小白学文本分析即将到来,文本分析肯定离不开字符串,前面热身写了一篇玩转字符串上篇【秘籍总结】玩转Python里的字符串|上篇,今天就把下篇分享给大家,字符串里面的技巧非常多。热身完之后,我们就要跑步进入下一个主题,后面还有好多好玩有趣的东西,让我们继续前行~~
1、字符串替换
1.无所不能的正则
字符串的替换,这个话题很多小伙伴说,这不是很简单吧,未必哦,比如下面一段文本:假如有一个data.txt
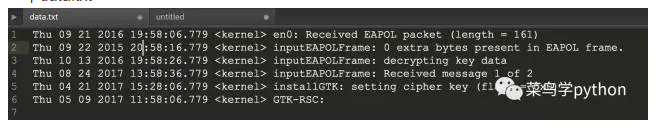
要求:
解决第一个问题:
这是一个非常典型的文本处理的需求,无论你是作数据分析还是作自然语言处理,第一步都是要对不规则的数据进行预处理,怎么办呢我们接着往下看:
1).读取数据
text=open('data.txt',encoding='utf-8').read()
print (text)
>>
Thu 09 21 2016 19:58:06.779 <kernel> en0: Received EAPOL packet (length = 161)
Thu 09 22 2015 20:58:16.779 <kernel> inputEAPOLFrame: 0 extra bytes present in EAPOL frame.
Thu 10 13 2016 19:58:26.779 <kernel> inputEAPOLFrame: decrypting key data
Thu 08 24 2017 13:58:36.779 <kernel> inputEAPOLFrame: Received message 1 of 2
Thu 04 21 2017 15:28:06.779 <kernel> installGTK: setting cipher key (flags = 0x0)
Thu 05 09 2017 11:58:06.779 <kernel> GTK-RSC:
<class 'str'>
是一个包含回车键的多行长字符串
2).用正则处理
万能的正则是处理字符串的利器,因为正则非常强大,基本都是一行搞定!(当然我们后面会讲用神库NLTK来分词处理),但是前提还是需要用正则对数据进行清洗.

因为日期是Thu 09 21 2016,我们不能简单的替换,每一行文本的日期都不一样,我们必须要分段去匹配,然后再重新排序替换.是不是有聪明的小伙伴已经想到了,对用re.sub
\w{3}表示星期几 3个字母
\d{2}表示2个数字,可以匹配月,日
\d{4}表示4个数字,可以匹配年
然后我们把匹配的每一个group重新排序r'\4/\2/\3/\1',\4表示匹配到的第4组(年份),\2表示匹配到的月份,\3表达匹配到的日期,\1其实就是星期,然后我们重新排序用'/'连接
>>

解决第二个问题:
我们需要把每一行里面的19:58:06.779毫秒去掉,可以在上面的基础继续修改一下,增加对时间的匹配(\d{2}:\d{2}:\d{2})(\.\d{3})
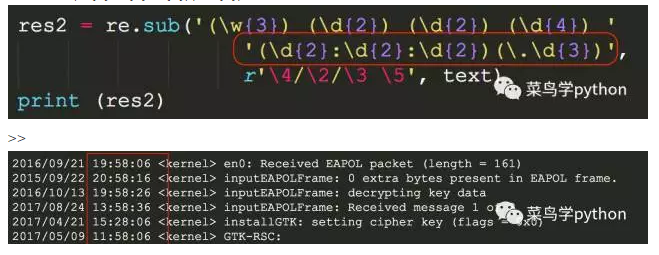
是不是感觉非常简洁,正则的强大往往在于能用极少的代码解决复杂的问题!那么除了上面的方法之外还有没有其他的路子呢
2.强大的Pandas处理
上面的文本很容易转成列表,列表又很容易可转成pandas的series,转成series有什么用呢,非常有用. Pandas里面有非常多的内置函数可以方便的对字符串进行矢量化的处理,其中就包含字符串替换.
比如:有一段文本:

这个文本存入了列表中,每一行都有类似这样的日期时间:"Monday 07 19 2017",我们想替换成2017/07/19/Mon,这么办呢,除了上面第一招之外,现在讲第二招.
1).pandas化文本
data=pd.Series(texts)
print (data)
>>
0 Monday 07 19 2017: The doctor's appointment is...
1 Tuesday 07 20 2017: The dentist's appointment ...
2 Wednesday 07 21 2017: At 7:00pm,there is a bas...
3 Thursday 07 23 2017: Be back home by 11:15 pm ...
4 Friday 07 24 2017: Take the train at 08:10 am,...
2).用Series里面的强大的str属性
下面是pandas里面的series.str的所以属性,是不是看的有点眼熟,对的跟字符串里面很像,但是又加了一些新的东西.(DataFrame也有str作用类型)

3).用replace轻松搞定

看一下结果:
>>
["2017/07/19/Mon: The doctor's appointment is at 2:45pm."
"2017/07/20/Tue: The dentist's appointment is at 11:30 am."
'2017/07/21/Wed: At 7:00pm,there is a basketball game!'
'2017/07/23/Thu: Be back home by 11:15 pm at the lastest.'
'2017/07/24/Fri: Take the train at 08:10 am,arrive at 09:00am.']
2、字符串的删除
字符串的删除其实和替换有一点类似,比如你可以替换为空字符,相当于删除.但是稍许不同,我们在文本清洗的时候,会大量用到字符串的删除,下面我们就来看一下常见的技巧.
1.strip()方法
比如我们有一个杂乱的字符串文本:
s=' ---hello world *** '
print (s.strip('-* '))
>>
hello world
我们只需要把-和*还有空格全部填入到strip里面就可以了,这里两端的杂乱字符就去掉了.但是中间的没有去掉,怎么办呢,接着看
2.强大的正则
第一种方法有弊端,中间的空格去不掉,还是要用强大的正则
s=' ---hello world *** '
print (re.sub(r'[\s*\-]+','',s))
>>
helloworld
我们设定一个正则规则,这要是空格,星号,减号一个或者多个全部替换为空,相当于去掉了这些字符
3.translate字符的映射
translate在Py2和Py3里面稍为有一些不同,我分别解释一下:
Py2:
假如我们一串乱码'123 This,* is very &good!'我们需要把符合,数字全部去掉

>>
THIS IS VERY GOOD
Py3:
python3里面的translate只接受一个参数,同样我们有一串乱的字符:
text='Life\twas like\f a box of\rchocolates\n'
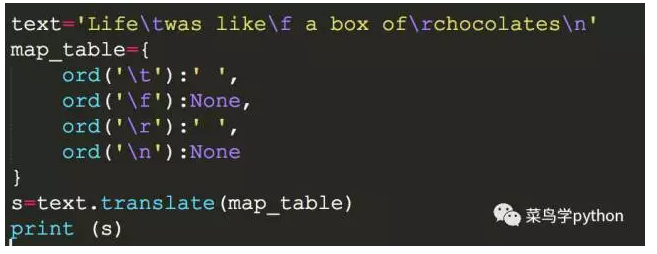
>>
Life was like a box of chocolates
结论:
好了,字符串上下两篇已经讲完了,一共5个大点:分割, 拼接, 切片, 替换和删除. 基本掌握这些技巧,打下基础,后面就可以开始学习更高级的文本分析.Pandas原生字符处理非常强大,后面会在文本分析里面补充讲的,大家如果有什么问题,欢迎留言讨论.
