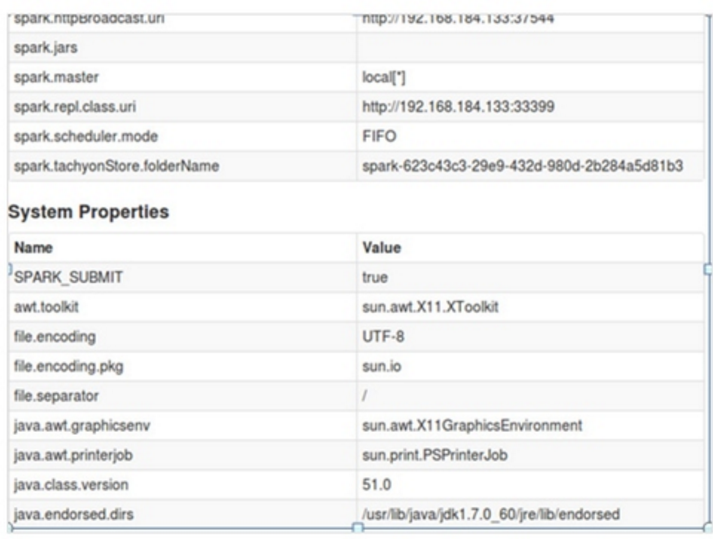
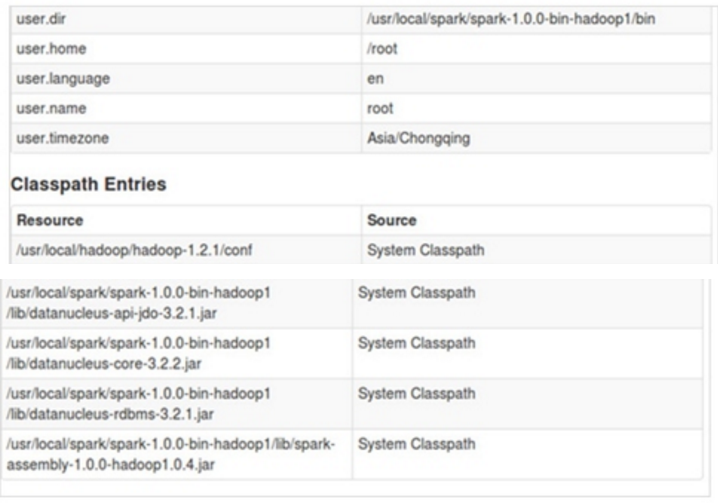
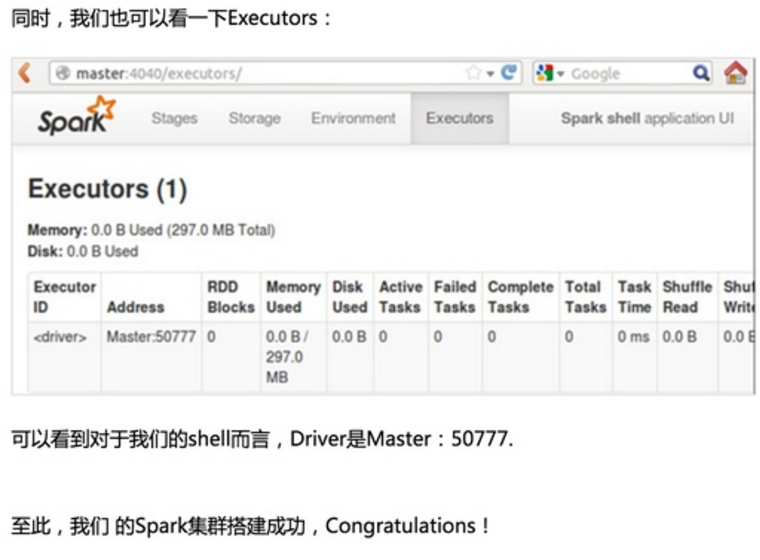
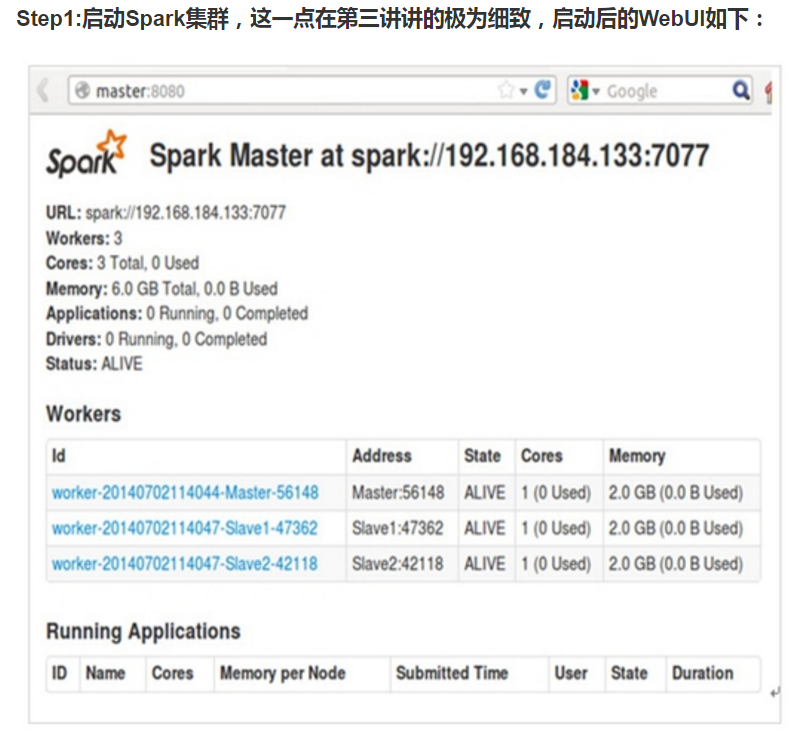
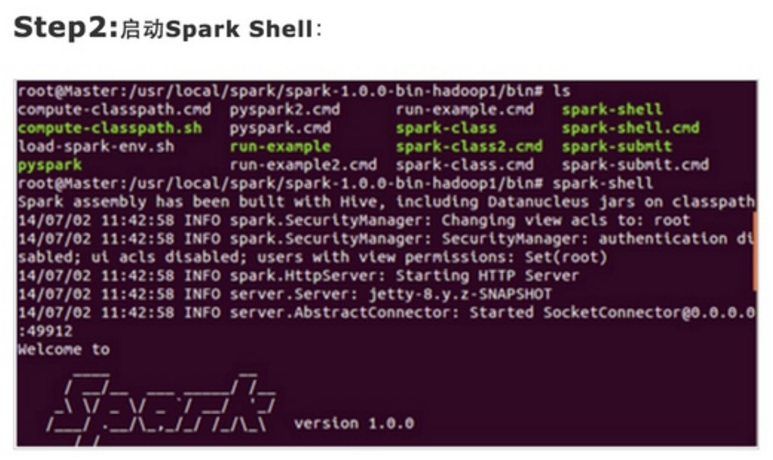
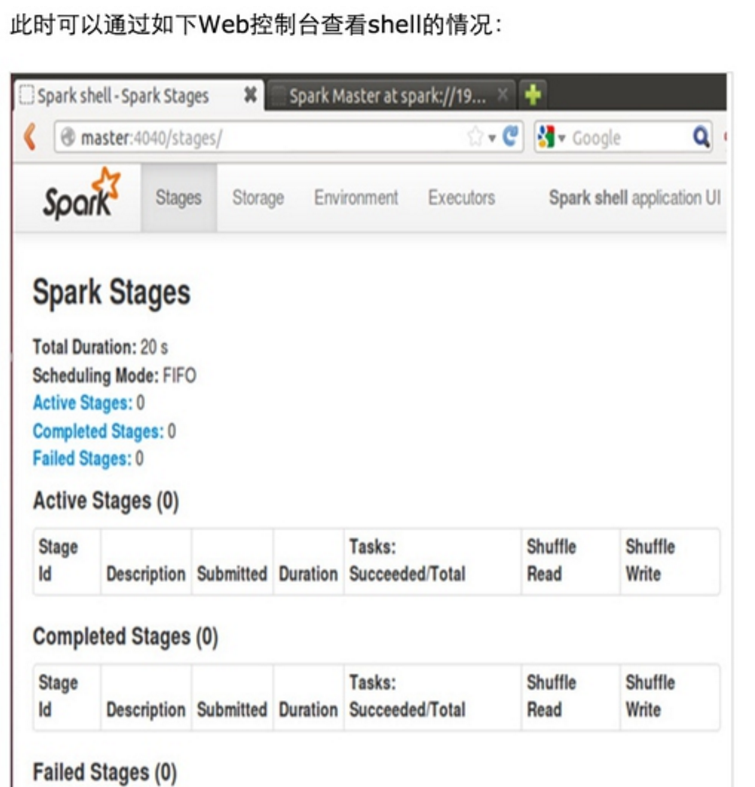
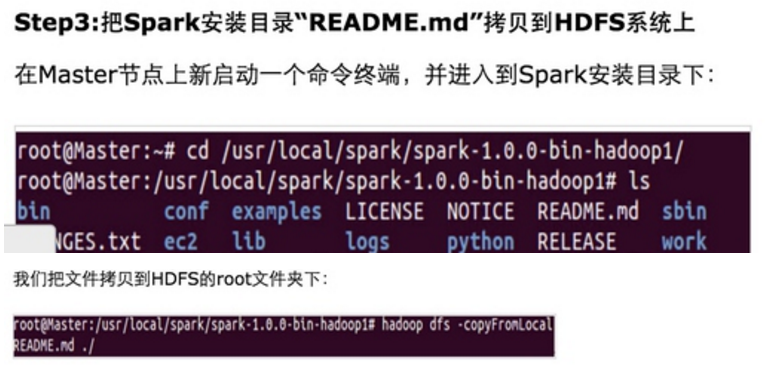
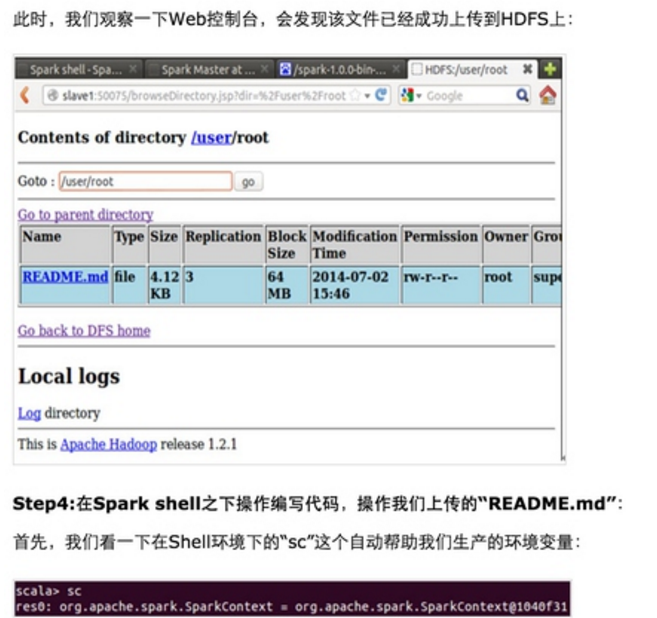
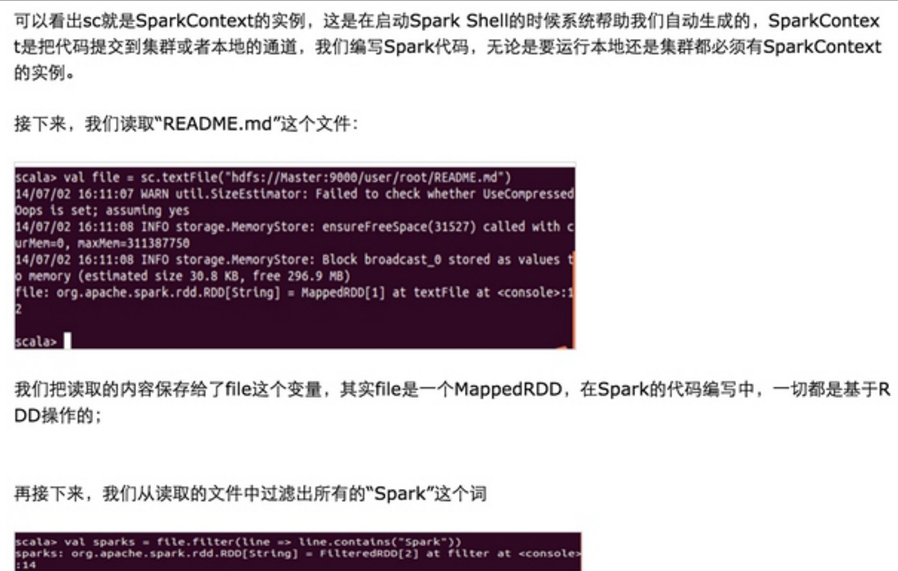
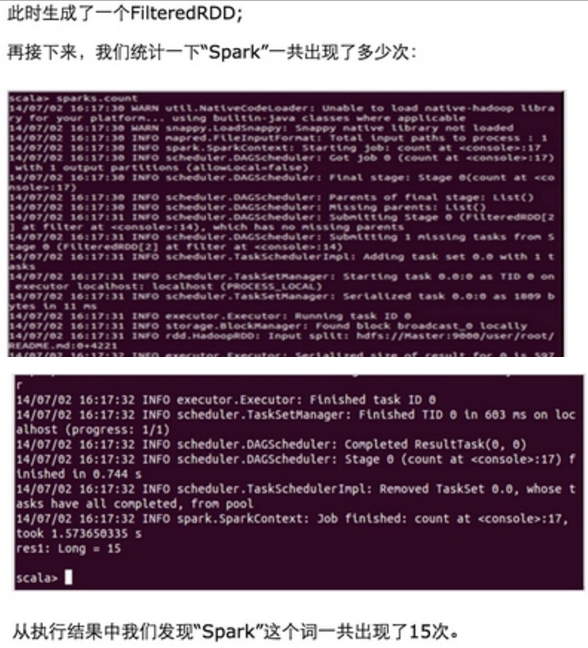
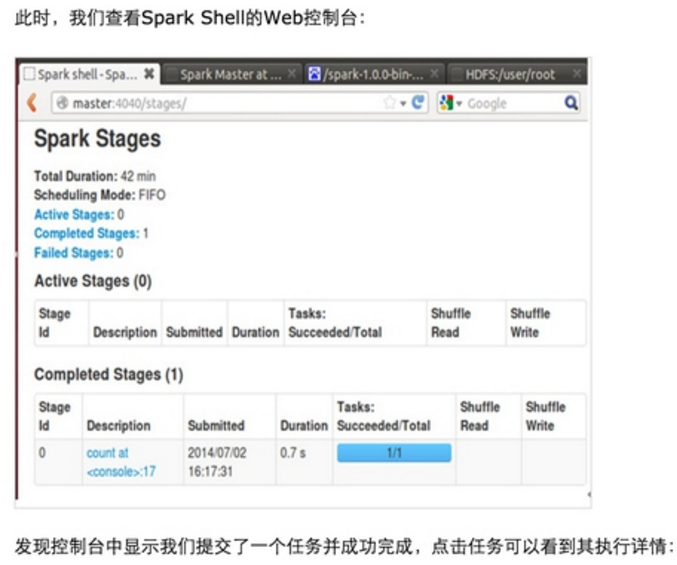
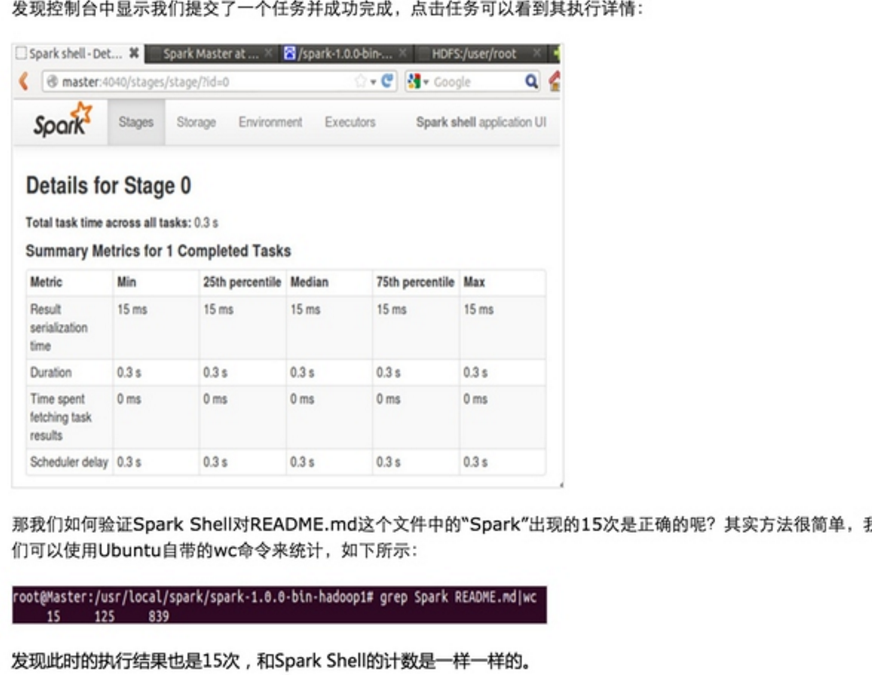
第一步:通过Spark的shell测试Spark的工作
http://my.oschina.net/u/1791057/blog/316982
http://my.oschina.net/u/1791057/blog/317266
http://my.oschina.net/u/1791057/blog/317802
http://my.oschina.net/u/1791057/blog/318518
http://my.oschina.net/u/1791057/blog/318910
http://my.oschina.net/u/1791057/blog/324877
http://my.oschina.net/u/1791057/blog/325351
http://my.oschina.net/u/1791057/blog/325587
http://my.oschina.net/u/1791057/blog/332848
http://my.oschina.net/u/1791057/blog/335626
http://my.oschina.net/u/1791057/blog/343854
http://my.oschina.net/u/1791057/blog/344141
http://my.oschina.net/u/1791057/blog/344777
http://my.oschina.net/u/1791057/blog/345662
http://my.oschina.net/u/1791057/blog/345665
http://my.oschina.net/u/1791057/blog/346128
http://my.oschina.net/u/1791057/blog/346277
http://my.oschina.net/u/1791057/blog/346687
具体的安装步骤自己有空看看,就不多BB了。