背景
特么的一个客厅的隔断要涨到2200!!!!!!
版本
python 2.7
前置条件
requests和beautifulsoup4的包包
代码
import types
import requests
from bs4 import BeautifulSoup
output = open('ganji.txt','w')
res = requests.get('http://bj.ganji.com/fang1/lishuiqiao/a1h3m1/') #lishuiqiao
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
for fangzi in soup.select('.f-list-item '):
# title and url
size = ''
dd_title = fangzi.dl.find_all('dd',"dd-item title")
if dd_title[0].a['href'][0:1] == '/':
url = 'http://bj.ganji.com' + dd_title[0].a['href'].encode('utf8')
else:
url = dd_title[0].a['href'].encode('utf8')
title = dd_title[0].text.strip().encode('utf8')
# size
dd_size = fangzi.dl.find_all('dd', "dd-item size")[0].contents
for i in dd_size:
if type(i) == type(fangzi):
if len(i.text) > 0:
size += i.text.encode('utf8') + ' '
# price
dd_price = fangzi.dl.find_all('dd',"dd-item info")
price = dd_price[0].text.encode('utf8')
# print title
print title # debug
output.write(title+'\r\n') # write to file
# print size
print size
output.write(size+'\r\n') # write to file
# print price
print price
output.write(price + '\r\n') # write to file
# print url
print url
print '=========================================='
output.write(url+'\r\n') # write to file
output.write( '==========================================\r\n')
output.close()
我这里是从赶集网上搞的,
res = requests.get('http://bj.ganji.com/fang1/lishuiqiao/a1h3m1/') #lishuiqiao
第4行这段url可以把中间的lishuiqiao改成huoying(霍营)、xierqi(西二旗)等等(限北京,其他地区要把bj也改掉),亲测有效。
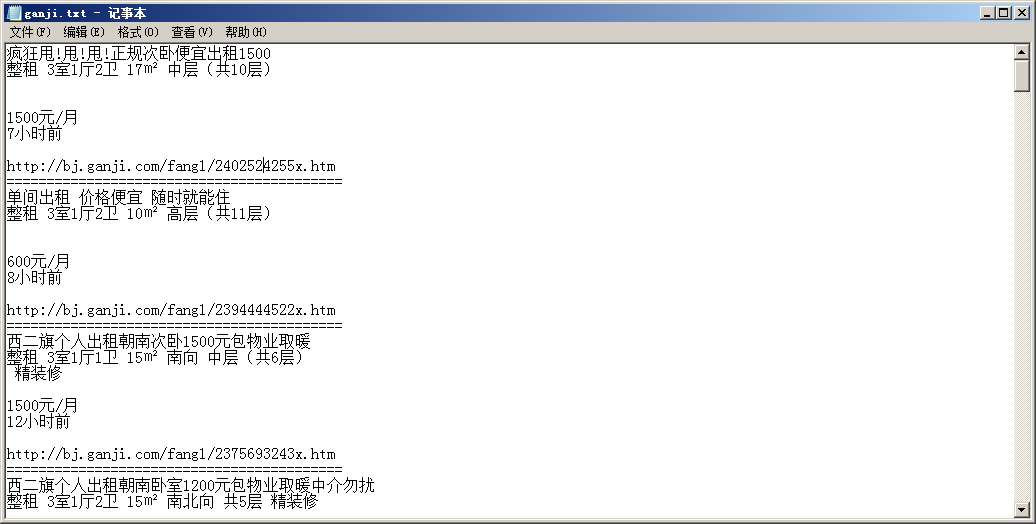
测试截图