多表联合查询的时候,如果查看执行计划就会发现里面有多表之间的连接方式:hash join、merge join、 nested loop
具体适用哪种类型的连接取决于
- 当前的优化器模式 (ALL_ROWS 和 RULE)
- 取决于表大小
- 取决于连接列是否有索引
- 取决于连接列是否排序
1、hash join
场景:在两个表的数据量差别很大的时候,如
select city_name,country_name from country,city where country.country_id=city.country_id

优化器使用两个表中较小的表利用连接键(JOIN KEY)在内存中建立散列表,将列数据存储到hash列表中,然后扫描较大的表,同样对JOIN KEY进行HASH后探测散列表,找出与散列表匹配的行。
2、merge join
场景:
- 1.RBO(基于规则的优化器)模式
- 2.不等价关联(>,<,>=,<=,<>)
- 3.HASH_JOIN_ENABLED=false
- 4. 没有索引且数据已经排序
如
select city_name,country_name from country,city where country.country_id < city.country_id
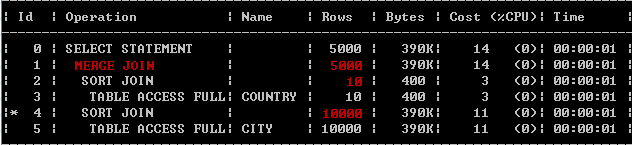
先将关联表的关联列各自排序,然后从各自的排序表中抽取数据,到另一个排序表中做匹配。因为merge join需要做更多的排序,所以消耗的资源更多。
3、nest looop
场景:
- 驱动表的记录集比较小(<10000)而且inner表具备有效的访问方法,且索引选择性较好
- 驱动表的记录集一定要小,返回结果集的响应时间最快
如
select city_name,country_name from country,city where country.country_id<>city.country_id

循环从一张表中读取数据(驱动表outer table),然后访问另一张表(被查找表 inner table,有索引)。驱动表中的每一行与inner表中的相应记录JOIN,类似一个嵌套的循环。
