EM 算法所面对的问题跟之前的不一样,要复杂一些。
EM 算法所用的概率模型,既含有观测变量,又含有隐变量。如果概率模型的变量都是观测变量,那么给定数据,可以直接用极大似然估计法,或贝叶斯估计法来估计模型参数,但是,当模型含有隐变量时,情况就复杂一些,相当于一个双层的概率模型,要估计出两层的模型参数,就需要换种方法求解。EM 算法是通过迭代的方法求解。
监督学习是由训练数据 {(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))} 学习条件概率分布 P(Y|X) 或决策函数 Y=f(X) 作为模型,用于分类、回归等任务,这时训练数据中的每个样本点由输入和输出组成。但有时训练数据只有输入没有对应的输出 {(x(1),•),(x(2),•),...,(x(m),•)},从这样的数据学习模型称为非监督学习问题。EM 算法可用于生成模型的非监督学习,生成模型由联合概率分布 P(X,Y) 表示,可以认为非监督学习训练数据是联合概率分布产生的数据。X 为观测数据,Y 为未观测数据。
我们先不管上一篇文章介绍的高斯混合模型,先来看通用的 EM 算法。
假设有训练集 {x(1),x(2),...,x(m)},我们要寻找模型 p(x,z) 的参数来拟合这些数据,数据的似然估计为:
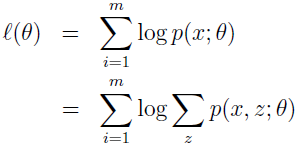
要直接使用极大似然估计来求 θ 是很难的,因为 z(i) 是隐随机变量,如果 z(i) 不是隐变量,而是可以观察到的,那使用极大似然估计就简单多了。
在这种情况下,EM 算法给出了一种高效的极大似然估计方法,直接最大化 L(θ) 很难,我们的策略是不断地构建 L 的下界(E-step),然后优化下界(M-step)。
对于每个 i,使 Qi 为 z 上的分布(∑zQi(z)=1,Qi(z)≥0),那么

最后一步的推导是用了 Jensen 不等式定理和 f(x)=log(x) 是凹函数的事实。
现在,对于一些 Qi 的分布,上式给出了 L(θ) 的下界,Qi 有很多种选择,该选择哪个呢?如果已经有 θ 的猜测值,那么自然会想到让下界贴近 θ 值,也就是使不等式在 θ 处等号成立。根据 Jensen 不等式,如果要使 E[f(X)]=f(EX) 成立,应使 X 为常数。即
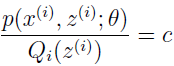
也就是
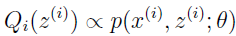
因为 ∑zQi(z(i))=1,所以可使
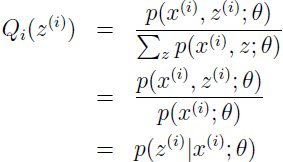
所以,就简单地把 Qi 设为给定 x(i) 和 θ 后 z(i) 的后验分布即可。
现在,有了 Q 的这个选择,就得到了 L 的下界,这是 E-step。在 M-step,对参数 θ 作极大似然估计。重复执行这两步,就是 EM 算法:
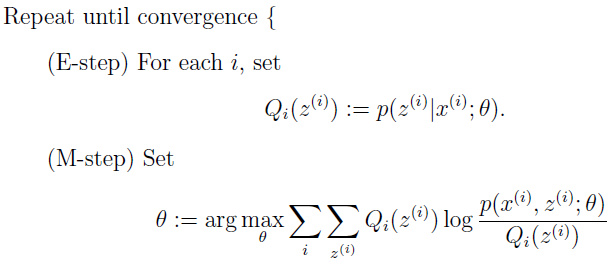
我们怎么知道算法是不是收敛呢?假设 θ(t) 和 θ(t+1) 是 EM 算法连续迭代的两个参数, 我们现在证明 L(θ(t))≤L(θ(t+1)),以证明 EM 单调改进 log 似然。证明的关键就在于 Qi 的选择,不失一般性,我们从 EM 迭代的 θ(t) 开始,Qi(t)(z(i)) :=p(z(i))p(x(i);θ(t)),我们知道这使得 Jensen 不等式变恒等。

参数 θ(t+1) 由最大化上式右边所得。

第一个不等式来自一个事实:

第二个不等式是因为 θ(t+1) 等于
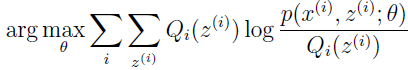
最后一个等式是因为 Qi 的选择使得 Jenson 不等式在 θ(t) 处等式成立。
所以 EM 使似然单调收敛,EM 算法一直运行知道收敛,收敛测试就是看两次结果的差是不是小于一个设置的容忍值,如果 EM 改进很慢就说明收敛了。
如果我们定义:
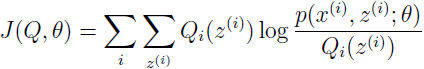
从之前的推导我们知道 L(θ)≥J(Q,θ),EM 算法可以看作是 J 的坐标上升法,在 E-step,以 Q 为参数最大化,在 M-step,以 θ 为参数最大化。
有了通用 EM 算法的定义,我们再来看下高斯混合模型中 Φ,µ 和 ∑ 的参数拟合。高斯混合模型应用广泛,在许多情况下,EM 算法是学习高斯混合模型的有效方法。简单起见,在 M-step 我们只推导 Φ 和 μi 的参数更新,有兴趣的可以推导下 ∑i。
假设有训练集 {x(1),x(2),...,x(m)},要把数据建模成一个联合分布 p(x(i),z(i))=p(x(i)|z(i))p(z(i)),其中 z(i)~Multinomial(Φ),x(i)|z(i)=j~N(µj,∑j),k 表示 z(i) 的可取值个数。数据 x(i) 是这样生成的:先从 {1,...,k} 中随机选择一个 z(i),再从 z(i) 所关联的高斯分布中生成 x(i)。这就是高斯混合模型,其中 z(i) 是隐变量,也就是未观测变量,正是这个变量使得问题变得复杂。
这个模型的参数是 Φ,μ 和 ∑,我们的任务就是估计出这些参数。
E-step 很简单,根据上面的推导,我们只需要计算
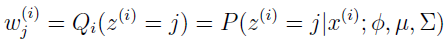
这里 Qi(z(i)=j) 表示 z(i) 在分布 Qi 下取值 j 的概率。使用贝叶斯规则来计算 z(i) 的后验概率。
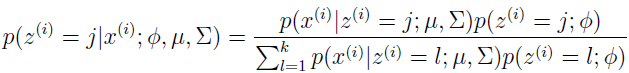
这里 p(x(i)|z(i)=j;μ,∑) 是均值为 μj,方差为 ∑j 的高斯分布在 x(i) 处的密度,p(z(i)=j;Φ) 由 Φj 给出。
下一步,在 M-step,我们需要最大化以 Φ,μ 和 ∑ 为参数的:
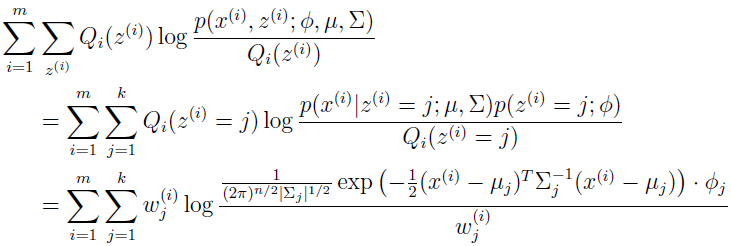
先来推导以 μl 为参数的最大化,有
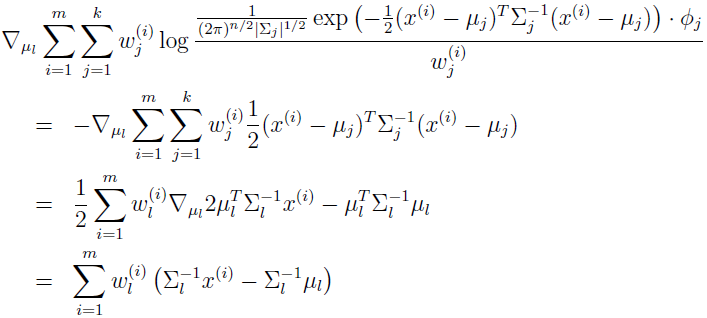
设为 0,就得到 μl 的更新规则。
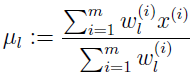
跟上一篇文章结果一样。
再来推导 M-step 中 Φj 的更新规则,经过观察,发现只需要最大化下式就可以了。
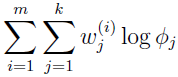
还有一个附加的约束,ΣΦj=1,因为 Φj=p(z(i)=j;Φ),为了处理这个约束,我们构建拉格朗日式子:
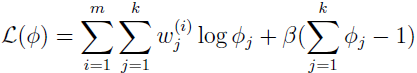
其中 β 是拉格朗日乘子。求导得:

上式设为 0,解得:

所以 Φj 正比于 Σw,由约束 ΣΦj=1,可得 -β=ΣiΣjw=m,所以

对于 Σj 的推导也很直观。
参考资料:
[1] http://cs229.stanford.edu/notes/cs229-notes8.pdf
[2] 李航,著.统计学习方法[M]. 清华大学出版社, 2012
