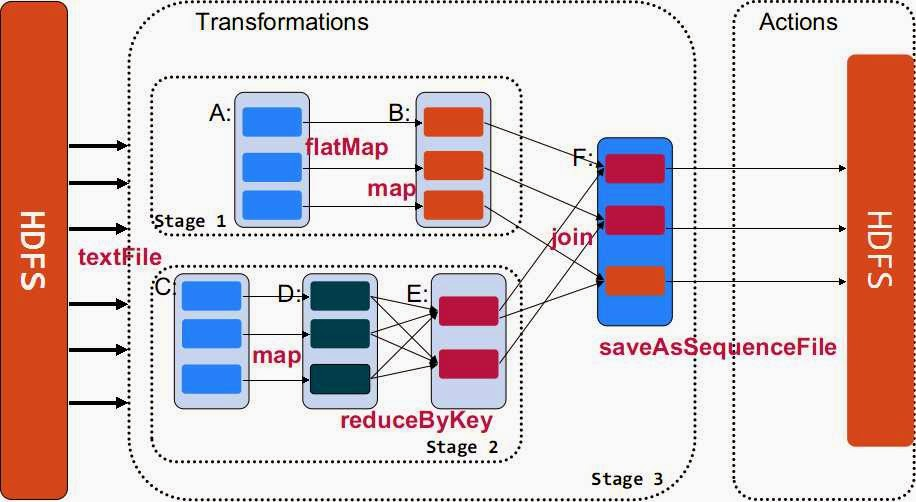
万丈高楼平地起,要熟悉Spark就得熟悉RDD,要熟悉RDD,就是要看Doc.当我们对RDD做运算时,其实都会产生不同的RDD.RDD的官方文件(http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.rdd.RDD)一开始说到这些不同的RDD都共同拥有五个特性:
- Partition的列表(sorry不知道partition要怎样翻):RDD是分散式架构,会将一笔资料分成一到n个partition,所以每个RDD里面都会纪录这些partition.
- 计算函数:当我们处理RDD时,RDD会将相同到函数map到每个partition上执行.
- 与其他RDD的依赖关系:每个RDD都会连结到其他RDD,所以RDD里面也会纪录与其他RDD的关系,如果RDD发生损毁可以依照相同的依赖关系去要前一个(或数个)RDD传资料给他.
- (Optionally)放置Key-value的分页:如果有用到hash-partition时,会多一个partition来放对应的key-value.
- (Optionally)处理资料时偏好的位置:一般来说RDD在计算资料时会优先在原地处理后再将资料做交换(如果有需要的话,例如reduceByKey).这时候RDD会存放处理各分页资料的位置.
以上是每个RDD物件都具有的特性,RDD透过这些特性可以来做复杂的计算和资料处理.而除了系统原本就有的RDD之外呢,使用者也可以自己继承并实作RDD来创造自己的RDD.

