 自从可以在 Colab 上用免费的 GPU 后,就有动力开始玩 Deep Learning 了.伟哉谷歌赞叹谷歌.本来我都是 Pytorch 派,但是因为公司用的 GCP 上面的 Cloud ML 只适用 google 自家的 Tensor Flow,所以还是得学一下 Tensorflow QQ.不过好险网路上很多神人,把 Tensorflow 包成更高阶的 API — Keras.
自从可以在 Colab 上用免费的 GPU 后,就有动力开始玩 Deep Learning 了.伟哉谷歌赞叹谷歌.本来我都是 Pytorch 派,但是因为公司用的 GCP 上面的 Cloud ML 只适用 google 自家的 Tensor Flow,所以还是得学一下 Tensorflow QQ.不过好险网路上很多神人,把 Tensorflow 包成更高阶的 API — Keras.
千解释万解释不如一行 Demo Code,以下直接进 Demo.
GCP 资讯
先看一下 GPU 的资讯:
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, LeakyReLU, Conv2D
from keras.optimizers import RMSprop
from keras import backend as K
K.tensorflow_backend._get_available_gpus()
from matplotlib.pyplot import imshow
import numpy as np
把等下要用的东西 import 进来后,Keras 自己有提供一些 dataset 可以玩,今天用的 MNIST 就是很标准的资料集.
MNIST
http://yann.lecun.com/exdb/mnist/ 这边有搜集不同演算法训练的结果,例如 KNN、SVM 等等,今天会用简单的两层 NN 来算.
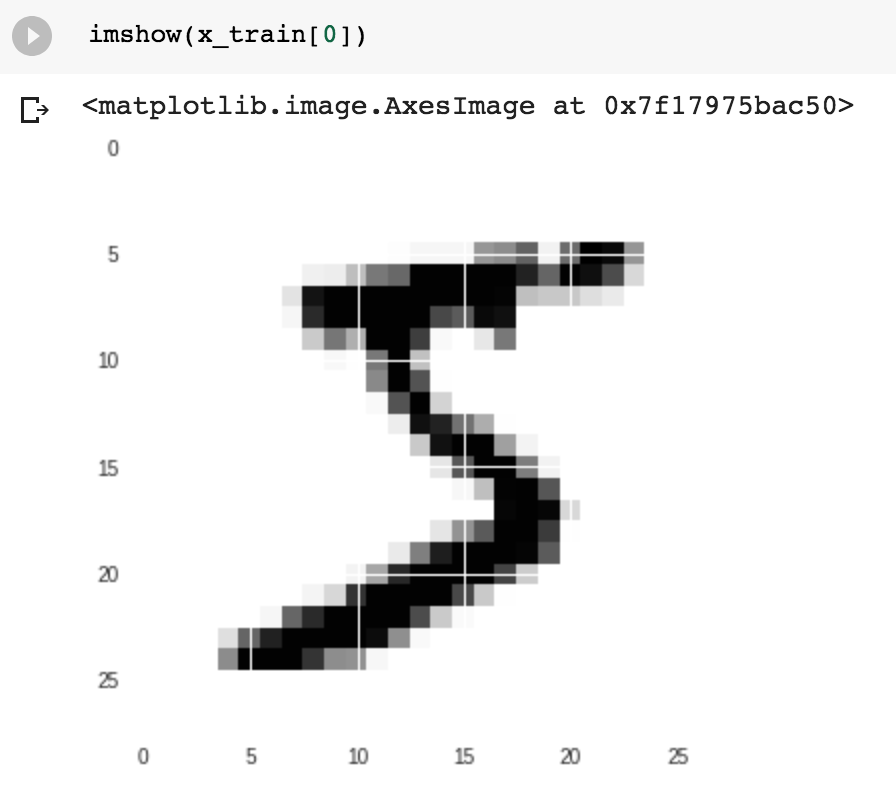
每个资料长得像这样 28 x 28 的黑白数字图案:
资料整理
# the data, shuffled and split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')

然后再看一下预测目标,原本的 y 是 0–9 的数字,需要先做一次 one-hot encoding.
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
叠 Model
用 Keras 最爽的就是,Keras 透过 Pipeline 的方式将不同 layer 的神经网络碟在一起,只要指定各层的类型、要几个 dimension 、activation function ,就可以建立 Model.
model = Sequential()
model.add(Dense(20, activation=LeakyReLU(), input_shape=(784,)))
model.add(Dense(20, activation=LeakyReLU()))
model.add(Dense(10, activation='softmax'))
model.summary()
用法简单到不用解释XD:指定 model 后,透过 model.add 的方式由前向后加层,不用自己去手刻 forward functino.(但是相对也比较不弹性啦,一体两面)
这边用的是简单 NN 模型,前两层有 20 个节点,activation function 是 LeakyReLU.只有第一层要指定 input 资料放进去的形状,之后都会自己处理.
最后一层因为要输出十个类别,所以用了 10 个节点的 softmax.

从这个 summary 可以看得出来每一层用的 layer、有几个节点、总共有多少参数要算等重要资讯.
训练啰
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
Keras 是静态模型,需要先 compile 之后才能 train.在 compile 时需要指定 loss function 、优化演算法、以及训练时要看的 metrics.
batch_size = 128
num_classes = 10
epochs = 10
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
最后要 train 的时候,需要给定训练资料及的x、y、batch_size(每次要放几笔资料)、epochs(总共要训练几次)、以及用来做 validation 的data set.

可以看到 Keras 把整个训练过程包得非常好,每次 epoch 会显示训练和 validation 资料的 loss 和 accuracy 等资讯,非常的方便.
结果
这是刚刚 test 的 dataset,下次试试看把模型存起来直接拿 pre-train model 来用.