预备阅读:Python中lxml库的用法
前言
前面已经学习了Python的lxml库,从库的名称来看,lxml包含了xml,所以lxml同样可以解析XML文档,而lxml使用的就是XPATH语法。下面做一下简单介绍。
XPath语法
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和XPointer 都构建于 XPath 表达之上。因此,对 XPath 的理解是很多高级 XML 应用的基础。
在继续学习之前,应该对下面的知识有基本的了解(默认同学们都会了,不知道的同学可以去看一下,很简单的):
HTML / XHTML
XML / XML 命名空间
XPath 术语
节点(Node)
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
基本值(或称原子值,Atomic value)
基本值是无父或无子的节点。
基本值的例子:
J K. Rowling
"en"
项目(Item)
项目是基本值或者节点。
节点关系
(1)父(Parent)
每个元素以及属性都有一个父。
在下面的例子中,book 元素是 title、author、year 以及 price 元素的父:
(2)子(Children)
元素节点可有零个、一个或多个子。
在下面的例子中,title、author、year 以及 price 元素都是 book 元素的子:
(3)同胞(Sibling)
拥有相同的父的节点
在下面的例子中,title、author、year 以及 price 元素都是同胞:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
(4)先辈(Ancestor)
某节点的父、父的父,等等。
在下面的例子中,title 元素的先辈是 book 元素和 bookstore 元素:
(5)后代(Descendant)
某个节点的子,子的子,等等。
在下面的例子中,bookstore 的后代是 book、title、author、year 以及 price 元素:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式:
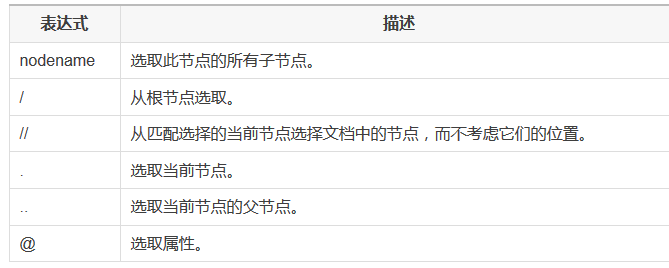
实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:

谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
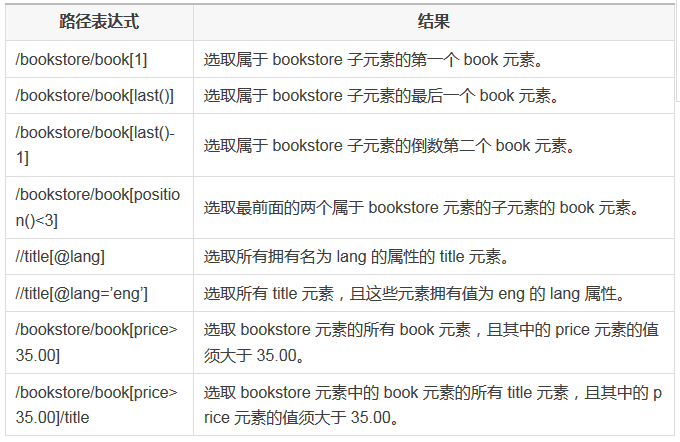
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
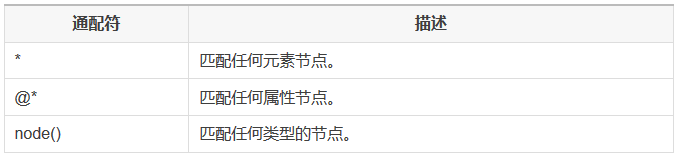
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:

选取若干路径
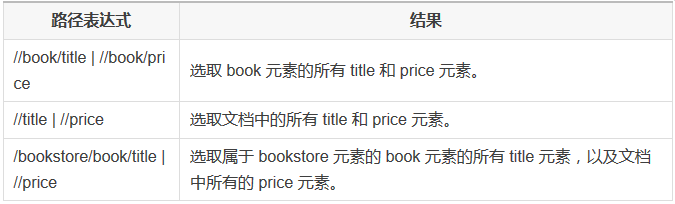
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
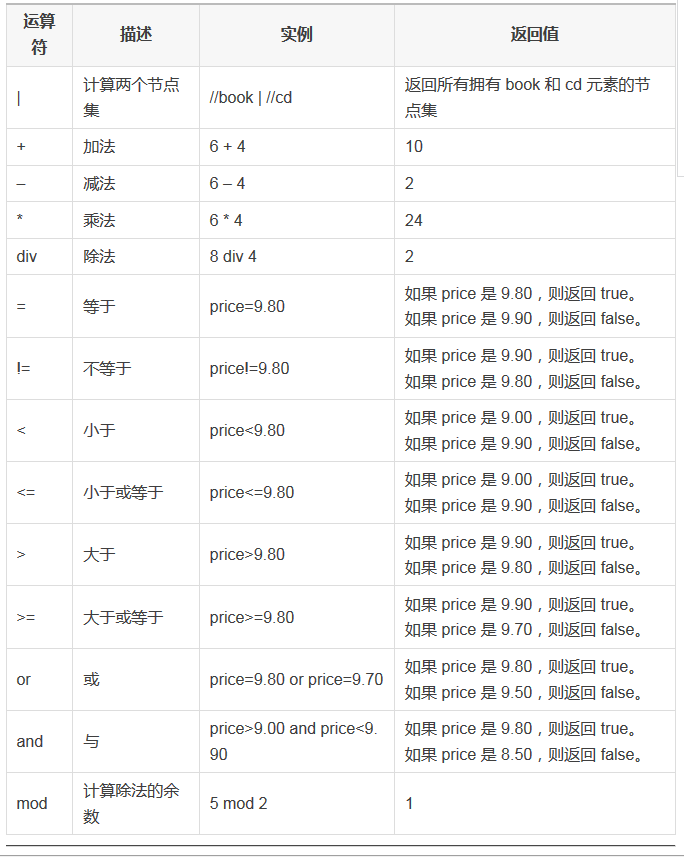
XPath 运算符
下面列出了可用在 XPath 表达式中的运算符:
小结
上面就是XPATH的语法知识了,这用在lxml库里很方便,快速。希望大家能学到对自己有用的知识。
希望通过上面的内容能帮助大家。如果你有什么好的意见,建议,或者有不同的看法,我都希望你留言和我们进行交流、讨论。
如果想快速联系我,欢迎关注微信公众号:AiryData。

欢迎访问原文链接查看更多精彩。Python的lxml库学习之XPATH语法

