
其实拿这个网站当教程刚开始我是拒绝、换其他网站吧,又没什么动力···· 然后就···········
上一篇Scrapy带大家玩了 Spider
今天带带大家玩的东西有两点、第一CrawlSpider、第二Scrapy登录。
目标站点:www.haoduofuli.wang

Go Go Go!开整!
还记得第一步要干啥?
创建项目文件啊!没有Scrapy环境的小伙伴们请参考第一篇安装一下环境哦!
打开你的命令行界面(Windows是CMD)使用切换目录的命令到你需要的存放项目文件的磁盘目录
D:
scrapy startproject haoduofuli
好了 我在D盘创建了一个叫做haoduofuli的项目。
用Pycharm打开这个目录开始我们的爬取之路 Come on!
下一步我们该做什么记得吧?当然是在items.py中声明字段了!方便我们在Spider中保存获取的内容并通过Pipline进行保存(items.py本质上是一个dict字典)
我在items.py中声明了以下类容:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class HaoduofuliItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
category = scrapy.Field() #类型
title = scrapy.Field() #标题
imgurl = scrapy.Field() #图片的地址
yunlink = scrapy.Field() #百度云盘的连接
password = scrapy.Field() #百度云盘的密码
url = scrapy.Field() #页面的地址
至于为啥声明的这些类容:各位自己去网站上观察一下、(主要是吧,贴在这儿的话 估计这博文就要被人道主义销毁了)
别忘记上一篇博文教大家的那种在IDE中运行Scrapy的方法哦!
好上面的我们搞定、开始下一步编写Spider啦!

在spiders文件夹中新建一个文件haoduofuli.py(还不清楚目录和作用的小哥儿快去看看Scrapy的第一篇)
首先导入以下包:
from scrapy.spiders import CrawlSpider, Rule, Request ##CrawlSpider与Rule配合使用可以骑到历遍全站的作用、Request干啥的我就不解释了
from scrapy.linkextractors import LinkExtractor ##配合Rule进行URL规则匹配
from haoduofuli.items import HaoduofuliItem ##不解释
from scrapy import FormRequest ##Scrapy中用作登录使用的一个包
详细介绍请参考:http://scrapy-chs.readthedocs.io/zh_CN/latest/topics/spiders.html 中的:CrawlSpider、爬取规则(Crawling rules)、pare_start_url(response)|(此方法重写start_urls)、以及Spider中start_requests()方法的重写。
下面我带大家简单的玩玩儿顺便获取我们想要的东西。
前面提到了我们需要获取全站的资源、如果使用Spider的话就需要写大量的代码(当然只是相对而言的大量代码)!但是我们还有另一个选择那就是今天要说的CrawlSpider!

首先我们新建一个函数 继承CrawlSpider(上一篇博文是继承Spider哦!)
见证奇迹的时刻到了!
from scrapy.spiders import CrawlSpider, Rule, Request ##CrawlSpider与Rule配合使用可以骑到历遍全站的作用、Request干啥的我就不解释了
from scrapy.linkextractors import LinkExtractor ##配合Rule进行URL规则匹配
from haoduofuli.items import HaoduofuliItem ##不解释
from scrapy import FormRequest ##Scrapy中用作登录使用的一个包
class myspider(CrawlSpider):
name = 'haoduofuli'
allowed_domains = ['haoduofuli.wang']
start_urls = ['http://www.haoduofuli.wang']
rules = (
Rule(LinkExtractor(allow=('\.html',)), callback='parse_item', follow=True),
)
def parse_item(self, response):
print(response.url)
pass
是不是很厉害!加上中间的空行也就不到二十行代码啊!就把整个网站历遍了!So Easy!!
上面的几行代码的意思 很明了了啊!我只说说rules这一块儿
表示所有response都会通过这个规则进行过滤匹配、匹配啥?当然是后缀为.html的URL了、callback=’parse_item’表示将获取到的response交给parse_item函数处理(这儿要注意了、不要使用parse函数、因为CrawlSpider使用的parse来实现逻辑、如果你使用了parse函数、CrawlSpider会运行失败。)、follow=True表示跟进匹配到的URL(顺便说一句allow的参数支持正则表达式、虽然我也用得不熟、不过超级好使)
至于我这儿的allow的参数为啥是’.\html’;大伙儿自己观察一下我们需要获取想要信息的页面的URL是不是都是以.html结束的?明白了吧!
然后rules的大概运作方式是下面这样:
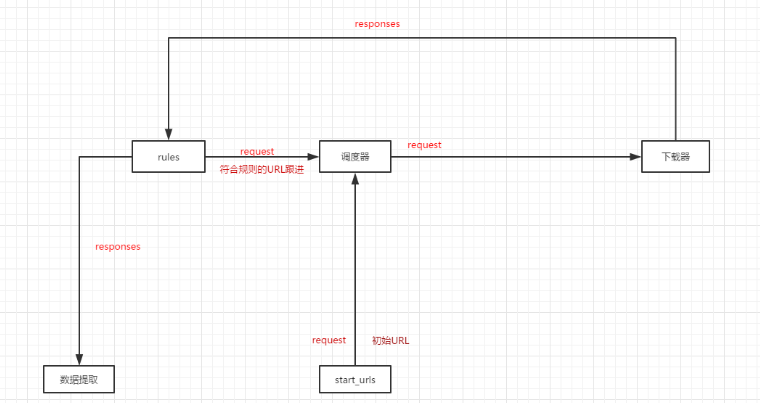
图很清晰明了了(本人也是初学、如有错误 还请各位及时留言 我好纠正。)中间的数据流向是靠引擎来完成的。
好了 我们来看看效果如何:
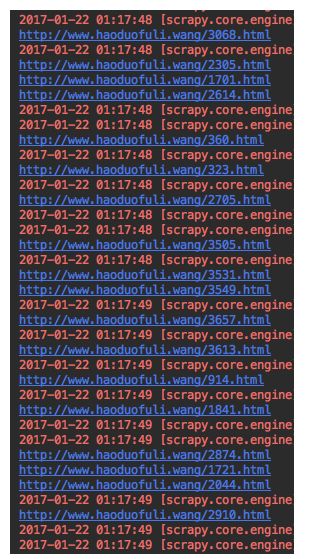
这是我们返回response的URL、一水儿的 URL啊!完美!下面就可以进行提取数据了(诶!不对啊怎么没有没什么提取工具啊!还记得上篇博文说的不?下载器返回的response是支持Xpath的哦!我们直接使用Xpath来提取数据就行啦!)

那么问题来了!Xpath没用过啊!不会用啊!这可咋整啊!别怕!草鸡简单的!!来不着急!
先大声跟我念:Google大法好啊!
哈哈哈 没错、我们需要Chrome(至于为啥不用Firefox、因为不知道为啥Firefox的Xpath有时和Chrome的结构不一样 有些时候提取不到数据、Chrome则没什么问题)
来来!跟着我的节奏来!包你五分钟学会使用Xpath!学不会也没关系、毕竟你也不能顺着网线来打我啊!
第一步:打开你的Chrome浏览器 挑选上面任意一个URL打开进入我们提取数据的页面(不贴图 容易被Say GoogBay):
第二步:打开Chrome的调试模式找到我们需要提取的内容(如何快速找到呢?还不知道的小哥儿 我只能说你实在是太水了)
点击下面红圈的箭头 然后去网页上点击你需要的内容就 哔!的一下跳过去了!

第三步:在跳转的那一行就是你想要提取内容的一行(背景色完全区别于其它行!!)右键Copy —-Copy XPath:
就像下面我提取标题:
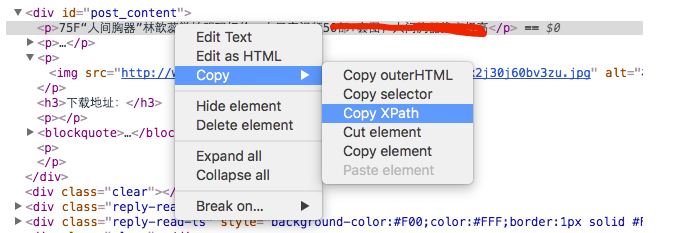
你会得到这样的内容:
//*[@id=”post_content”]/p[1]
意思是:在根节点下面的有一个id为post_content的标签里面的第一个p标签(p[1])
如果你需要提取的是这个标签的文本你需要在后面加点东西变成下面这样:
//*[@id=”post_content”]/p[1]/text()
后面加上text()标签就是提取文本
如果要提取标签里面的属性就把text()换成@属性比如:
//*[@id=”post_content”]/p[1]/@src
So Easy!XPath提取完毕!来看看怎么用的!那就更简单了!!!!
response.xpath(‘你Copy的XPath’).extract()[‘要取第几个值’]
注意XPath提取出来的默认是List。

看完上面这一段 估计还没有五分钟吧 !好了XPath掌握了!我们来开始取我们想要的东西吧!现在我们的代码应该变成这样了:
from scrapy.spiders import CrawlSpider, Rule, Request ##CrawlSpider与Rule配合使用可以骑到历遍全站的作用、Request干啥的我就不解释了
from scrapy.linkextractors import LinkExtractor ##配合Rule进行URL规则匹配
from haoduofuli.items import HaoduofuliItem ##不解释
from scrapy import FormRequest ##Scrapy中用作登录使用的一个包
class myspider(CrawlSpider):
name = 'haoduofuli'
allowed_domains = ['haoduofuli.wang']
start_urls = ['http://www.haoduofuli.wang']
rules = (
Rule(LinkExtractor(allow=('\.html',)), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = HaoduofuliItem()
item['url'] = response.url
item['category'] = response.xpath('//*[@id="content"]/div[1]/div[1]/span[2]/a/text()').extract()[0]
item['title'] = response.xpath('//*[@id="content"]/div[1]/h1/text()').extract()[0]
item['imgurl'] = response.xpath('//*[@id="post_content"]/p/img/@src').extract()
return item
我们来跑一下!简直完美!
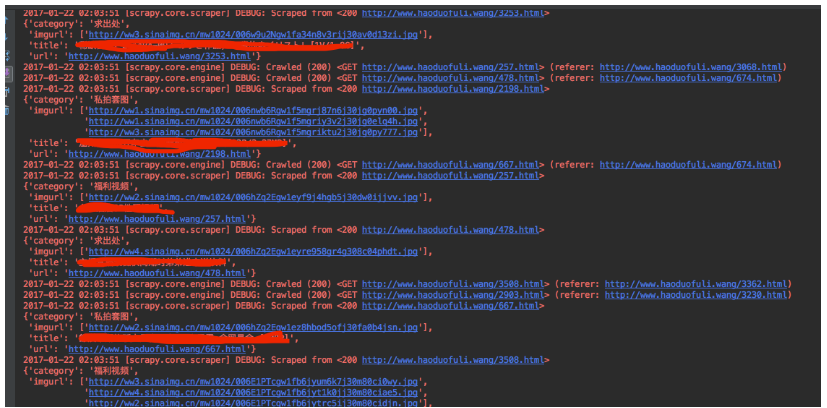
关于imgurl那个XPath:
你先随便找一找图片的地址Copy XPath类似得到这样的:
//*[@id=”post_content”]/p[2]/img
你瞅瞅网页会发现每一个有几张图片 每张地址都在一个p标签下的img标签的src属性中
把这个2去掉变成:
//*[@id=”post_content”]/p/img
就变成了所有p标签下的img标签了!加上 /@src 后所有图片就获取到啦!(不加[0]是因为我们要所有的地址、加了 就只能获取一个了!)

