1.hive数据库和表查看
hive> show databases;
OK
default
tpc
hive> use tpc;
OK
hive> show tables;
OK
call_center
catalog_page
catalog_returns
catalog_sales
customer
customer_address
customer_demographics
date_dim
dbgen_version
household_demographics
income_band
inventory
item
promotion
reason
ship_mode
store
store_returns
store_sales
time_dim
warehouse
web_page
web_returns
web_sales
web_site
2.Zeppelin启动和spark配置
[root@SZB-L0032016 local]# cd /usr/local/zeppelin-0.6.2-bin-all/bin
[root@SZB-L0032016 bin]# ./zeppelin-daemon.sh start
3.spark配置
|--web访问
http://zeppelin:8080/ --> interpreter
master:安装spark集群地址
spark.cores.max : 每个节点最大核数
spark.executor.memory : 每个节点最大内存

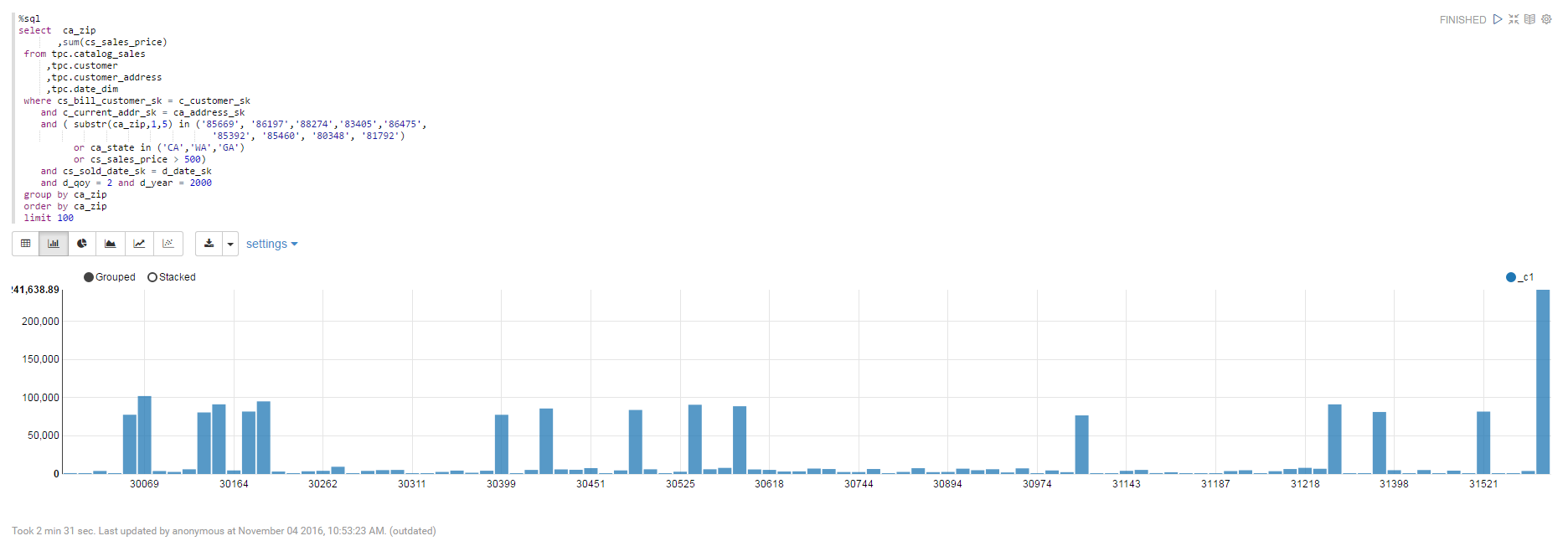
4.新建notebook为chart_demo
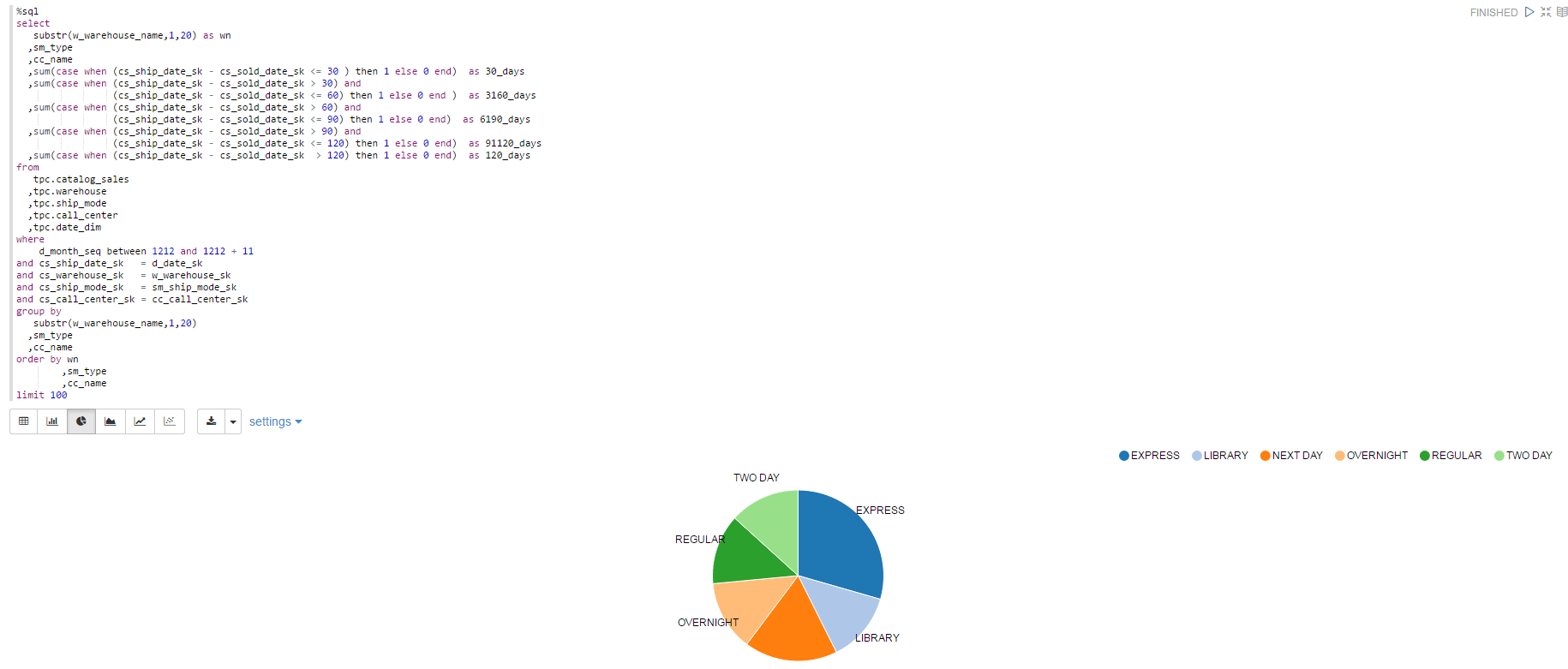
展示饼图:
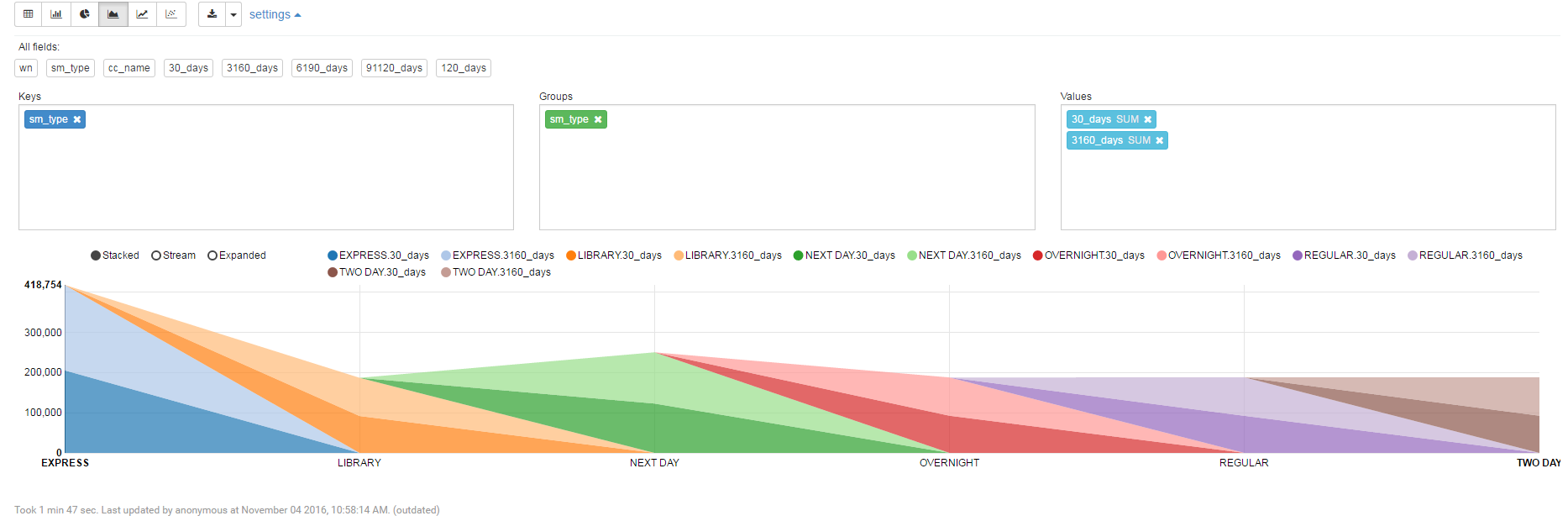
基于拖拽开发图表: