阅读本文大概需要5分钟
本篇作者:小郑同学
上周的赠书活动中,收到了楼主送的《利用Python进行数据分析》一书很是欣喜,在这里感谢楼主! 书籍是从京东送来的,于是萌生了一个想法,打算从京东上爬取用户的评论,看看用户对该书的大致评价(虽然我知道这本书是很实用的,肯定大多好评)并尝试做一些分析,看还有没有什么有趣的现象~~
要点:
用到的库:
pandas,numpy,requests,jieba,wordclould
工具:
Pycharm/Spyder
Python:3.6
1.爬虫对象
上京东搜索了一下,弹出了好多的商品,要找肯定就找那个评论数最多的,有4600+条评论,足够来分析了.

2.网页分析
和大多数情况一样,可以先利用浏览器的开发者工具,对网页的元素进行查看,看评论区是放在哪里,以便我们爬虫。于是经过一番观察,发现了这个:
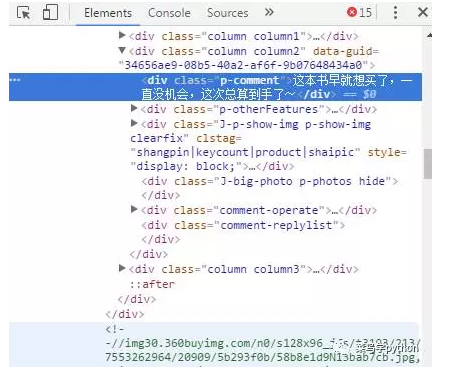
哈哈,太简单了吧,评论都是在<dic class=”p-commnet”></div>里面,于是二话不说,马上代码写起来,经过一番正则匹配,确认再三无误后,得到的结果却是空的,究竟怎么回事
正则表达式肯定没错呀,就那么点(因为这里得不到结果,就不贴上代码了)原来被京东给骗了,京东商品评论信息是由JS动态加载的,所以直接抓取商品详情页的URL并不能获得商品评论的信息
因此需要先找到存放商品评论信息的文件,那么该如何查看呢?我们可以从js那里找到相关文件,然后从中获取一个真正的URL.
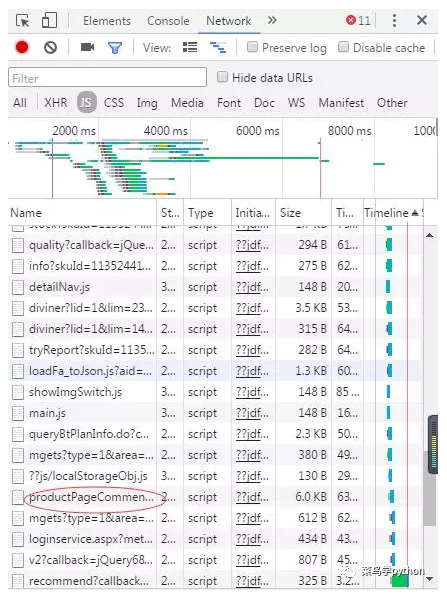
点进去,可以看到这个:
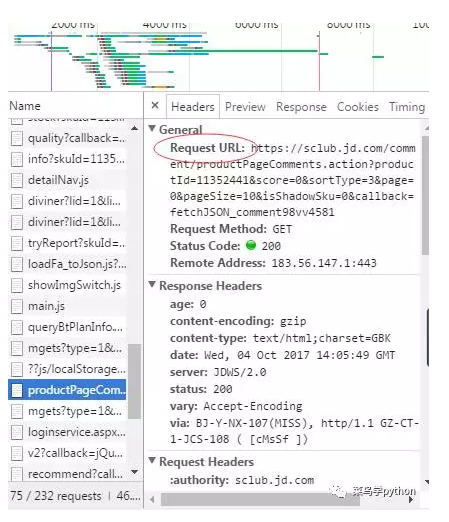
这个URL才是我们要找的,那么第二页的评论又是怎么样的URL,同样的,我们看一下相关的js文件,可以看到:
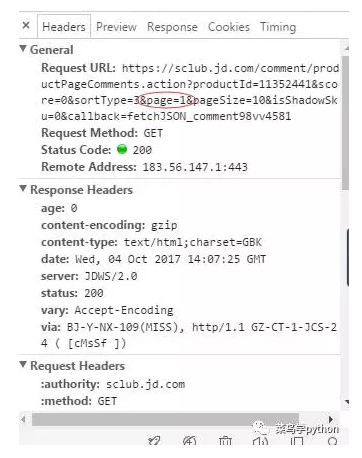
发现不同页数的评论只需改一下page后面的数字就行了(这里从0开始),复制后打开是这样的:

3.爬虫过程
接下来就要开始爬虫了,评论一共4600+,每一页是10条,我这里一共爬了400页的评论,大概是4000条。因为原始URL较长,我把它拆成3部分,并设置了每次爬取后休眠0.2秒,爬取过程也不算复杂,直接上代码:
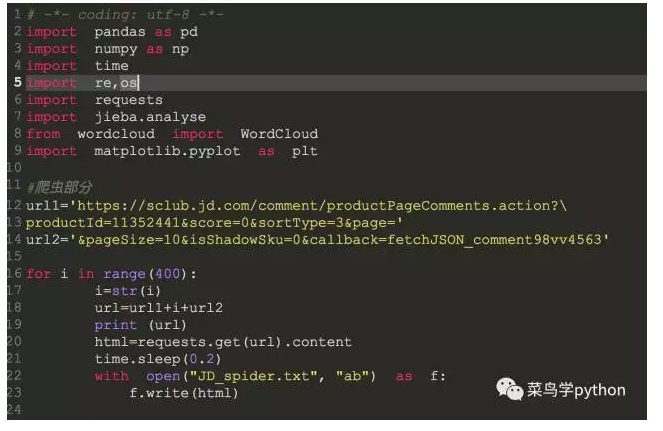
这里爬完后我直接写入了TXT文件里,下次再用就不用爬取了,直接读取文件就行,省点时间。爬取结果是一个接近6M的txt文件.
4.评论信息可视化
1).这次爬虫目的,是想要获取用户的评论信息.
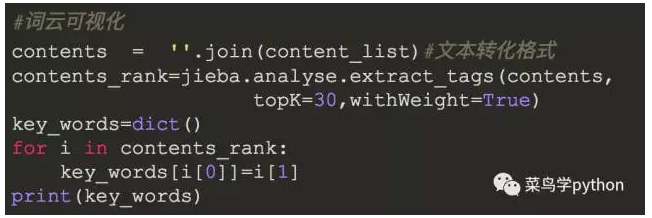
那么首先先来看看评论中的主要关键词都有什么,这里将会用结巴分词来处理,并且会进行词云可视化。先从之前的文件中读出数据,并用正则表达式获取我们要的评论信息:
html=open("JD_spider.txt",encoding='gb18030').read()
print (html)
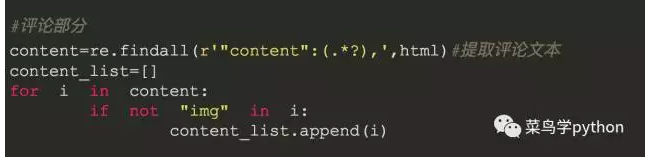
2).过滤数据
这里不展示初次筛选的结果,但是这里的输出里面还有些“杂质”,包含了一些img字段的,于是要二次处理,并放入列表中:
然后就可以用结巴分词来获取评论中的关键词了:
看一下结果:
>>
{'不错': 0.40207175434791953, 'Python': 0.16516135518025193, '数据分析': 0.14994788647273546, '京东': 0.12511940634626167, 'hellip': 0.09666796964961805, '学习': 0.09155126893924828, 'python': 0.09132451404084518, '好书': 0.08208335052285655, '本书':
...
0.040101087416086145, '入门': 0.037098712017513205, '物流': 0.03442644384797887, '实用': 0.03373438604258838, '快递': 0.03260293097472572, '经典': 0.0324224192260768, '速度': 0.0321156918440187, '东西': 0.03161500710010808}
如果觉得这样的话不好看,我们可以图像化,在此基础上进行词云可视化
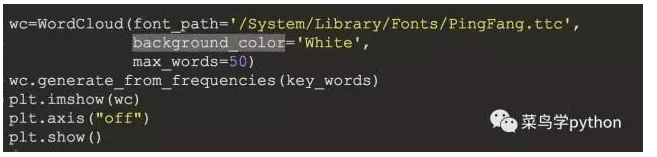
>>

5.其他数据可视化
京东的商品评论中包含了很多其他有用的信息,接下来将要把这些信息从页面代码中提取出来,整理成数据表以便进行后续的分析工作.
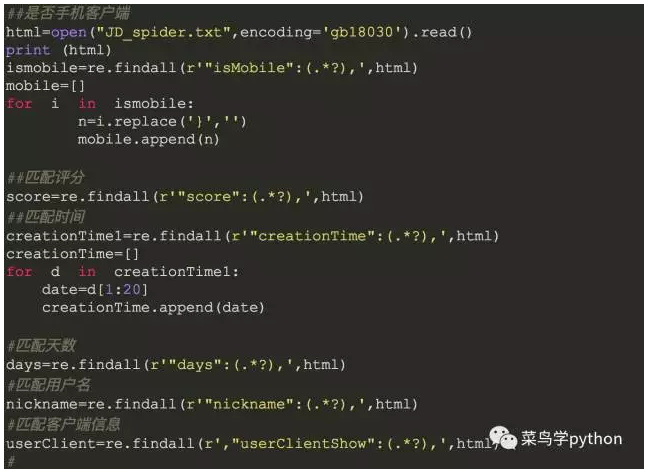
1).正则对每个字段进行提取
对于特殊的字段在通过替换等方式进行提取和清洗,先从文本读出数据,然后在进行匹配:
2).保存数据为dataframe
然后我们将其综合为一个dataframe,方便后面的分析

3).几个有趣的分析图
限于篇幅,我列出了一部分可视乎分析的图,具体的细节可以看文末的源码
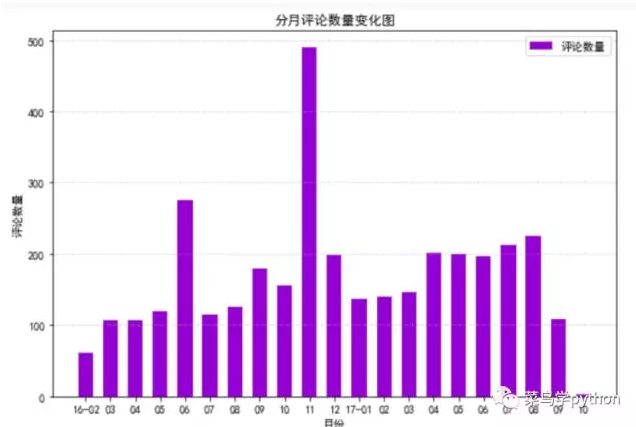
从图中可以直接读出,16年11月份达到了最高值,是该书评论最多的一个月份,是不是和双11的降价有关呢?虽然这里的评论数不等同于销量,但多少应该是有所联系的.
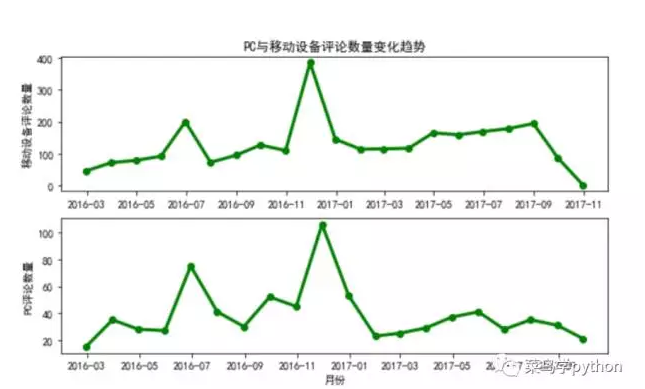
不难看出,在同等的时间段里,客户端的使用都要高于PC端。这个可以理解,因为手机确实比在电脑上评论方便得多,随时随地都可以在手机评论,购买。
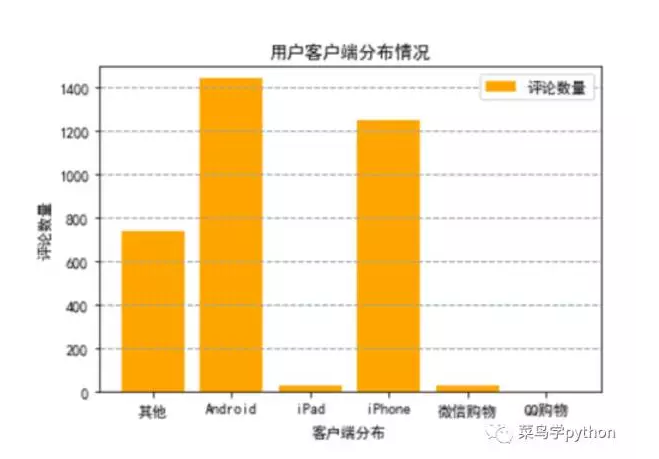
从用户客户端分布情况来看,其中使用Android的用户要高于iphone用户。由于微信购物和QQ购物在原始数据中单独被分了出来,无法确定使用设备型号,因此只能单独进行对比。使用微信购物渠道的用户要高于QQ购物,这点也符合当下情况
结论:来自小郑同学
终于写完了,虽然显示了有2000+的文字,前前后后也是花了几天的时间,但我还是觉得又不够好的地方,可能是来自于爬取到数据,可能是来自于处理的过程,也可能是分析的结论,希望能抛砖引玉,得到大家的指点。
在写这篇文章过程中,《利用Python进行数据分析》真的给我很多的帮助(画图,数据重采样等等),我十分建议想学习数据分析的同学,应该读一读这本书
另外,我也建议大家有时间多写写文章,记录下知识点,因为在这个过程中,我体会到一点就是,当你写下来的时候,你往往会学到更多的东西,把知识理解得更透彻
最后,衷心感谢“菜鸟学Python”这个平台,感谢楼主和关注这个公众号的所有小伙伴们,能够有这样的一个平台,让大家能够一起学习,互相帮助,是最好不过的事情了!希望大家能够一直坚持下去,一起进步!
另外:需要本篇源码,请留言
历史人气文章
菜鸟学Python入门教程大盘点|7个多月的心血总结
同学,学Python真的不能这样学
全网爬取6500多只基金|看看哪家基金最强
用Python破解微软面试题|24点游戏
2道极好的Python算法题|带你透彻理解装饰器的妙用
一道Google的算法题 |Python巧妙破解
长按二维码,关注【菜鸟学python】

来源 | 菜鸟学Python
作者 | xinxin
本文章为菜鸟学Python独家原创稿件,未经授权不得转载
