阔别了周末之后又要开始一周的工作,争取在本周内将此篇的SAS数据挖掘实战篇介绍完。从数据挖掘概念到SAS EM模块和大概的流程介绍完之后,下面的规划是【SAS关联规则案例】【SAS聚类】【SAS预测】三个案例的具体操作步骤,【SAS的可视化技术】和【SAS的一些技巧和代码】,至于像SAS的数据导入导出数据处理等一些基本的代码,不作大的讲解。到时候会穿插在每周日常里进行介绍,只有多操作才能熟练。
贵在平时实践和坚持!
OK,废话不多说,今天主要写这篇“SAS数据挖掘实战篇【三】”主要介绍,SAS的关联规则应用数据挖掘。
1 关联规则
1.1起源
关联规则虽然来源于POS中,但是可以应用于很多领域。关联规则的应用还包括商场的顾客购物分析、商品广告邮寄分析、网络故障分析等。沃尔玛零售商的“尿布与啤酒”的故事是关联规则挖掘的一个成功典型案例。总部位于美国阿肯色州的Wal*Mart拥有世界上最大的数据仓库系统,它利用数据挖掘工具对数据仓库中的原始交易数据进行分析,得到了一个意外发现:跟尿布一起购买最多的商品竟然是啤酒。如果不是借助于数据仓库和数据挖掘,商家决不可能发现这个隐藏在背后的事实:在美国,一些年轻的父亲下班后经常要到超市去买婴儿尿布,而他们中有30%~40%的人同时也为自己买一些啤酒。有了这个发现后,超市调整了货架的摆放,把尿布和啤酒放在一起,明显增加了销售额。
1.2基本思想
关联规则挖掘技术可以发现不同商品在消费者购买过程中的相关性。给定一组事务集合,其中每个事务是一个项目集;一个关联规则是形如X ->Y 的蕴涵式, X 和Y 表示项目集,且X ∩ Y = Φ, X 和Y 分别称为关联规则X-> Y 的前提和结论。规则X->Y 的支持度(Support) 是事务集中包含X 和Y 的事务数与所有事务数之比,记为support(X->Y) ;规则X->Y 的置信度(Confidence) 是指包含X和Y 的事务数与包含X 的事务数之比, 记为confidence ( X->Y) 。支持度用于衡量所发现规则的统计重要性,而置信度用于衡量关联规则的可信程度。一般来说,只有支持度和置信度均高的关联规则才可能是消费者感兴趣的、有用的规则。
2 Apriori算法
2.1算法原理
Apriori 算法是 Agrawal 等于 1994 年提出的一个挖掘顾客交易数据库中项集间的关联规则的重要方法,是迄今最有影响挖掘布尔关联规则频繁项集的关联规则算法。该关联规则在分类上属于单维、单层、布尔关联规则。
Apriori算法的基本思想是通过对数据库D的多次扫描来发现所有的频繁项集。在第k次扫描中只考虑具有同一长度k的所有项集。在第1趟扫描中,Apriori算法计算I中所有单个项的支持度,生成所有长度为1的频繁项集。在后续的扫描中,首先以前一次所发现的所有频繁项集为基础,生成所有新的候选项集(Candidate Itemsets),即潜在的频繁项集,然后扫描数据库D,计算这些候选项集的支持度,最后确定候选项集中哪一些真正成为频繁项集。重复上述过程直到再也发现不了新的频繁项集。算法高效的关键在于生成较小的候选项集,也就是尽可能不生成和计算那些不可能成为频繁项集的候选项集。
2.2算法步骤
Apriori 算法主要分成两步:首先找出数据中所有的频繁项集,这些项集出现的频繁性要大于或等于最小支持度。然后由频繁项集产生强关联规则,这些规则必须满足最小支持度和最小置信度。算法的总体性能由第一步决定,第二步相对容易实现。
Lk:k维频繁项目集的集合,该集合中的每个元素包含两部分:项目集本身、项目集的支持度。
Ck:k维候选项目集集合,是k维频繁项目集集合的超集,也就是潜在的频繁项目集集合,该集合中的每个元素也包含两部分:项目集本身、项目集的支持度。任何项目集的元素都按某个标准(例如字典顺序)进行排序。包括k个项目(k个项目为:c[1],c[2],„,c[k])的项目集c用如下形式来表示:c[1],c[2],„,c[k],由于c已经排序,则有:c[1]<c[2]<„<c[k]。
a).Apriori算法描述
输入:交易数据库D,最小支持度minsup
输出:频繁项目集集合Answer
(1)Begin
(2)L1=(large 1-itemsets);
(3)For(k=2;Lk-1≠ ;k++)Do
(4)Ck=apriori_gen(Lk-1);//得到新候选项目集。
(5)For all transactionst∈D Do
(6)Ct=subset(Ck,t);//计算属于t的候选项目集。
(7)For all candidates c∈Ct Do
(8)c.count++;
(9)EndFor
(10)EndFor
(11)Lk={c∈Ck|c.count≥minsup}
(12)EndFor
(13)Answer=Uk Lk;
(14)End
b).apriori_gen算法描述
输入:Lk-1
输出:Lk
(1)Begin
(2)For each p∈Lk-1 Do
(3)For each q∈Lk-1 Do
(4)If p.item1=q.item1,„,p.itemk-2=q.itemk-2,p.itemk-1<q.itemk-1
(5)Then c=p.item1,p.item2,„,p.itemk-1,q.itemk-1;EndIf
(6)If (k-1)-subset s Lk-1 of c
(7)Then delete c;
(8)Else insert c into Ck;EndIf
(9)EndFor
(10)EndFor
(11)Return Lk
(12)End
2.3算法分析与改进
如果在交易数据集合中包含的不同的项目的数量为n个,以Apriori为基础的频繁项目集发现算法将要计算2n项目集。当n比较大时,将会产生组合爆炸,实际上这将是NP难的问题。
J.S.Park等人提出了一个基于Hash技术的DHP算法,利用Hash技术有效改进候选项目集的生成过程,减少I/O的存取时间,其效率高于Apriori算法。虽然Sampling算法、Partition算法、DIC算法等都试图减少对交易数据集合的搜索次数,但仍有很多缺点。Sampling算法从原数据集合中随机抽样出一部分样本,利用样本来挖掘关联规则以减少算法的搜索次数,但是由于数据集合中经常存在数据分布不均匀的情况,所以随机抽样根本就无法保证能够抽取到有代表性的样本;Partition算法虽然通过对数据集合分区分别挖掘,最后进行汇总的方法来减轻I/O的负担,事实上它是增加了CPU的负担。
3 SAS 关联规则案例
1问题背景
考虑下面案例,一家商店希望通过客户的基本购买信息了解客户购买某商品同时还购买其他哪些商品。这就是常见的购物篮分析。
ASSOCCS数据集中1001位客户购买商品的信息。主要有以下商品信息:1001位顾客购买了7个项目的商品,产生了7007行数据。每一行数据表示一条交易信息。
2建立初始流程图
3设置输入数据源结点
打开输入数据源结点
从SAMPSIO库中选择ASSOCS数据集
点击变量选项卡
设置customer的模型角色为id
设置time的模型角色为rejected
设置product的模型角色为target
关闭输入数据源结点

4设置关联规则结点
打开关联规则结点,选择general选项卡,修改结点信息。
5理解和选择分析模式

默认的分析模式是by context,它根据输入数据源的结点信息选择合适的分析方法。如果输入数据集包括:
一个id变量和target变量,该结点自动执行关联分析。
一个序列变量包括使用的状态,该结点执行序列分析。序列分析需要定义一个序列模型角色的变量。
另外,还可以设置最小支持度,项目的最大数目和最小置信度。
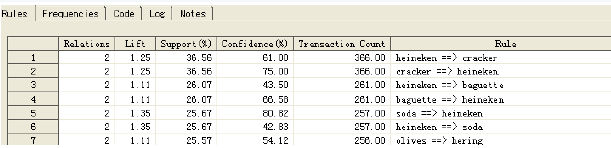
在规则选项卡中包含每条规则的信息。并且,还可以根据提升度,支持度和置信度的升序或者降序进行排列。
定制化
在SAS EM中计算一个项与其他项之间的关联规则。
1创建一个新的数据集或者修改原数据集使它至少包含以下三个变量:
一个唯一的ID标识,一个目标变量,一个人工变量(如果值为coke,则设置为1否则设置为2)。
2执行序列模式发现。
此处以coke为例,得到转化后的数据集
data tmp;
set sampsio.assocs;
if product = 'coke' then visit = 1 ;
else visit = 2;
run;