“觊觎”教务网不是一天两天了。。
之前试过selenium,结果失败。
昨天爬下来了,发现竟如此简单!
整个过程仅花核心代码30余行。
一、步骤
1、首先查看分析
打开界面是这样
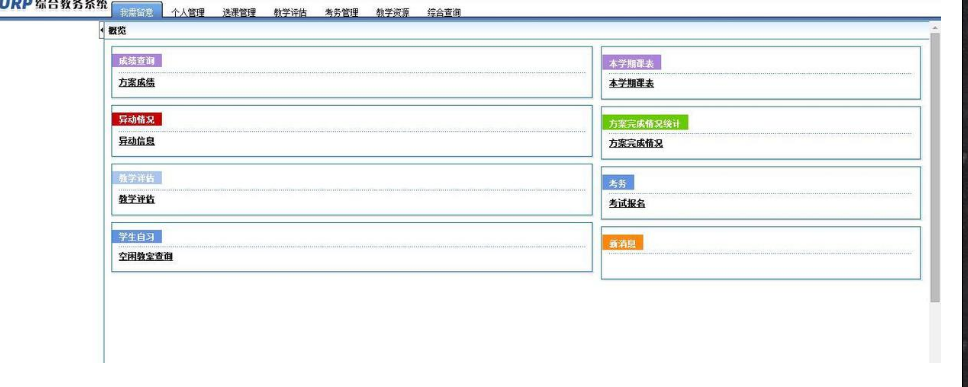
查看源码是这样
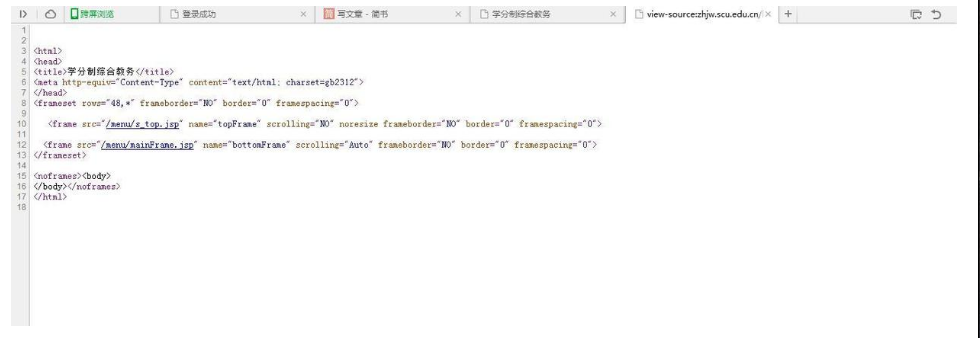
什么都没有,难怪用selenium定位不到了。估计还得配合PhantomJS来渲染页面,麻烦呀。于是想到抓包,一下就抓出来了。
2、抓包
抓包过程就不赘述,详情也可见我上一篇文章
http://www.jianshu.com/p/1f44a9a2ddd8
最终获得成绩的真实URL地址。
3、下载数据
最先是试着不登录,直接用requests获取抓包得到的URL,结果获得这一串
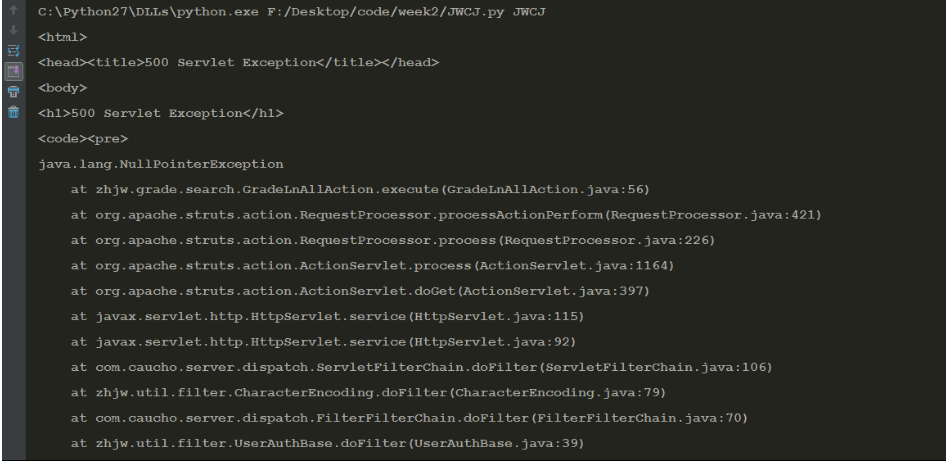
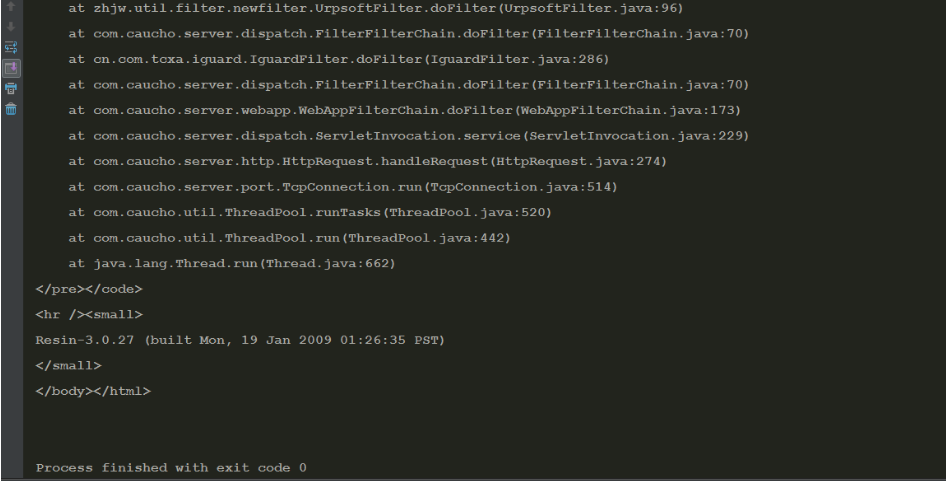
当时吓坏了我这个小白.。
上网查有说什么“空指针错误”的,狐疑。
后面设置headers,加上cookies,还开启Session,稀里糊涂通过。
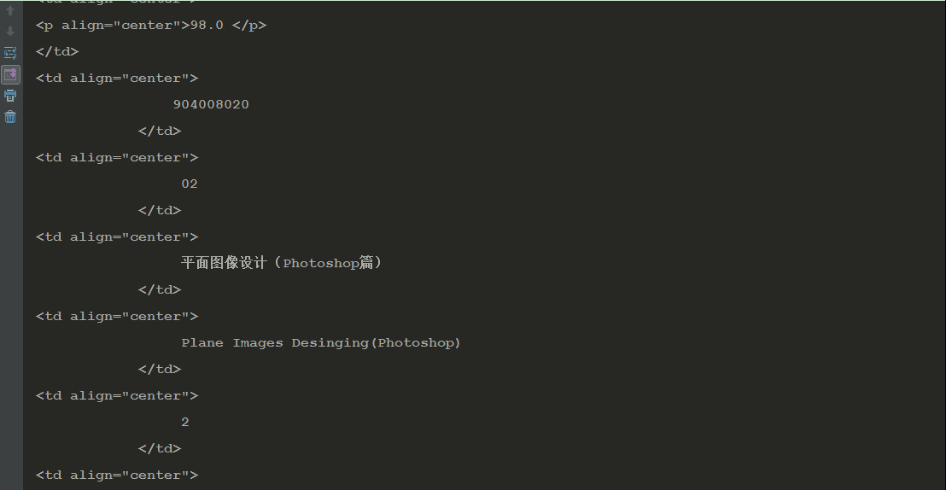
当时是想着抓包得到的URL可能是临时触发的,所以必须保持在一个会话中。
后面用network分析了下,果然如此,而且session会话只停留一定的时间。
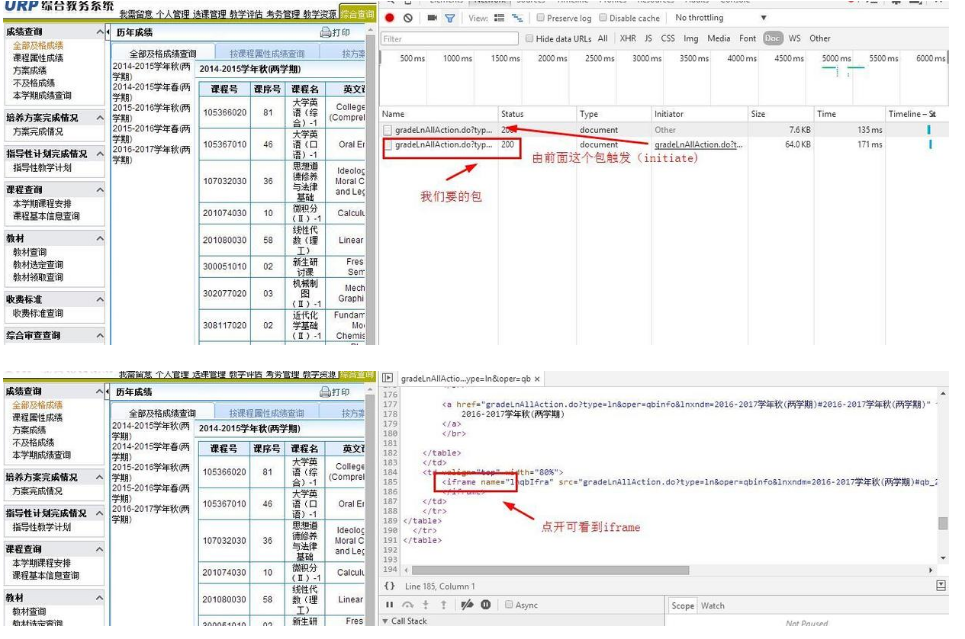
由此类推,先得打开成绩查询,才能触发前面这个包,然后触发我们要的包。
所以,还是得模拟登陆。
4、数据处理与保存
这里选择存入Excel。
看到一排排整齐的,于是用BeautifulSoup,text方法获取文本,所有的数据放入list中,简直完美。
数了下每一行有:课程号、课序号、课程名、英文名、学分、属性、分数共7项。
可这是一个大的list呀,
如何将数据“规整地”存入Excel?
// 嘿嘿,放点小招 //
data_list=[]
for data in content:
data_list.append(data.text.strip())
new_list=[data_list[i:i+7] for i in range(0,len(data_list),7)]
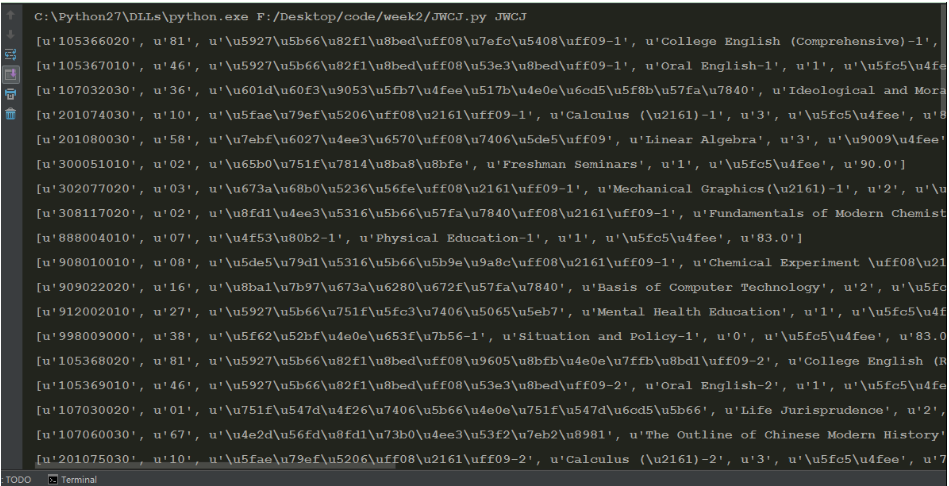
黑魔法的味道?哈哈哈我简直聪明(^_^)!
(当然不会告诉你是在stackoverflow上找到的)
有了这里铺垫,存入数据就简单了。
二、结果
如下所示
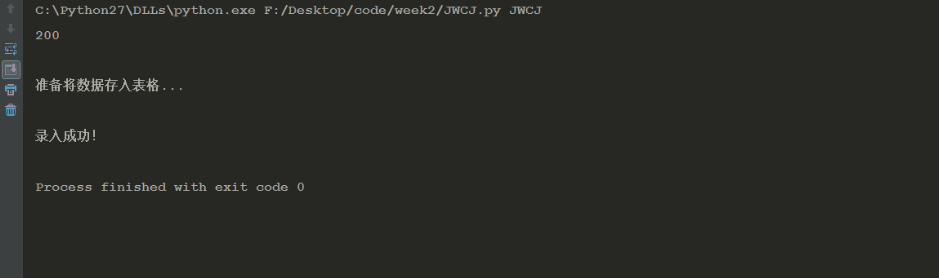
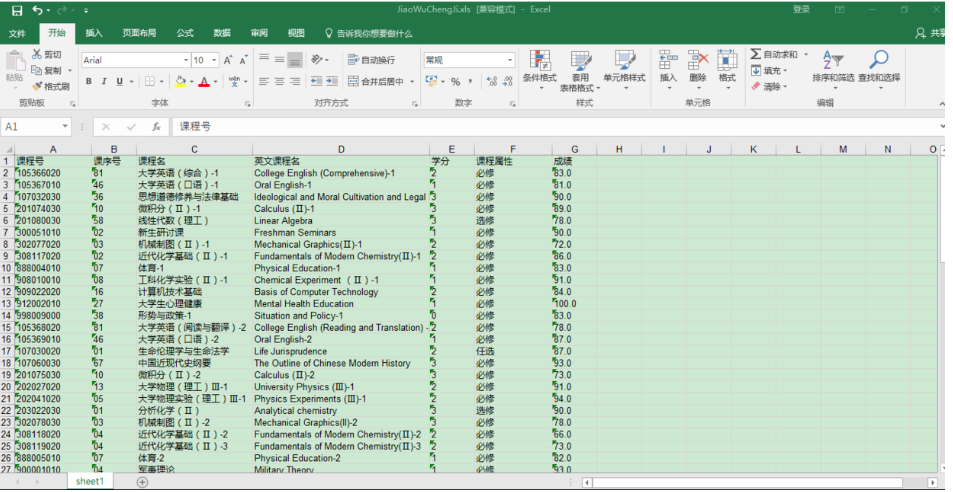
看了一下,从入学到现在,一共考了73科。
一不小心暴露学渣的本质。。。。。

三、代码
还是放完整版,方便查看:
# !usr/bin/env python
# -*-coding:utf-8 -*-
__author__='WYY'
__date__='2017.03.26'
#实战小项目:爬取教务网成绩并存入excel
import requests
import xlwt
from bs4 import BeautifulSoup
#模拟登录
formData={'zjh':'xxxxxxxxxxxxx','mm':'xxxxxx'}
s=requests.Session()
Post=s.post(url='http://zhjw.scu.edu.cn/loginAction.do',data=formData)
print Post.status_code
#获取基本信息
detailURL='http://zhjw.scu.edu.cn/gradeLnAllAction.do? type=ln&oper=qbinfo&lnxndm=2016-2017%D1%A7%C4%EA%C7%EF(%C1%BD%D1%A7%C6%DA)'
html=s.get(url=detailURL)
main=html.content.decode('gbk')
soup=BeautifulSoup(main,'lxml')
content=soup.find_all('td',align="center")
#将信息放入一个list中,创建new_list(方便后续存入excel)
data_list=[]
for data in content:
data_list.append(data.text.strip())
new_list=[data_list[i:i+7] for i in range(0,len(data_list),7)]
#数据存入excel表格
book=xlwt.Workbook()
sheet1=book.add_sheet('sheet1',cell_overwrite_ok=True)
heads=[u'课程号',u'课序号',u'课程名',u'英文课程名',u'学分',u'课程属性',u'成绩']
print u'\n准备将数据存入表格...'
ii=0
for head in heads:
sheet1.write(0,ii,head)
ii+=1
i=1
for list in new_list:
j=0
for data in list:
sheet1.write(i,j,data)
j+=1
i+=1
book.save('JiaoWuChengJi.xls')
print u'\n录入成功!'
也可看Github:
https://github.com/LUCY78765580/Python-web-scraping/blob/master/JWCJ.py
四、总结
总结这次爬虫的关键:
1、巧用抓包,找到成绩真实URL
2、模拟登录,并用Session保持会话
3、使用xlwt将数据写入excel
4、实用小技巧:new_list=[data_list[i:i+n] for i in range(0,len(data_list),n)]
最后这一项,简直堪称神奇的语法糖⊙ω⊙
本篇就是这样啦~
