作业要求:爬取千图网(http://www.58pic.com)某个频道的高清图片
作业难点:正确找到图片链接并用正则表达式写出
代码如下:
"""
Created on Mon Nov 28 13:59:15 2016
@author: FengYiz
"""
import urllib.request
import re
import urllib.error
urllib.request.urlcleanup()
keyname="pm" #设置关键词平面,可以换成其他
key=urllib.request.quote(keyname)
#为了方便,只爬取了前两页,道理是一样的
for i in range(1,3):
url="http://www.58pic.com/"+key+"/"+str(i)+".html"
data=urllib.request.urlopen(url,timeout=30).read().decode("utf-8","ignore")
#先开始准备以src作为标志,但后来再爬取的过程中发现,有的链接在src后面,有的在src1后面,无法统一,因此避开src
pat='<a class="thumb-box".*?(http://pic.qiantucdn.com/58pic/.*?).jpg!'
img=re.compile(pat).findall(data)
#同样为了方便,只爬取前8张图
for j in range(0,8):
try:
print("第"+str(i)+"页,第"+str(j)+"次爬取")
thisimg=img[j]
#注意,因为是高清大图,所以得事先找到高清大图的链接规则
result_url=thisimg+"_1024.jpg"
file="C:/Users/FengYiz/Desktop/tupian/"+str(i)+str(j)+".jpg"
urllib.request.urlretrieve(result_url,file)
print("-----成功-----")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
except Exception as e:
print(e)
运行后:

爬取下来的图片:
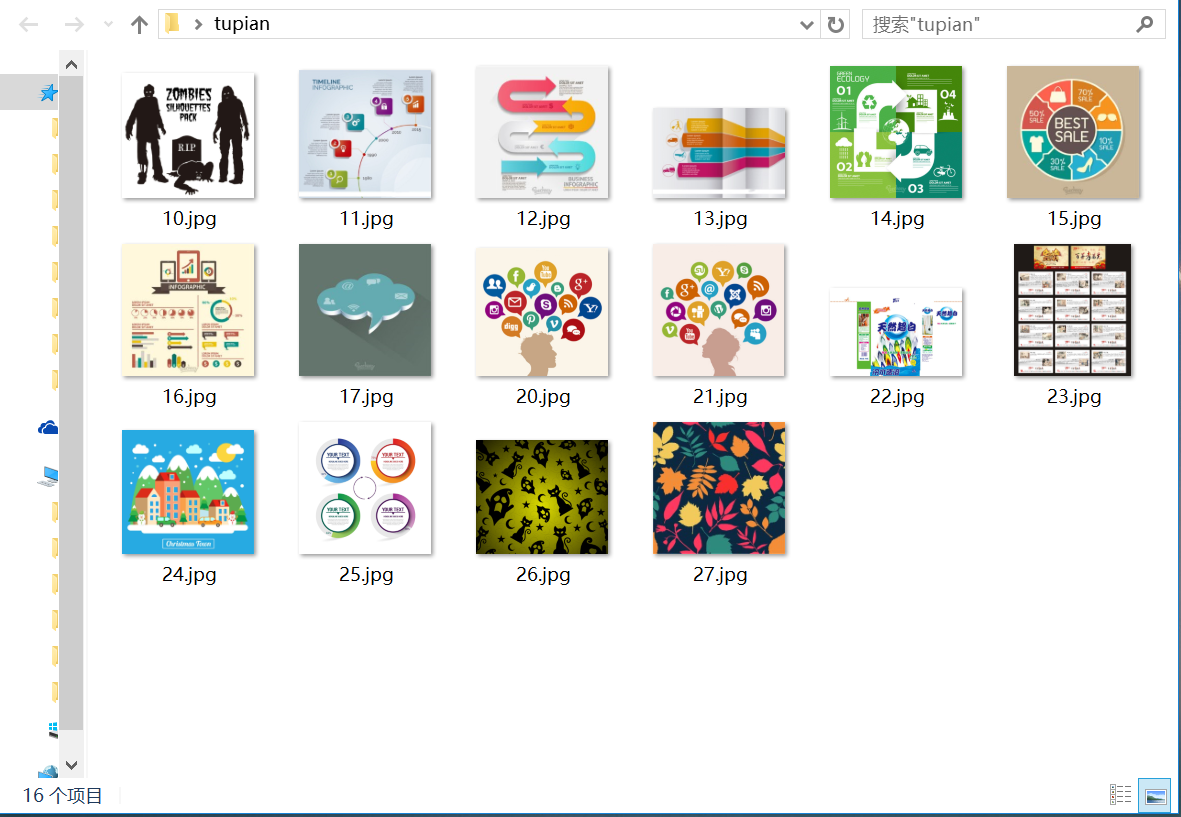
本来昨天晚上准备发的,因为事情耽搁了。于是,只有今晚再发上来。
努力赶进度中,加油!
