开篇介绍
实际上用英文可能方便区别一些,Dimension Attribute Property。 这里面包含三个概念:
Dimension 维度 - 属性和属性层次结构的集合 A collection of attributes and hierarchies,维度通常对应的是在数据仓库中的维度表。
Attribute 属性 - 维度是属性的集合,可以简单理解属性就是来自于维度表中的列,但又有区别。更严格的来说,Attribute 实际上绑定的是来自于数据源视图中表或者视图中的一列或者多列。
Property 中文翻译通常也叫属性 - 这里的 Property 是指 Dimension Attribute 维度属性中针对每一个 Attribute 的配置属性。
DIM GEOGRAPHY - Dimension 维度。
COUNTRY - Dimension Attribute 维度属性。
Properties of COUNTRY DimensionAttribute - COUNTRY 的属性。
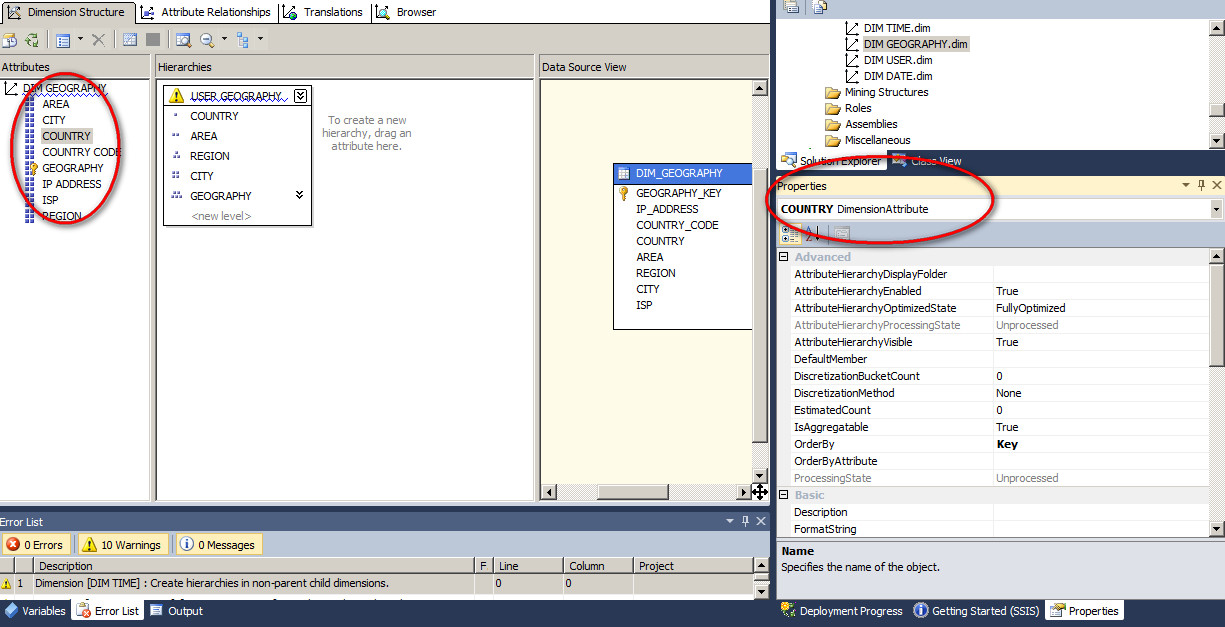
维度中的键属性
每一个维度都包含一个键属性 Key Attribute,通常这个 Key Attribute 来源于数据源视图 DSV 中维度表的主键列(有的维度表如果没有设置物理主键,可以在 DSV 中设置逻辑主键)。
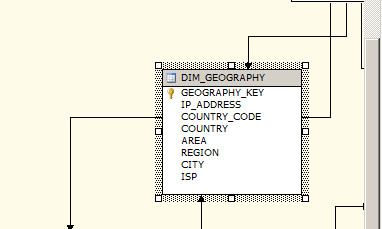
数据源视图中的 DIM_GEOGRAPHY 维度表,GEOGRAPHY_KEY 是这个维度表的主键,当在 SSAS 中创建 DIM_GEOGRAPHY 维度的时候,这个 GEOGRAPHY_KEY 默认就成了 GEOGRAPHY 维度的键属性对象 Key Attribute。
这个主键列会在属性的 Properties 的 Key Columns 中默认呈现,Key Column 可以是一列或者多列(即键属性表示原维度表中的一个或者多个主键列),同时在 Properties 中还可以看到比如 Name Column 中绑定的是来源于 DSV 同表或者视图中另外的列。这就是前面所解释到的,一个 Dimension Attribute 实际上是绑定到维度表中的一列或者多列,这些配置就在 Dimension Attribute Properties 中来配置。
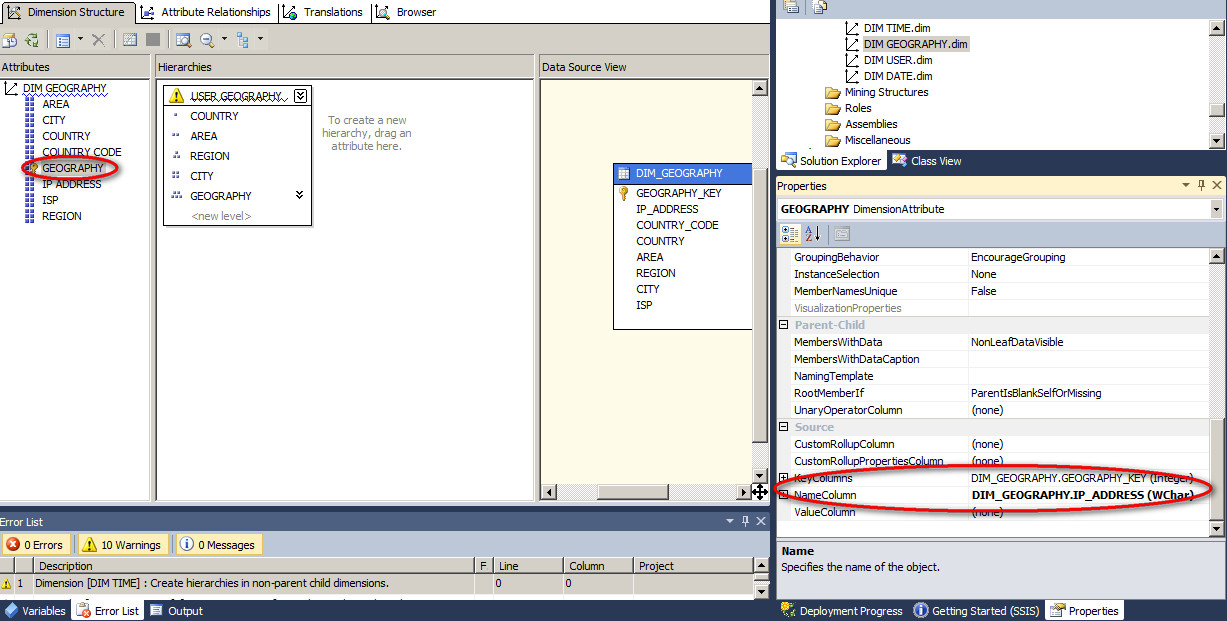
属性成员与属性层次结构
先来看下原始维度表 DIM_GEOGRAPHY 中 CITY 列中的数据。

再看看前面图片中 CITY 列在 SSAS DIM GEOGRAPHY 中的位置,数据库中 CITY 列变成了 SSAS DIM GEOGRAPHY 维度中的一个维度属性 Dimension Attribute,而数据库中 CITY 列中的值 (DISTINCT 后的值) 在 SSAS 中就转化成了 CITY 属性的属性成员 Attribute Member。
不同的是,在 SSAS 维度设计中,会将属性成员 Attribute Member 组织到两个级别的层次结构中,一个是 All 级别,一个是叶级别 Leaf level,叶级别对应的成员就源自数据库表中 CITY 列。
All 级别的作用是什么呢,简单举例子来说比如有一个注册人数度量值(来自事实表),上海的注册人数是10人,上饶的注册人数是20人,东莞的注册人数是15人。All 这个级别的含义就是每一个与 All 下面的属性成员对象(上海、上饶、东莞.....)关联的注册人数的聚合值(10+20+15), 即 All 级别对应的注册人数就是 45 人。PS:聚合的方式有很多种,这里默认提到的是 SUM 汇总。
所以维度包含什么?维度包含:属性和由属性构成的层次结构(含有 All 的两层结构)。
用户自定义层次结构
用户根据需要将不同的维度属性按照一定的规则组织成的一种结构,目的是为了更好的导航和钻取数据。
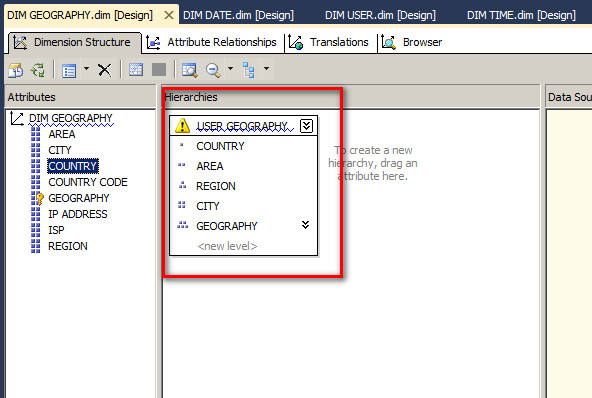
这种层次结构在汇总数据的时候更符合大家的习惯,自然性的按照一定的层次进行上卷汇总或者下钻展开查看子级别的汇总数据。通常情况下,这种层次结构之间的属性对应关系是一对一或者一对多的关系,通过更合理的属性关系设置可以提高处理性能节省内存,对于大型或者复杂的多维数据集处理非常有用。
默认情况下,在星型架构中,所有属性都直接与键属性相关,用户可以根据维度中的任意属性层次结构浏览多维数据集中的事实数据。
(可以查看这篇文章了解更多内容 - 微软BI 之SSAS 系列 - 维度的优化、灌木丛属性关系、以及自然层次结构与非自然层次结构的概念
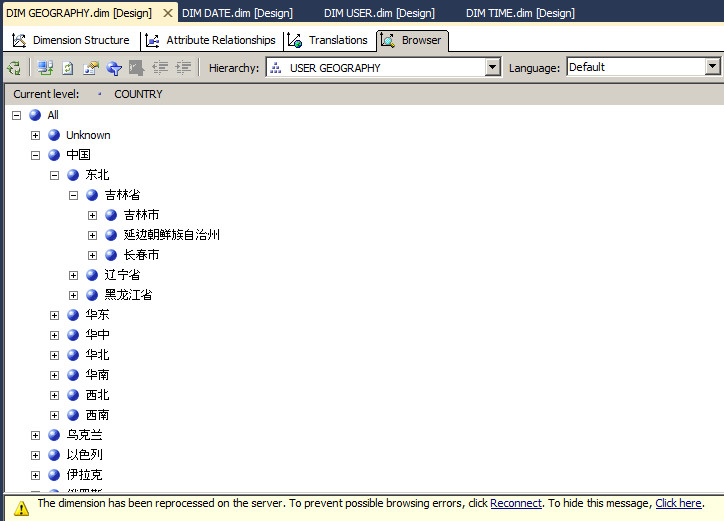
所以再总结下,维度包含属性、属性层次结构和用户自定义的属性层次结构,每一个属性都默认包含一个带有 All 级别的两层结构。
Dimension Attribute Properties 详解
请暂且忽略下面所有所有示例中出现的一些不合理的小设计,比如有些属性实际上需要优化删除或者隐藏掉,或者设置成维度 Property,对分析用途不大。
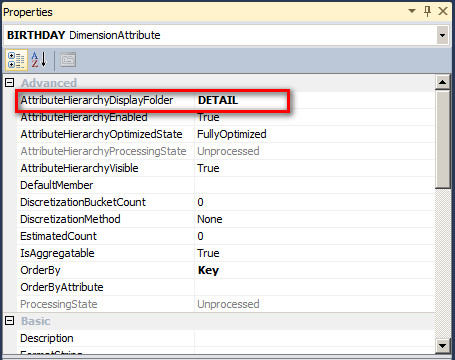
AttributeHierarchyDispalyFolder
用来给属性层次结构分组,特别是当一个维度有很多属性的时候,这样分组可以让分析人员更方面的找到对应常用的属性层次结构。
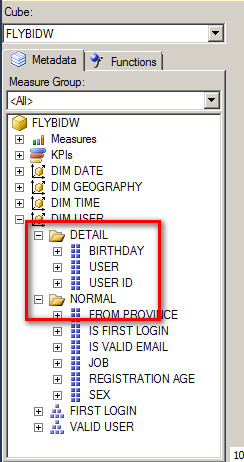
比如部署之后在分析服务查询中可以看到分组效果。
AttributeHierarchyEnabled
启用或禁用属性层次结构 True 或 False,默认为 True,但是实际上不是每一个维度中的属性都有分析的价值和必要。尽管在 SSAS 分析服务中是可以支持很多维度和属性,但是实际上这会消耗处理性能并且对于终端用户来说作用也不大,这些维度属性可以先考虑将 AttributeHierarchyEnabled 设置为 False。
实际上更好的处理方式应该是在一开始设计维度的时候就弄清楚哪些维度属性用户可能会用到,不会用到的属性一律不考虑放入维度中,如果以后有需要加上即可。
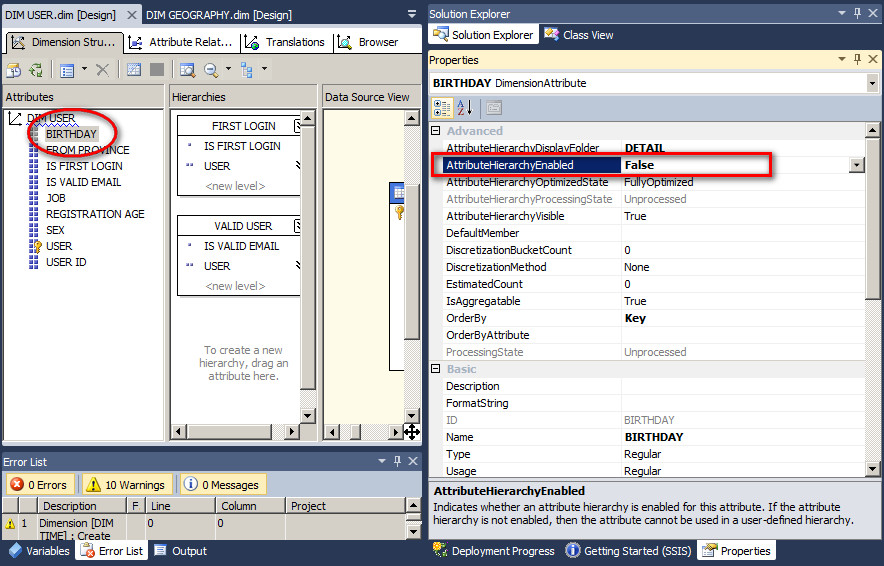
BIRTHDAY 这个属性层次结构将不会出现,在 MDX 查询中也将不可见。建议其它不必要的维度属性也可以 Disable 掉或者在确定完全不会用到的情况下可以删除掉。
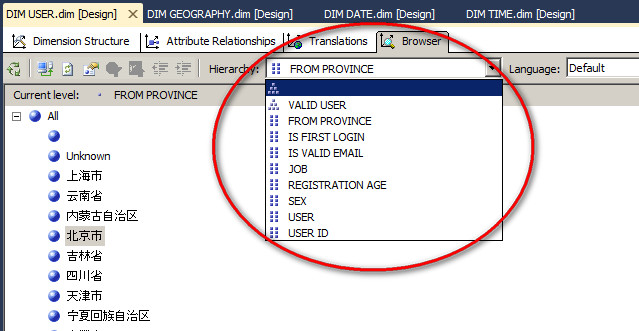
需要注意的就是一旦某一个属性被禁用了,那么将不能使用它创建自定义的属性层次结构。

哪些属性应该被禁用? 比如例如像客户维度中的电话、地址、描述信息等这些基本上没有太多的分析价值或者说用来做分组切片的价值,禁用之后这些维度属性将不可见,但会变为维度成员的 Member Property 以附加信息的方式来展现,这些在 MDX 查询中都可以访问的到。
AttributeHierarchyOptimizedState
有两个选项 FullyOptimized 和 NotOptimized,默认情况下所有的属性层次结构都是 FullyOptimized 状态。其作用就是 SSAS 分析服务会为属性层次结构生成索引以提高查询性能,既然是会创建生成索引结构那么就意味着在处理维度和属性层次结构的时候会消耗更多的资源。因此对于一些不常用的分析频率不高的属性层次结构可以考虑设置 AttributeHierarchyOptimizedState = NotOptimized,这样就不会在处理维度的时候为这个属性层次结构生成索引,加快处理速度。但是反过来如果用户利用其查询分析的时候可能就需要花费额外的时间,因此这一点需要大家去权衡。有一个比较常见的案例就是有些属性不用做分析用途,但是可能是帮助其它的属性进行排序,这个时候就可以设置为 NotOptimized 值。
AttributeHierarchyVisible
用来设置对客户端程序是否可见,默认为 True。设置为 False 只是说对客户端浏览不可见,包括 SSAS 中的 Browser 不可见,但是仍然可以用在用户自定义的属性层次结构中,包括也可以在 MDX 中查询使用。
以下将 USER ID 的 AttributeHierarchyVisible 属性设置为 False。
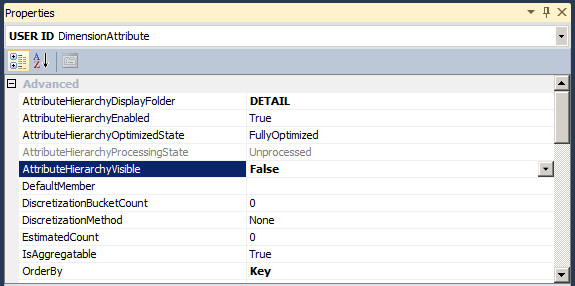
仍然可以创建自定义的属性层次结构。
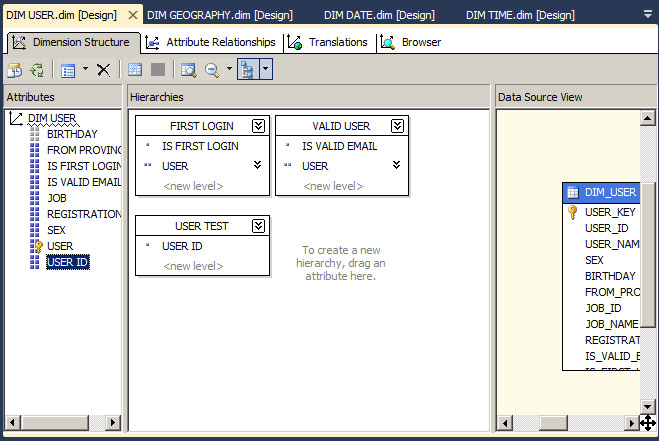
也可以通过 MDX 查询,但是是无法直接浏览看到的。
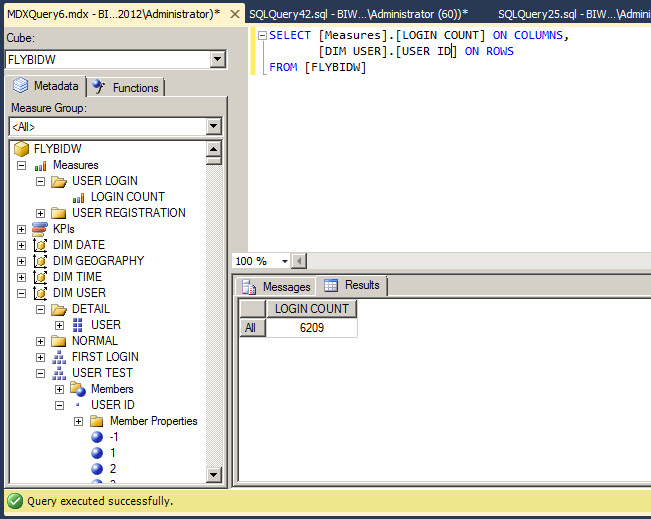
比如像一些属性本身就已经是自定义属性层次结构的一部分,可以选择设置不可见避免冗余。
DefaultMember
默认成员的作用是为维度属性指定一个默认的成员(值)。如果没有指定默认成员,默认就是 All 成员。
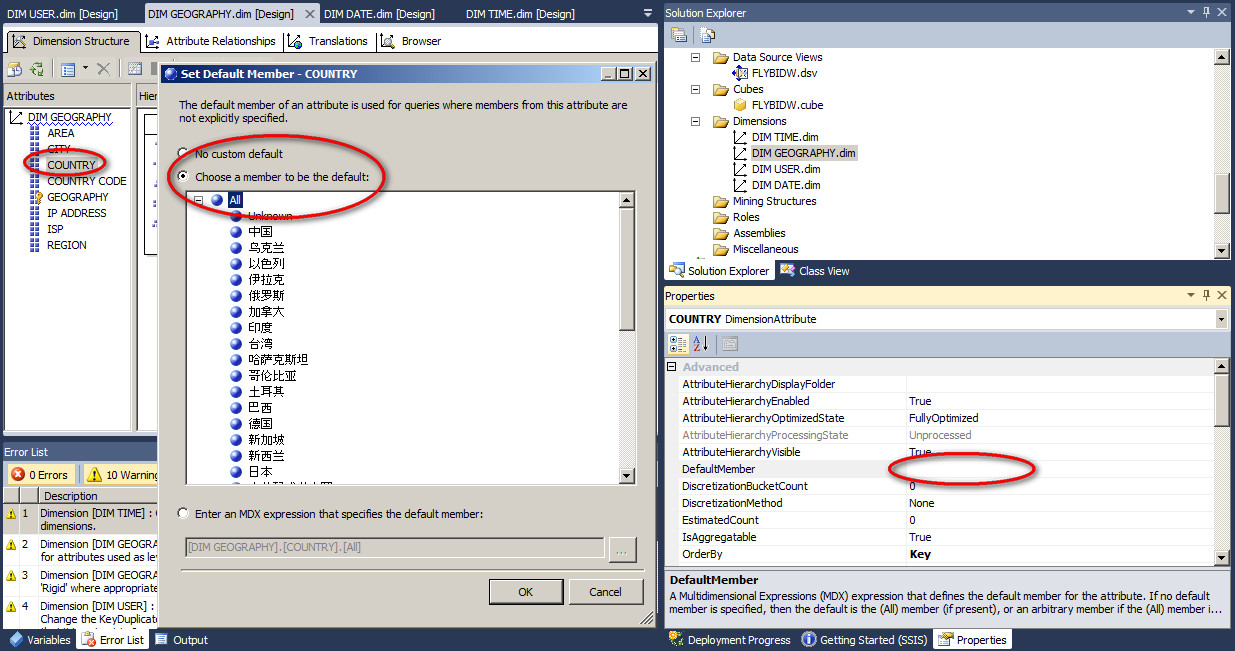
比如这里设置 COUNTRY 的默认成员是中国。

这一部分内容如果结合 MDX 的概念来看会理解的更加清楚一些,参考我的另外一篇博客 MDX Step by Step 读书笔记(三) - Understanding Tuples (理解元组) ,摘录如下:
局部元组(Partial Tuple) – 对比元组 Tuple而言,在局部元组中有一个或者多个成员的引用被忽略掉了,没有显式的写出来。一个完整的元组可以定位到Cube空间的一个点,Analysis Services 在处理局部元组的时候将会按照一定的规则去自动的填充在局部元组中被忽略掉的成员引用: 1. 如果成员引用被忽略,将使用属性的默认成员(即这个属性的默认值) 2. 如果成员引用被忽略并且这个成员没有默认值,那么将使用这个属性的 All 成员。 3. 如果成员引用被忽略,成员没有默认值也没有All 这个成员,那么就使用这个属性的第一个成员(这个属性下所有值集合中的第一个值)。
DiscretizationBucketCount DiscretizationMethod
可以通过离散化的方式将属性成员 Attribute Member 进行分组,层次结构中的级别要么包含成员组要么包含成员,二者只能选其一。通过分组之后生成的成员为分组成员,具体的属性成员将不存在。
比如将以下 REGISTRATION_AGE 的 DiscretizationMethod 设置为 Automatic 的时候,REGISTRATION_AGE 将呈现有 SSAS 通过离散化算法对属性成员自动分组。

在维度浏览器中显示的 REGISTRATION_AGE 自动分组产生分组成员,All 级别还是保留,但是具体的数值已经被自动分类。这种方式可能对大量的这种数值系列可能有所帮助,让它们自动按照一定算法分组。但是个人还是比较喜欢自己控制这种分组,比如在数据源视图中进行分组转换类似于 CASE WHEN 的形式,或者在源维度表中就预先转换好这种分组。
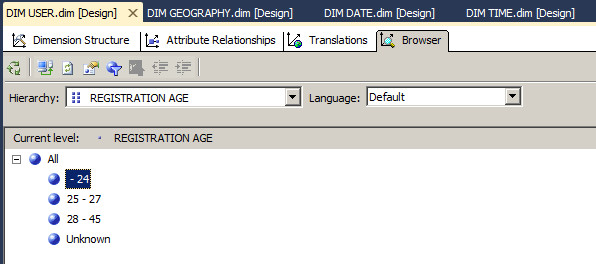
DiscretizationMethod - NONE,显示成员不分组; Automatic 自动分组;EqualAreas 将属性中的成员分成若干个数量相同的成员组;Clusters 抽样分组。
