概念
Hadoop是一个大数据平台的生态圈,其中最主要的两个组件是HDFS和MapReduce,HDFS用来做分布式文件存储,MapReduce用来做分布式计算,而剩下的组件要么是基于HDFS,要么是基于MapReduce,像Hbase是基于HDFS的,Hive和Sqoop基于MapReduce。
背景
一个大数据平台最少需要5台机器,1台作NameNode,1台作SecondaryNameNode,剩下的3台作DataNode(3备份机制),这样的设计初衷是考虑到硬件的不可靠性,如果DataNode中有某几台机器坏了,对用户的影响能降到最小。
DataNode与NameNode
NameNode:大数据平台的元数据管理。
DataNode:存放实际文件,定期向NameNode汇报自己工作状态是否良好。
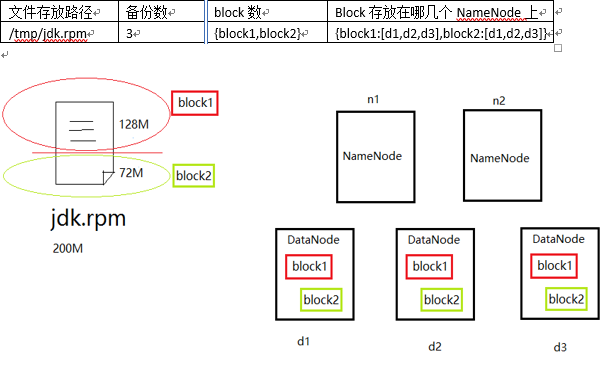
假如现在有一个jdk.rpm的文件,它实际是存放在DataNode上的,NameNode存放的是jdk.rpm的元数据信息。元数据信息的存储格式大致如下:
文件存放路径 备份数 block数 Block存放在哪几个NameNode上