阅读本文大概需要5分钟
本篇作者:倩倩同学
如果你正在寻找一个数据集,打算用它来上手学习的机器学习的算法,我想鸢尾花数据集应该是一个不错的选择. 本篇文章的数据来自大名鼎鼎的Kaggle,综合运用了Python的很多可视化库, 质量非常高!下面就看一下美女倩倩同学是如何研究分析这个数据集的~~
要点:
用到的库:
pandas,matplotlib,seaborn,sklearn
工具:
Pycharm/Spyder
Python:3.6
1.数据集初探
数据来自大名鼎鼎的Kaggle网站,里面有很多好玩的数据集. 下面就是Iris数据:

Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa(山鸢尾),Versicolour(杂色鸢尾),Virginica(维吉尼亚鸢尾))三个种类中的哪一类。

这个数据集,仅有150行,5列。该数据集的四个特征属性的取值都是数值型的,他们具有相同的量纲,不需要你做任何标准化的处理,第五列为通过前面四列所确定的鸢尾花所属的类别名称。
2.导入相应的库
这里需要说明的一点是,大家可能比较熟悉用matplotlib来作图,很少用到seaborn,seaborn其实是在matplotlib的基础上进行了更高级的API封装
从而使得作图更加容易,要注意的是一旦导入了seaborn,matplotlib的默认作图风格就会被覆盖成seaborn的格式,seaborn相比于matplotlib拥有更好的默认风格
它绘制的图表比matplotlib绘制的好看,并且可以绘制比matplotlib默认的图表更加深入的图表
导入了相关的包,下面我们就可以加载数据了
3.加载并探索数据集

>>
数据集的相关信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
花萼长度 150 non-null float64
花萼宽度 150 non-null float64
花瓣长度 150 non-null float64
花瓣宽度 150 non-null float64
所属种类 150 non-null object
dtypes: float64(4), object(1)
memory usage: 5.9+ KB
None
数据集的维度:
(150, 5)
数据集的随机10行数据:
花萼长度 花萼宽度 花瓣长度 花瓣宽度
106 4.9 2.5 4.5 1.7 Iris-virginica
128 6.4 2.8 5.6 2.1 Iris-virginica
8 4.4 2.9 1.4 0.2 Iris-setosa
43 5.0 3.5 1.6 0.6 Iris-setosa
24 4.8 3.4 1.9 0.2 Iris-setosa
139 6.9 3.1 5.4 2.1 Iris-virginica
115 6.4 3.2 5.3 2.3 Iris-virginica
129 7.2 3.0 5.8 1.6 Iris-virginica
70 5.9 3.2 4.8 1.8 Iris-versicolor
95 5.7 3.0 4.2 1.2 Iris-versicolor
数据集的特征属性:
花萼长度 花萼宽度 花瓣长度 花瓣宽度
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.054000 3.758667 1.198667
std 0.828066 0.433594 1.764420 0.763161
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.500000
鸢尾花所属种类的分布:
所属种类
Iris-setosa 50
Iris-versicolor 50
Iris-virginica 50
dtype: int64
这里我们加载数据集是通过目标网址加载的,加载的数据集没有列名,所以我们通过names给数据集加上了列名:
第一列表示的“花萼长度”
第二列表示的是“花萼的宽度”
第三列表示的是“花瓣的长度”
第四列表示的是“花瓣的宽度”
当然,你也可以直接把数据集下载到自己的电脑上,通过read_csv()读取本地目录中的数据集
通过观察运行结果我们可以发现该数据集的维度的确是(150,5),前四列属性特征均为数值型数据,最后一列则表示的是鸢尾花所属类别
通过观察数据集的统计特征,我们可以大致了解四个属性特征的取值情况。我们通过鸢尾花所属类别的分布可以发现在数据集中三种鸢尾花分别占了50行,他们的分布是很均匀的
下面我们可以通过数据的可视化加深你对数据集的了解
4.数据可视化
如果说通过单个变量的可视化图表可以让我们更好的了解每个属性的大致情况,那么通过多变量的可视化图表则可以让我们更好的了解属性对之间的相互关系。
下面我们分别通过pandas自带的plot(),hist()绘制单个变量的箱线图和柱状图,并通过scatter——matrix绘制描述属性对两两之间的相关性的散点图。
>>
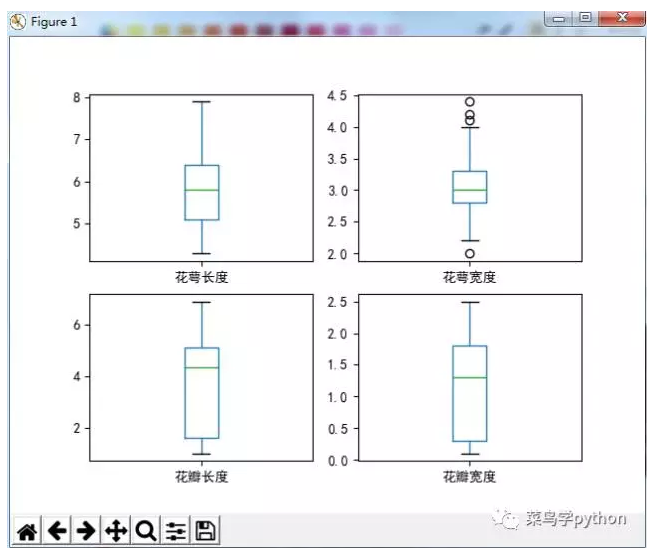

通过观察运行结果我们可以对属性的取值有一个直观的了解,你可能已经发现在柱状图中有两个属性的分布好像服从于正态分布,
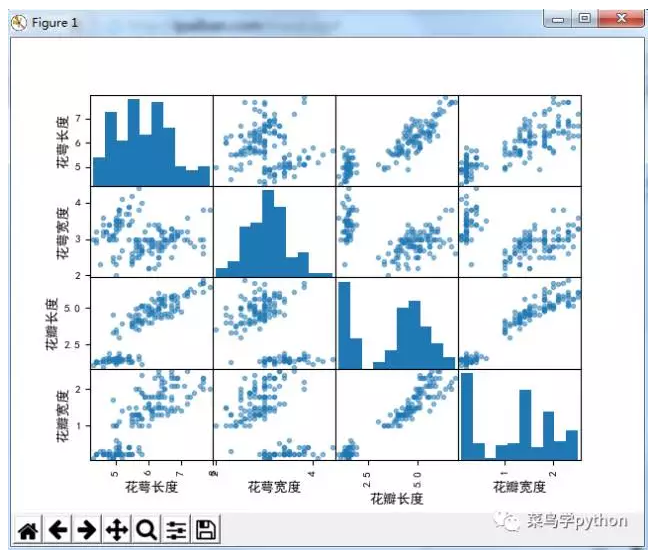
这对于我们后面利用这个假设去使用算法是很有用的,第三幅图展示了属性对之间的相关性,
我们知道如果散点图上沿着一条“瘦”直线排列,则说明这两个变量强相关,如果这些点形成一个球形,则说明不相关。
下面我们试着通过sns.pairplot(dataset,hue="所属种类",size=3)来替换scatt.matrix(dataset),看看他们的显示有什么区别:
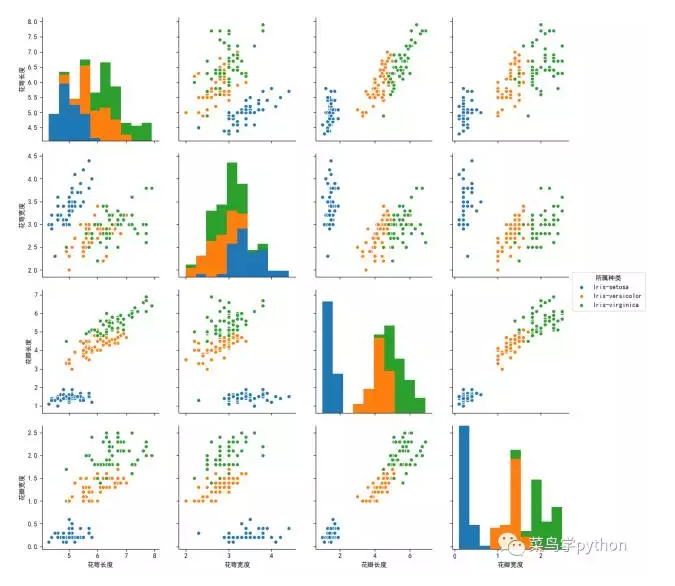
通过上面这幅图我们会发现它比之前运用scatter_matrix()绘制图表的更加直观,因为我们可以通过颜色来查看鸢尾花所属的种类.
5.机器学习算法分析
这里我们将对比六种不同的模型,看看它们在鸢尾花数据集上的性能表现如何,当我们不知道哪个一算法运用到该问题上比较好,也不知道如何调节参数会使得模型的性能更好时
我们可以通过可视化数据集的结果帮助我们选择一些合适的算法,下面我们将会尝试着运用以下六种算法,去评估它们在鸢尾花数据集上的性能表现。
逻辑回归模型:Logistic Regressin(LR)
线性判别分析模型:Linear Discriminant Analysis(LDA)
K近邻分析模型:K-Nearest Neighbors(KNN)
分类回归树模型:Classification and Regression Tree(CART)
朴素贝叶斯的高斯模型:Gaussian Naive Bayes(NB)
支持向量机分类模型:Support Vector Machines(SVM)
1).拆分数据集
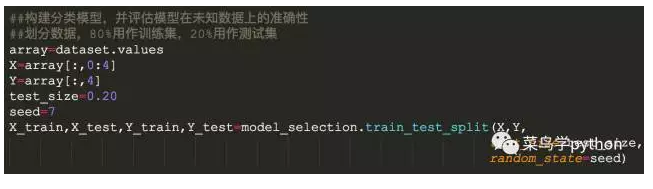
这里面我们将数据集中的80%用作训练集,20%用作测试集,设置随机数种子seed=7
当我们运用机器学习算法使用随机过程时,先设置一个随机种子是一个很好的习惯,这样就可以运行相同的代码多次,还能保证得到相同的结果,而且当你需要证明结果,使用随机数据比较算法或调试代码时,设置随机数种子也是很有用的
2).抽查算法
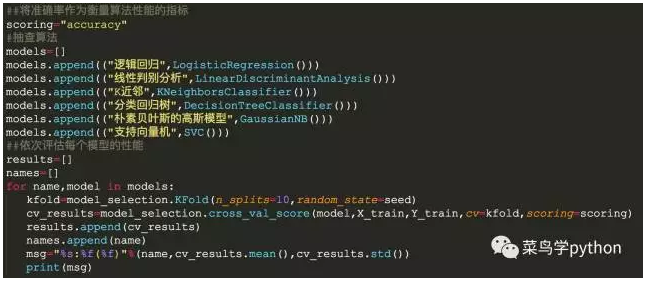
>>
逻辑回归:0.966667(0.040825)
线性判别分析:0.975000(0.038188)
K近邻:0.983333(0.033333)
分类回归树:0.966667(0.040825)
朴素贝叶斯的高斯模型:0.975000(0.053359)
支持向量机:0.991667(0.025000)
这里我们通过上面提到的六种算法构建了六种不同的分类模型,并设置了通过10折交叉验证以准率性这一指标来评估模型性能。我们可以看到运行结果中冒号前面是指我们采用的哪种分类算法构建的模型,冒号后面的第一个数字指的是10折交叉验证得到的准确率结果的一个平均值,而括号中的值代表的是准确性的一个标准差
3).运用模型预测未知数据
我们通过上面的运行结果可以发现鸢尾花数据集在支持向量机上的表现是最好的,下面我们将运用支持向量机这个模型来对我们的测试集进行预测,并在测试集上评估模型的性能
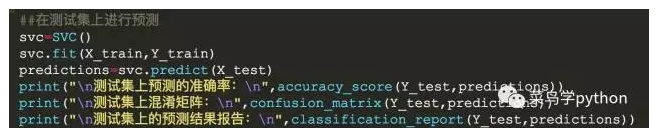
>>
测试集上预测的准确性:
0.933333333333
测试集上混淆矩阵:
[[ 7 0 0]
[ 0 10 2]
[ 0 0 11]]
测试集上的预测结果报告:
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 7
Iris-versicolor 1.00 0.83 0.91 12
Iris-virginica 0.85 1.00 0.92 11
avg / total 0.94 0.93 0.93 30
结论:
通过观察运行结果我们可以发现支持向量机模型在测试集上的准确度大约为93.3%,模型将两个杂色鸢尾花,错误的判断为了维吉尼亚鸢尾花。在这里我们并没有对模型进行调优,都是用的是默认参数,后期可以通过调节参数,提升模型的性能,达到更好的预测效果.
另外:需要本篇源码,请留言
历史人气文章
菜鸟学Python入门教程大盘点|7个多月的心血总结
同学,学Python真的不能这样学
全网爬取6500多只基金|看看哪家基金最强
用Python破解微软面试题|24点游戏
2道极好的Python算法题|带你透彻理解装饰器的妙用
一道Google的算法题 |Python巧妙破解
长按二维码,关注【菜鸟学python】

来源 | 菜鸟学Python
作者 | xinxin
本文章为菜鸟学Python独家原创稿件,未经授权不得转载

