
这是菜鸟学Python的第82篇原创文章
阅读本文大概需要6分钟
上一篇讲了Pandas中的倚天剑Series,今天来讲一讲Pandas里面的屠龙宝刀DataFrame,它的功能要更强大,而且可以分析的维度更多,然后我们用一个小例子实战分析一下10大重点城市的房价和薪资情况
DataFrame
如果说Series是一维序列的话,那么DataFrame就是一种表数据结构,它含有一组有序的列,每列可以是不同的值类型哦(比如数值啊,字符串,布尔值等)
可以看成是共享一个index的Series的集合,跟我们平时用的Excel里面的表长的样子很像
或者通俗的认为DataFrame是一个把字典和列表结合的数据结构,能把字典和列表融合,听起来就蛮牛的
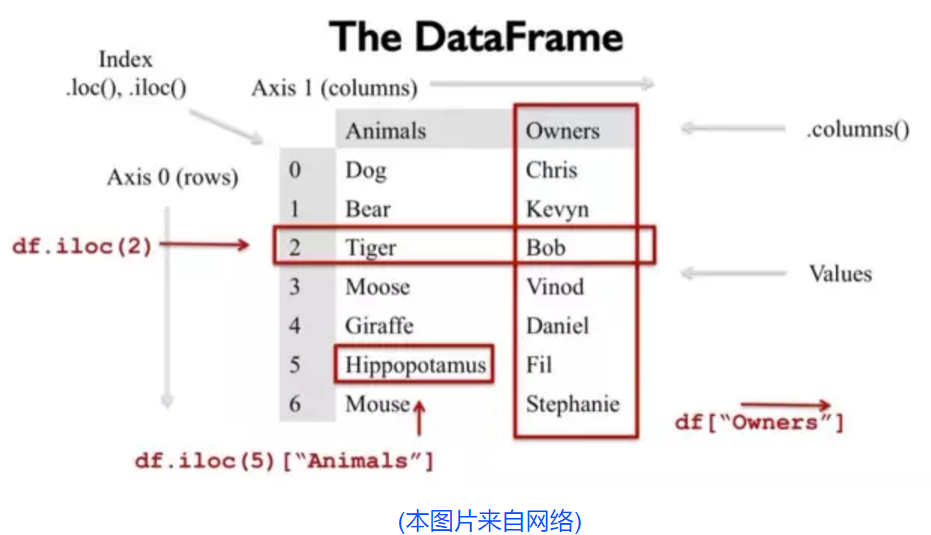
一张图纵览DataFrame
1.创建DataFrame的几种方式
1).纯字典创建
students={'names':['Leo','Jack','James'],'scores':[100,90,80]}
df=pd.DataFrame(students)
print df
>>
names scores
0 Leo 100
1 Jack 90
2 James 80
2).字典加列表创建
scores={'Scores':[100,90,80]}
names=['Leo','Jack','James']
df=pd.DataFrame(scores,index=names)
print df
>>
Scores
Leo 100
Jack 90
James 80
如果我们像再扩展一列,怎么办,很简单
#先把字典扩展一下,加上Ages键值对
ages={'Ages':[20,23,25]}
scores.update(ages)
df=pd.DataFrame(scores,index=names)
print df
>>
Ages Scores
Leo 20 100
Jack 23 90
James 25 80
3).用NumPy数组的创建
df = pd.DataFrame(np.arange(9).reshape(3,3))
print df
>>
0 1 2
0 0 1 2
1 3 4 5
2 6 7 8
行和列都是pandas取默认的数值,如果我们自定义行和列的名字,可以按照下面的形式,加上index和columns关键字
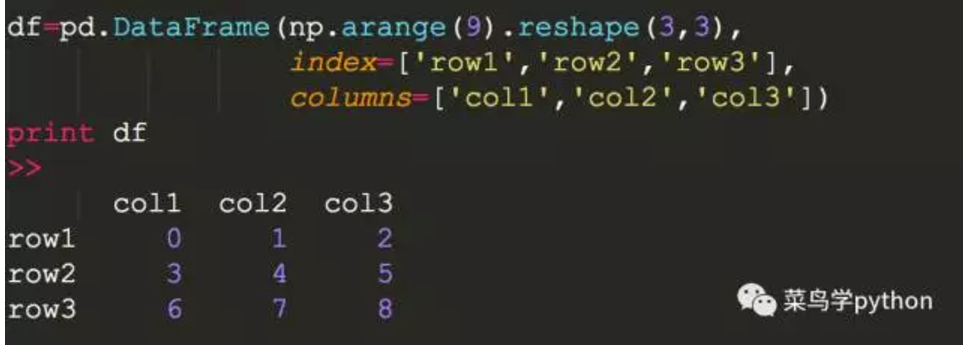
print df.describe()
#看看它的describe函数都显示啥
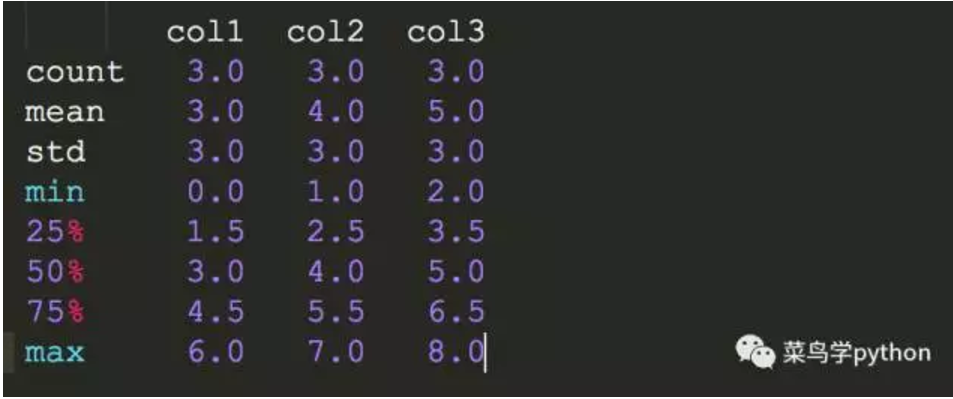
跟Series的很类似,只是按照每一列进行统计
2.索引选取,切片
DataFrame因为维度比Series多很多,所以我们可以从各个角度获取索引
比如:3*3的表结构 如图:
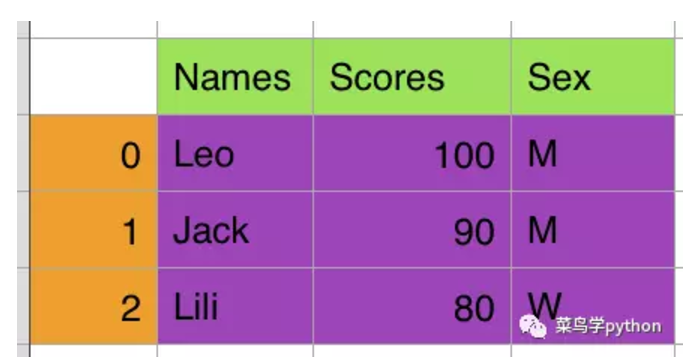
students=pd.DataFrame({'Name':['Leo','Jack','Lili'],
'Scores':[100,90,80],
'Sex':['M','M','W']})
1).获取某一列的数据
print students['Name']#也可以students.Name
>>
0 Leo
1 Jack
2 Lili
有同学说,这不就是前面讲的Series吗,对啊,不行我们打一下type看看
print type(students['Name'])
>>
<class 'pandas.core.series.Series'>
2).获取某一行的数据,用ix(index of label)
print students.ix[0]
>>
Name Leo
Scores 100
Sex M
看pandas多贴心,把列名也显示出来了
3).切片获取多行
print students[0:2]
>>
Name Scores Sex
0 Leo 100 M
1 Jack 90 M
4),切片获取多列
print students[['Name','Sex']]
>>
Name Sex
0 Leo M
1 Jack M
2 Lili W
或者只想取前两列,前两行
print students.ix[0:1,[0,1]]
>>
Name Scores
0 Leo 100
1 Jack 90
也可以用iloc来处理,print students.iloc[[0,1],[0,1]]一样的效果
3.修改和删除
1).一下子把成绩都改成100
students['Scores']=100
print students
>>
name scores sex Scores
0 Leo 100 M 100
1 Jack 90 M 100
2 Lili 80 W 100
2).增加一列
students['hobby']=['music','movie','singing']
print students
>>
Name Scores Sex hobby
0 Leo 100 M music
1 Jack 90 M movie
2 Lili 80 W singing
是不是和字典用法有点像
3).删除某列,比如删掉Sex列
del students['Sex']
print students
>>
Name Scores hobby
0 Leo 100 music
1 Jack 90 movie
2 Lili 80 singing
4.过滤数据
过滤数据跟Numpy和Series的用法很类似,一招鲜吃遍天
#比如:过滤出学生的成绩大于等于90分的
print students[students.Scores>=90]
>>
Name Scores Sex
0 Leo 100 M
1 Jack 90 M
#比如:过滤出列里是女生的数据
print students[students.Sex=='W']
>>
Name Scores Sex
2 Lili 80 W

2016年的房价涨幅是相当惊人啊,我从网上截选了10个城市的平均房价和薪资待遇,我们通过这些数据,来实战运用一下上面学的知识
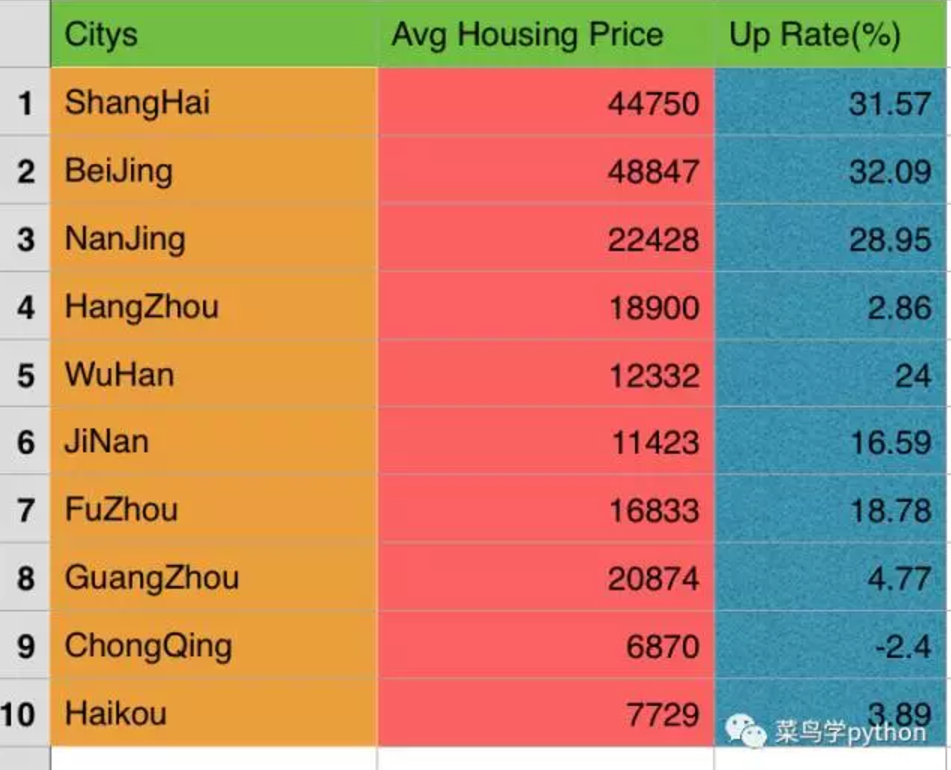
1.十大城市的房价和薪资情况
2016年的房价
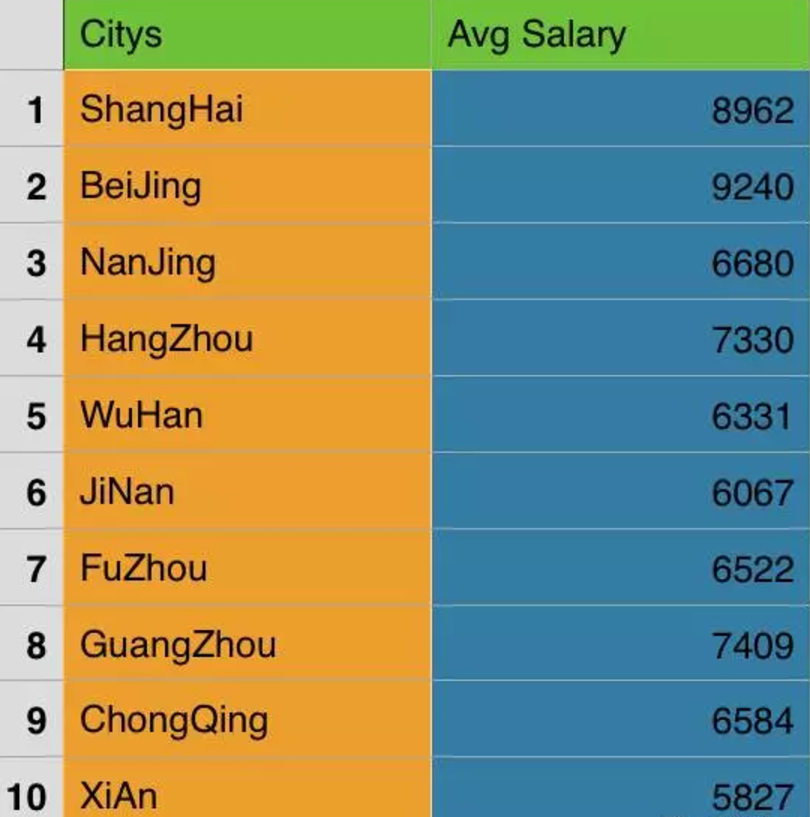
2016年的白领薪资
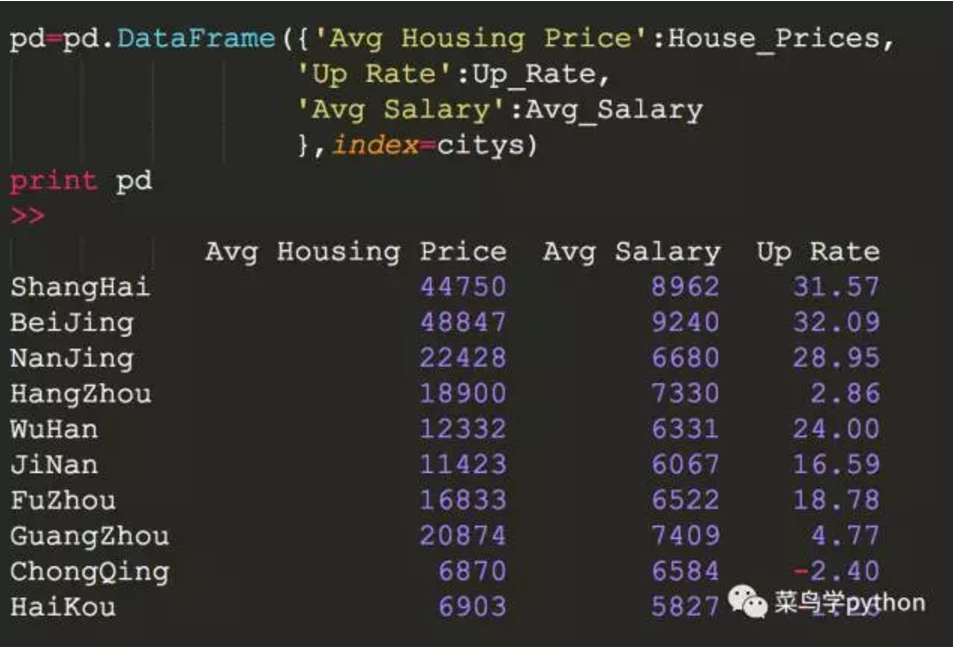
2.创建Pandas数据结构
根据城市,平均房价,同比上年涨幅,平均薪资这跟个表创建DataFrame对象
citys=['ShangHai','BeiJing','NanJing','HangZhou','WuHan',
'JiNan','FuZhou','GuangZhou','ChongQing','HaiKou']
House_Prices=[44750,48847,22428,18900,12332,
11423,16833,20874,6870,6903]
Up_Rate=[31.57,32.09,28.95,2.86,24,
16.59,18.78,4.77,-2.4,-1.26]
Avg_Salary=[8962,9240,6680,7330,6331,
6067,6522,7409,6584,5827]
3.最高的数据
Dataframe数据表已经形成,下面我们可以对数据进行随心所欲的分析
1).数据排个序,取前三名
上面的数据并没有排序,我们分别按照房价的高低,涨幅的高低和薪资的高度排个序
#最高房价前3名
print pd.sort_values(by='Avg Housing Price',ascending=False)[:3]
>>
Avg Housing Price Avg Salary Up Rate
BeiJing 48847 9240 32.09
ShangHai 44750 8962 31.57
NanJing 22428 6680 28.95
#涨幅最大前3名
print pd.sort_values(by='Up Rate',ascending=False).head()
>>
Avg Housing Price Avg Salary Up Rate
BeiJing 48847 9240 32.09
ShangHai 44750 8962 31.57
NanJing 22428 6680 28.95
#平均工资最高前3名
print pd.sort_values(by='Up Rate',ascending=False)[:3]
>>
Avg Housing Price Avg Salary Up Rate
BeiJing 48847 9240 32.09
ShangHai 44750 8962 31.57
GuangZhou 20874 7409 4.77
发现北京房价最高,房价涨的也最多,不过工资也是最高的
#有没有哪个城市的房价是跌的
print pd[pd['Up Rate']<0]
>>
Avg Housing Price Avg Salary Up Rate
ChongQing 6870 6584 -2.40
HaiKou 6903 5827 -1.26
2016全国房价一片暴涨,竟然还有城市是跌的,看来重庆个洼地啊,为啥重庆没有涨呢
#十大城市平均房价,平均工资
print pd.mean()
>>
Avg Housing Price 21016.000
Avg Salary 7095.200
Up Rate 15.595
dtype: float64
结论:
中国人房价确实很高,十大城市的平均房价都2w多了,平均涨幅达15%,要知道巴菲特的近5年复合收益率才9%,45年的才20%,看来投资房产只是一本好生意。
4.看看性价比最高的城市
辛苦苦苦打工,不久是为了安居乐业,我们看看十大城市哪一个城市性价比高一些
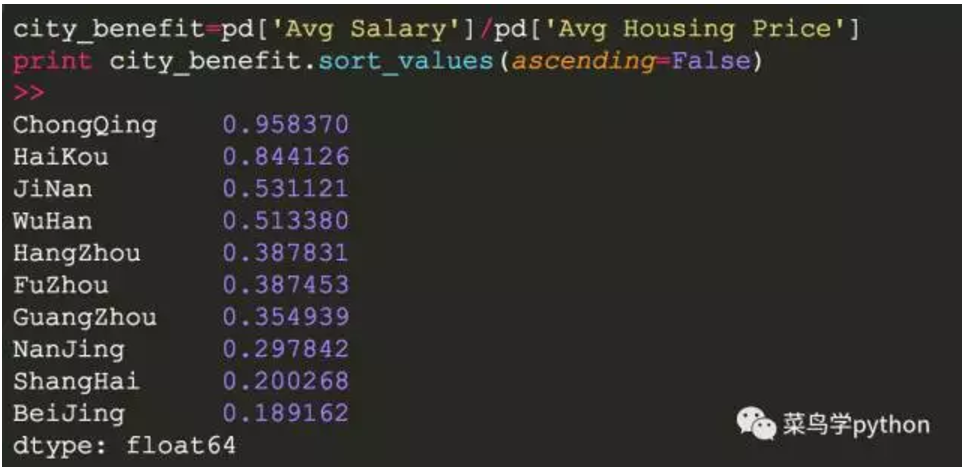
结论:
发现性价比最高的是重庆,一个月的工资可以买近一个平米的房子,而最苦的就是北京上一个月的班只能买0.2个平方~~,看来如果能吃辣的话,去重庆真是不错的哈哈

