本文介绍密度估计的 EM(Expectation-Maximization,期望最大)。
假设有 {x(1),...,x(m)},因为是无监督学习算法,所以没有 y(i)。
我们通过指定联合分布 p(x(i),z(i))=p(x(i)|z(i))p(z(i)) 来对数据建模。这里 z(i)~Multinomial(Φ),其中 Φj≥0,Φ1+Φ2+...+Φk=1,参数 Φj 给定 p(z(i)=j),x(i)|z(i)=j~N(μj,∑j)。k 表示 z(i) 能取的值的个数,所以,通过从 {1,...,k} 中随机选择 z(i),x(i) 从 k 个依赖于 z(i) 的高斯中生成。这就是高斯混合模型。z(i) 是隐随机变量,它们是隐藏的,这增大了估计问题的难度。
模型的参数是 Φ,μ 和 ∑,为对它们做估计,数据的似然为:
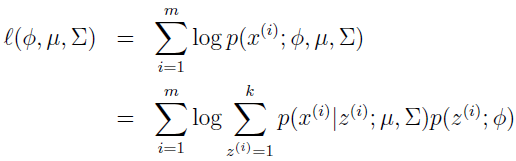
如果通过对参数求导并设为 0 来解,会发现不可能在封闭形式中找到最大似然估计。
随机变量 z(i) 表示 x(i) 来自 k 个高斯分布中的哪一个,如果知道 z(i) 的值,最大似然估计问题就简单了

最大化后参数为:
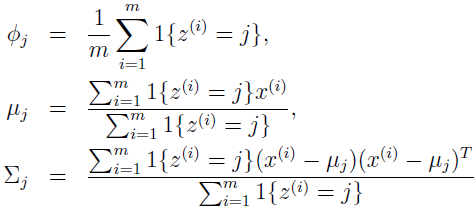
可以看到,如果知道 z(i),最大似然估计就跟高斯判别分析模型的参数估计差不多,除了 z(i) 扮演类标识的角色。
尽管如此,在我们的密度估计问题中,z(i) 是未知的,怎么办?
EM 算法是一个迭代算法,主要分两步:在 E 步,猜测 z(i) 的值;在 M 步,基于猜测更新模型的参数。因为在 M 步假装第一步是正确的,最大化就变简单了。这是算法:


在 E 步,给定 x(i),使用当前参数,用贝叶斯规则计算 z(i) 的后验概率。
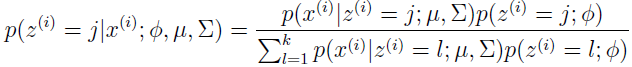
其中 p(x(i)|z(i)=j;μ;∑) 是由 x(i) 的以 μj 为均值和 ∑j 为方差的高斯密度估计出来的;p(z(i)=j;Φ) 是由 Φj 给定的。在 E 步计算的 wj(i) 代表 z(i) 的软估计。
如果拿 M 步的更新同上面 z(i) 已知时的公式做对比,它们是相等的,除了指示函数 I{z(i)=j} 以 wj(i) 代替。
EM 算法会让人想起 K-均值聚类,差别在于硬聚类绑定 c(i) 以软绑定 wj(i) 代替。同 K-均值类似,它也会陷入局部最优,所以多对初始参数赋几次值是个好主意。
很清楚,EM 算法对重复猜测未知 z(i) 有一个非常自然的解释,但它能保证收敛吗?下篇文章将更广地介绍 EM,使我们可以把它应用到其它包含隐变量的估计问题,也会有收敛的证明。
参考资料:
1、http://cs229.stanford.edu/notes/cs229-notes7b.pdf

