1. 引言
Airflow是Airbnb开源的一个用Python写就的工作流管理平台(workflow management platform)。在前一篇文章中,介绍了如何用Crontab管理数据流,但是缺点也是显而易见。针对于Crontab的缺点,灵活可扩展的Airflow具有以下特点:
- 工作流依赖关系的可视化;
- 日志追踪;
- (Python脚本)易于扩展
对比Java系的Oozie,Airflow奉行“Configuration as code”哲学,对于描述工作流、判断触发条件等全部采用Python,使得你编写工作流就像在写脚本一样;能debug工作流(test backfill命令),更好地判别是否有错误;能更快捷地在线上做功能扩展。Airflow充分利用Python的灵巧轻便,相比之下Oozie则显得笨重厚拙太多(其实我没在黑Java~~)。《What makes Airflow great?》介绍了更多关于Airflow的优良特性;其他有关于安装、介绍的文档在这里、还有这里。
下表给出Airflow(基于1.7版本)与Oozie(基于4.0版本)对比情况:
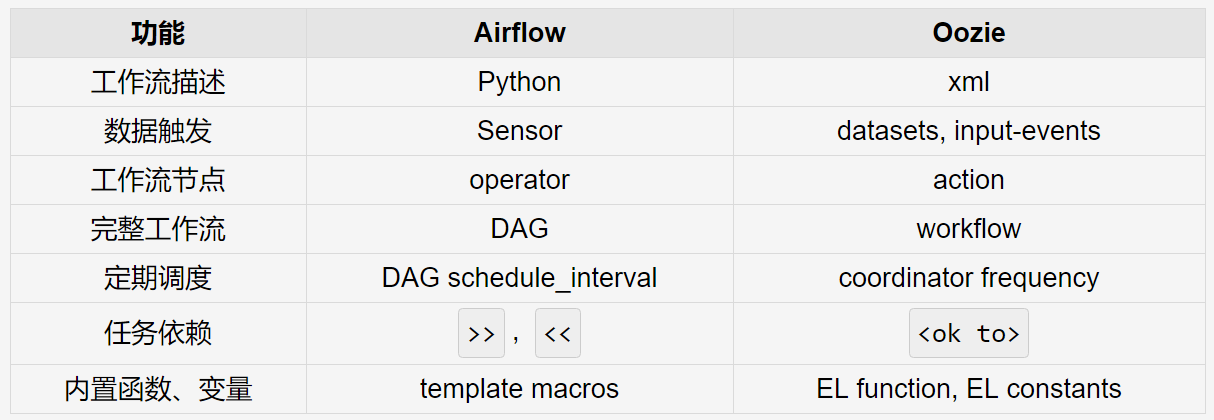
之前我曾提及Oozie没有能力表达复杂的DAG,是因为Oozie只能指定下流依赖(downstream)而不能指定上流依赖(upstream)。与之相比,Airflow就能表示复杂的DAG。Airflow没有像Oozie一样区分workflow与coordinator,而是把触发条件、工作流节点都看作一个operator,operator组成一个DAG。
2. 实战
Airflow常见命令如下:
- initdb,初始化元数据DB,元数据包括了DAG本身的信息、运行信息等;
- resetdb,清空元数据DB;
- list_dags,列出所有DAG;
- list_tasks,列出某DAG的所有task;
- test,测试某task的运行状况;
- backfill,测试某DAG在设定的日期区间的运行状况;
- webserver,开启webserver服务;
- scheduler,用于监控与触发DAG。
下面将给出如何用Airflow完成data pipeline任务。
首先简要地介绍下背景:定时(每周)检查Hive表的partition的任务是否有生成,若有则触发Hive任务写Elasticsearch;然后等Hive任务完后,执行Python脚本查询Elasticsearch发送报表。但是,Airflow对Python3支持有问题(依赖包为Python2编写);因此不得不自己写HivePartitionSensor:
from airflow.operators import BaseSensorOperator
from airflow.utils.decorators import apply_defaults
from impala.dbapi import connect
import logging
class HivePartitionSensor(BaseSensorOperator):
"""
Waits for a partition to show up in Hive.
:param host, port: the host and port of hiveserver2
:param table: The name of the table to wait for, supports the dot notation (my_database.my_table)
:type table: string
:param partition: The partition clause to wait for. This is passed as
is to the metastore Thrift client,and apparently supports SQL like
notation as in ``ds='2016-12-01'``.
:type partition: string
"""
template_fields = ('table', 'partition',)
ui_color = '#2b2d42'
@apply_defaults
def __init__(
self,
conn_host, conn_port,
table, partition="ds='{{ ds }}'",
poke_interval=60 * 3,
*args, **kwargs):
super(HivePartitionSensor, self).__init__(
poke_interval=poke_interval, *args, **kwargs)
if not partition:
partition = "ds='{{ ds }}'"
self.table = table
self.partition = partition
self.conn_host = conn_host
self.conn_port = conn_port
self.conn = connect(host=self.conn_host, port=self.conn_port, auth_mechanism='PLAIN')
def poke(self, context):
logging.info(
'Poking for table {self.table}, '
'partition {self.partition}'.format(**locals()))
cursor = self.conn.cursor()
cursor.execute("show partitions {}".format(self.table))
partitions = cursor.fetchall()
partitions = [i[0] for i in partitions]
if self.partition in partitions:
return True
else:
return False
Python3连接Hive server2的采用的是impyla模块,HivePartitionSensor用于判断Hive表的partition是否存在。写自定义的operator,有点像写Hive、Pig的UDF;写好的operator需要放在目录~/airflow/dags,以便于DAG调用。那么,完整的工作流DAG如下:
from airflow.operators import BashOperator
from operatorUD.HivePartitionSensor import HivePartitionSensor
from airflow.models import DAG
from datetime import datetime, timedelta
from impala.dbapi import connect
conn = connect(host='192.168.72.18', port=10000, auth_mechanism='PLAIN')
def latest_hive_partition(table):
cursor = conn.cursor()
cursor.execute("show partitions {}".format(table))
partitions = cursor.fetchall()
partitions = [i[0] for i in partitions]
return partitions[-1].split("=")[1]
log_partition_value = """{{ macros.ds_add(ds, -2)}}"""
tag_partition_value = latest_hive_partition('tag.dmp')
args = {
'owner': 'jyzheng',
'depends_on_past': False,
'start_date': datetime.strptime('2016-12-06', '%Y-%m-%d')
}
dag = DAG(
dag_id='tag_cover', default_args=args,
schedule_interval='@weekly',
dagrun_timeout=timedelta(minutes=10))
ad_sensor = HivePartitionSensor(
task_id='ad_sensor',
conn_host='192.168.72.18',
conn_port=10000,
table='ad.ad_log',
partition="day_time={}".format(log_partition_value),
dag=dag
)
ad_hive_task = BashOperator(
task_id='ad_hive_task',
bash_command='hive -f /path/to/cron/cover/ad_tag.hql --hivevar LOG_PARTITION={} '
'--hivevar TAG_PARTITION={}'.format(log_partition_value, tag_partition_value),
dag=dag
)
ad2_hive_task = BashOperator(
task_id='ad2_hive_task',
bash_command='hive -f /path/to/cron/cover/ad2_tag.hql --hivevar LOG_PARTITION={} '
'--hivevar TAG_PARTITION={}'.format(log_partition_value, tag_partition_value),
dag=dag
)
report_task = BashOperator(
task_id='report_task',
bash_command='sleep 5m; python3 /path/to/cron/report/tag_cover.py {}'.format(log_partition_value),
dag=dag
)
ad_sensor >> ad_hive_task >> report_task
ad_sensor >> ad2_hive_task >> report_task
