版本:Oracle 11.2.0.4.0
操作系统:linux redhat 6.4
场景:
测试环境,查询存储过程运行监控日志发现,其中有报错信息如下:ERROR CODE -1652: ORA-01652: 无法通过 128 (在表空间 TEMP1 中) 扩展 temp 段。
同时执行脚本查看占用产生临时段的sql_id,测试环境临时表空间共两个数据文件,为62个G ,而执行该脚本便占用了60个G,难怪会报 ORA-01652。
a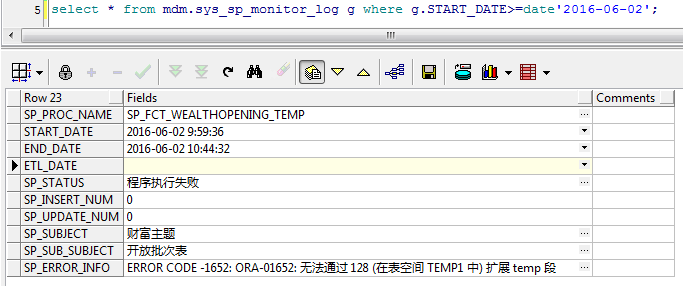
b

补充:发现该存储执行占用临时段的类型对应的可能执行操作如下:
SORT:SQL排序使用的临时段,包括order by、group by、union、distinct、窗口函数(window function)、建索引等产生的排序。
DATA:临时表(Global Temporary Table)存储数据使有的段。
INDEX:临时表上建的索引使用的段。
HASH:hash算法,如hash连接所使用的临时段。
LOB_DATA和LOB_INDEX:临时LOB使用的临时段。
省略废话,找到该存储过程经过分析,该存储是一段长达400多行的代码,其中是两段代码 采用UNION ALL ,找到其中执行慢的一段,查看其执行计划如下,(执行大概五分钟未出数,直接关掉)
采用statistics level=all的方式收集
Starts为该sql执行的次数。
E-Rows为执行计划预计的行数。
A-Rows为实际返回的行数。A-Rows跟E-Rows做比较,就可以确定哪一步执行计划出了问题。
A-Time为每一步实际执行的时间(HH:MM:SS.FF),根据这一行可以知道该sql耗时在了哪个地方。
Buffers为每一步实际执行的逻辑读或一致性读。
Reads为物理读。
OMem:当前操作完成所有内存工作区(Work Aera)操作所总共使用私有内存(PGA)中工作区的大小,
这个数据是由优化器统计数据以及前一次执行的性能数据估算得出的
1Mem:当工作区大小无法满足操作所需的大小时,需要将部分数据写入临时磁盘空间中(如果仅需要写入一次就可以完成操作,
就称一次通过,One-Pass;否则为多次通过,Multi_Pass).该列数据为语句最后一次执行中,单次写磁盘所需要的内存
大小,这个由优化器统计数据以及前一次执行的性能数据估算得出的
User-Mem:语句最后一次执行中,当前操作所使用的内存工作区大小,括号里面为(发生磁盘交换的次数,1次即为One-Pass,
大于1次则为Multi_Pass,如果没有使用磁盘,则显示OPTIMAL)
OMem、1Mem为执行所需的内存评估值,0Mem为最优执行模式所需内存的评估值,1Mem为one-pass模式所需内存的评估值。
0/1/M 为最优/one-pass/multipass执行的次数。Used-Mem耗的内存
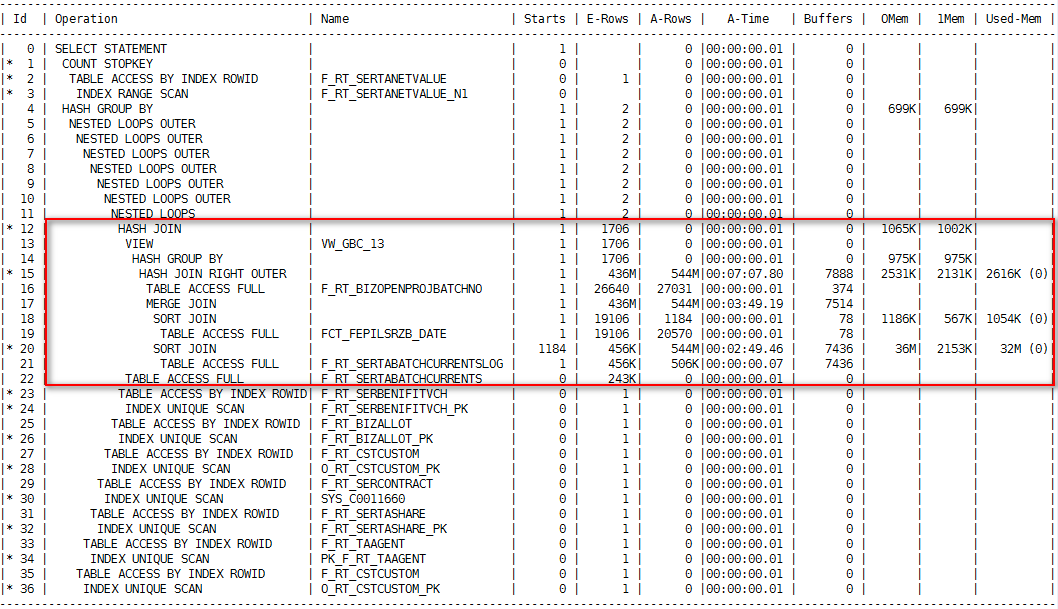
全部执行计划如下: 其中引起占用临时段为Sort 的原因是采用了 SORT GROUP BY :通过对数据进行排序,以进行分组操作。 可以从Order 为10 发现其中CBO基于统计信息估计该操作返回63个G。而根据执行计划顺序,可以知道表F_RT_SERTABATCHCURRENTSLOG 会和FCT_FEPILSRZB_DATE 做关联结果如下,这样明显是不明智,所以有理由根据上面的E-Rows 和A-Rows 差异和执行计划的顺序的判定,需要对表重新进行分析。
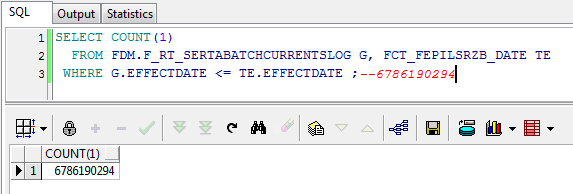
而从收集信息也可以确定。

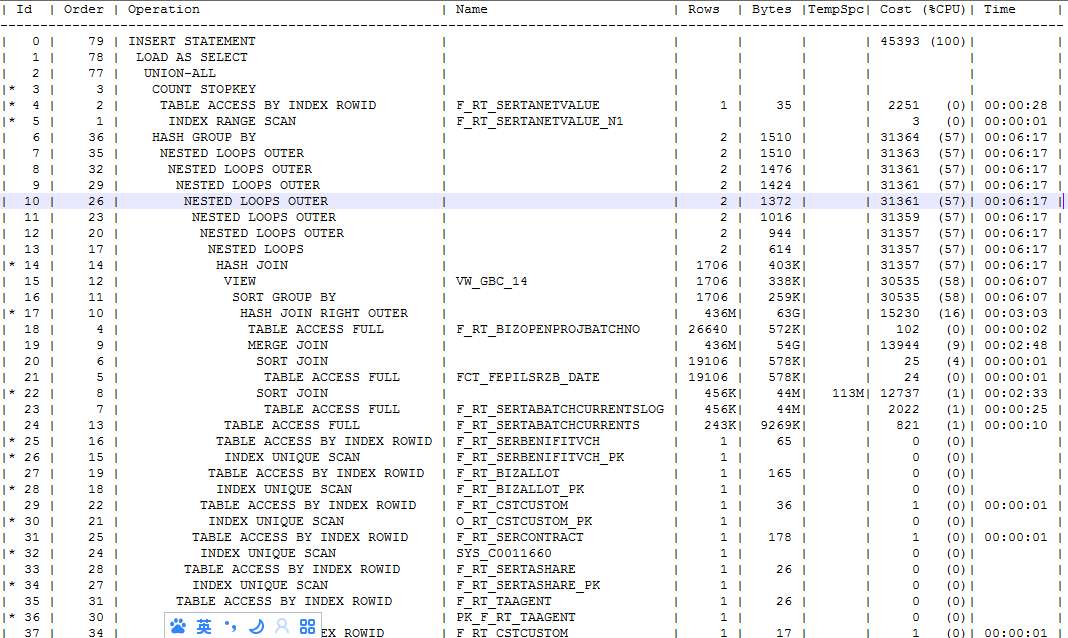
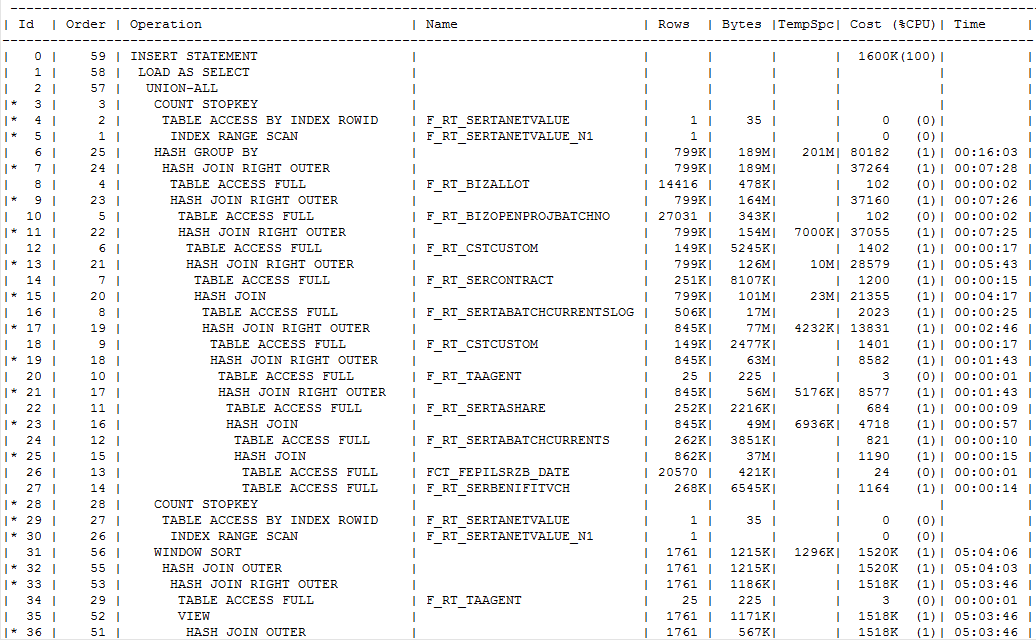
存储全部的执行计划如下,请关注Sort Group BY 执行计划顺序 Order 1 到11 注:截图部分执行计划。全部执行计划见附件。
-------------------------------------------------------------------------------------------------------------------------------------
收集统计信息:
收集之前查看最后一次收集该表统计信息时间,居然发现没有收集过,后面会提到。
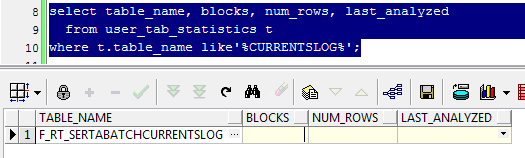
于是按照Schema 进行收集,脚本如下:
EXEC DBMS_STATS.gather_schema_stats(ownname => 'MDM', degree => 16,cascade => TRUE,method_opt => 'for all columns size repeat')
重新执行脚本
发现原本基本执行40分钟便会因为无法扩展临时段的而报错的存储,居然在28秒内完成,数据量为2684543.
查看新的执行计划
注:截图为部分执行计划,全部执行计划见附件。
根据执行计划顺序Order 可以发现,F_RT_SERTABATCHCURRENTSLOG 不会直接和FCT_FEPILSRZB_DATE 做关联。同时也没有SORT GROUP BY ,之前查询文档说 Hash Group by 优于 Sort Group BY 以后再验证。
问题原因:
没有及时收集统计信息,导致Oracle 做出错误的执行计划。另外在我们投产的时候,对于初始化的表数据也需要及时做表、分区、子分区 等信息收集。否则可能会因为实际数据量和统计信息存在差异导致CBO选择错误的执行计划。
补充:
后续将开启自动收集统计信息脚本如下
SQL> select window_name,autotask_status from DBA_AUTOTASK_WINDOW_CLIENTS s;
WINDOW_NAME AUTOTASK
------------------------------ --------
MONDAY_WINDOW DISABLED
TUESDAY_WINDOW DISABLED
WEDNESDAY_WINDOW DISABLED
THURSDAY_WINDOW DISABLED
FRIDAY_WINDOW DISABLED
SATURDAY_WINDOW DISABLED
SUNDAY_WINDOW DISABLED
7 rows selected.
执行如下命令:
SQL> execute DBMS_AUTO_TASK_ADMIN.enable();
PL/SQL procedure successfully completed.
SQL> select window_name,autotask_status from DBA_AUTOTASK_WINDOW_CLIENTS s;
WINDOW_NAME AUTOTASK
------------------------------ --------
MONDAY_WINDOW ENABLED
TUESDAY_WINDOW ENABLED
WEDNESDAY_WINDOW ENABLED
THURSDAY_WINDOW ENABLED
FRIDAY_WINDOW ENABLED
SATURDAY_WINDOW ENABLED
SUNDAY_WINDOW ENABLED
7 rows selected.

