版本:IBM InfoSphere DataStage V11.3.1
操作系统:linux redhat 6.4
1.1 主要功能
JoinStage 用于在两个或多个输入数据集合上执行连接操作并输出一个结果数据集。
1.2 使用原理
JoinStage 通过将两个或多于两个的数据集进行Inner、Left Outer、Right Outer和 Full Outer关联,输出一个结果集。Join的处理遵循关系型数据库模型,如果发生重复会产生笛卡儿乘积,对于匹配不到的数据,没有Fail/Reject的方式捕获 ,但可以通过Rightouter、Left outer、 Full outer的方式捕获。
Join要求输入的数据集必须是基于关键字分区,并且是排过序的。这样才能保证具有相同关键字的行存在于同一个分区中,可以被一个节点处理。由于这种事先的排序减轻了Join的内存需求量,每次只有少量的行需要进入RAM。
1.3 使用需要注意
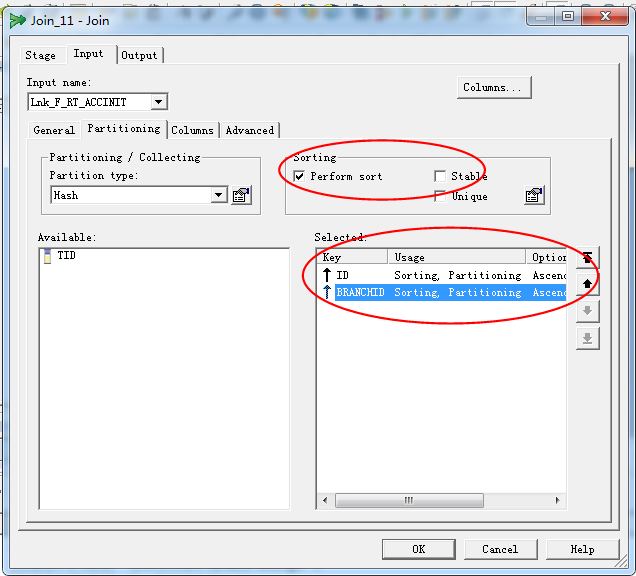
采用自定义分区的方式,必须注意:由于Join是基于分区进行关联的,错误分区将会导致错误的结果!使用自定义分区时必须十分小心,当采用Hash分区时,每个数据源分区的关键字必须包括且仅包括关联的关键字,不能包含各源表所独有的字段,同时,如果源表的数据是没有经过排序的,还需要选择Perform Sorting对其进行排序(是否进行排序不会影响关联结果的正确性,但对于大数据量情况,经过事先的排序可以加快关联的速度)。
1.4 案例测试:
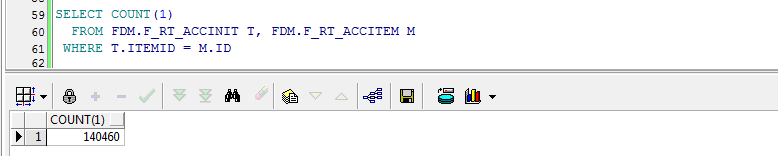
创建表FDM.F_RT_ACCINIT 表 和FDM.F_RT_ACCITEM 表 ID为关联字段
1:数据库查看关联结果集:
2:设置Partition Type :Hash 两个表都值选ID 计算散列值。
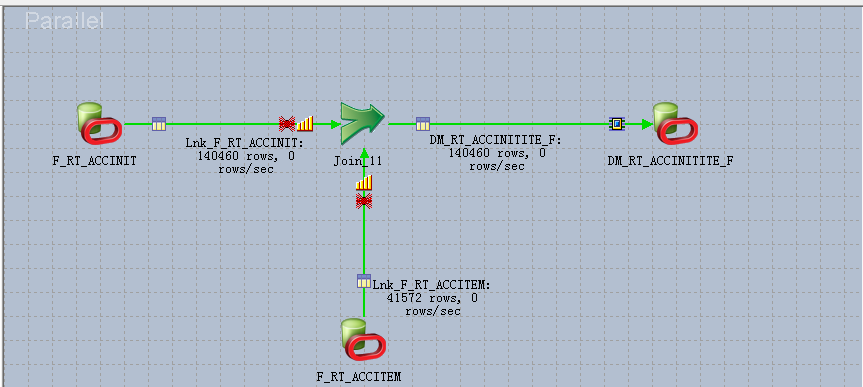
3:设置Partition Type :Hash 一个设置ID 另一个设置ID 加特有字段 计算散列值。


1.5 散列函数
作为分区方法的一部分,您可以选择根据记录字段(称为散列键)计算散列值。
InfoSphere DataStage 提供了分区散列函数 APT_hash() 的多个重载,用于处理大多数可用作散列键的数据类型。
APT_hash() 返回指定散列键的分区编号。 必须对 APT_hash() 返回的值执行模除运算,以确保该值大于等于 0 但小于相应 Dataset 的最大分区编号。
通常,当您从 APT_Partitioner 派生自己的分区方法时,将从 APT_Partitioner::partitionInput() 中调用 APT_hash()。 InfoSphere DataStage 为最常用的数据类型提供 APT_hash() 的重载,如下所示
#include <apt_framework/orchestrate.h>
extern APT_UInt32 APT_hash(char key);
extern APT_UInt32 APT_hash(int key);
extern APT_UInt32 APT_hash(long key);
extern APT_UInt32 APT_hash(float key);
extern APT_UInt32 APT_hash(double key);
extern APT_UInt32 APT_hash(const char * key,
bool caseSensitive = true);
extern APT_UInt32 APT_hash(const char * key, APT_UInt32 keyLength,
bool caseSensitive = true);
extern APT_UInt32 APT_hash(const APT_String& key,
bool caseSensitive = true );
extern APT_UInt32 APT_hash(const UChar* d, APT_UInt32 len,
bool caseSensitive=true);
extern APT_UInt32 APT_hash(const UChar* d,
bool caseSensitive=true);
extern APT_UInt32 APT_hash(const APT_UString& d,
bool caseSensitive=true);
extern APT_UInt32 APT_hash(const APT_RawField& d);
使用 key 参数指定散列键。 如果字符串不是以空值结束,请使用 keyLength 参数指定字符串的长度。 通过使用 caseSensitive 参数, 可以指定键表示区分大小写的字符串 (caseSensitive = true) 还是表示不区分大小写的字符串 (caseSensitive = false)。
除 APT_hash() 外,InfoSphere® DataStage® 还提供了针对十进制、日期、时间和时间戳记数据类型的散列函数:
APT_Decimal::hash()
APT_Date::hash()
APT_Time::hash()
APT_TimeStamp::hash()

