2.3、实现一个实时词频统计
Kafka Streams是用于构建关键任务实时应用程序和微服务的客户端库,输入或输出数据存储在Kafka集群中。它结合了在客户端编写和部署标准Java和Scala应用程序的简单性,以及Kafka的服务器端集群技术的优点,使这些应用程序具有高度可伸缩性、弹性、容错、分布式和更多的优点。官方给的示例程序在这个库中运行流应用程序,源代码在GitHub:https://github.com/apache/kafka/blob/1.1/streams/examples/src/main/java/org/apache/kafka/streams/examples/wordcount/WordCountDemo.java,安装文件/opt/kafka/libs/kafka-streams-1.1.0.jar自带了这个类:org.apache.kafka.streams.examples.wordcount.WordCountDemo,意图是将Producer获取到的文本信息,实时统计并输出。
1)创建一个Topic:streams-plaintext-input,官方所给的demo的数据来源指定的Topic就是它,当然可以用Intellij改demo里的代码,然后打包再运行。
bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic streams-plaintext-input
2)创建一个Topic:streams-wordcount-output,用于输出词频计算的结果
bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic streams-wordcount-output \
--config cleanup.policy=compact
#这里对输出启用了压缩,单机版启用与否都不影响
执行命令bin/kafka-topics.sh --zookeeper localhost:2181 --list 即可查询到Kafka集群已有的Topic信息。
3)启动WordCount程序
程序将从streams-plaintext-input 输入中读取,对每个读取消息执行WordCount算法的计算,并将其当前结果持续地写入streams-wordcount-output。
bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
执行后也会出现一堆Log信息,别管他,然后通过一个单独的控制台终端中读取输出信息,检查WordCount应用的输出结果。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer

4)启动Producer手工输入文本信息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input

手工输入了一行文本,接下来马上看Output的统计结果
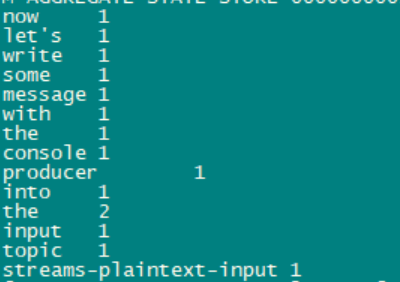
手工多输入一些文本,程序基本上妙极计算结果并输出,以下是我测试的结果:
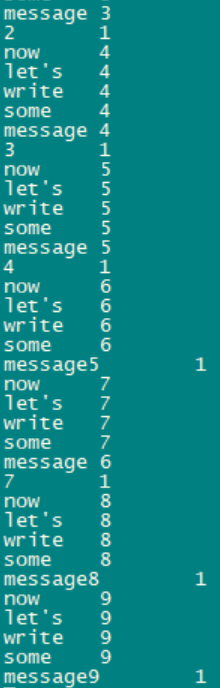
可以看到,Wordcount应用程序的输出实际上是一个连续的更新流,其中每个输出记录都是一个单词的更新计数。对于相同的多个记录,每个后续记录都是前一个记录的更新。
---------------------------------------------------------------------------------------------------------
基于这个demo,我把文字来源改为某个程序的log文件,只要log更新,wordcount马上计算结果。
A、添加一个connect-steam-source.properties文件
name=local-file-source
connector.class=FileStreamSource
tasks.max=1
file=/opt/kafka/logs/controller.log #这里设置为监控 kafka的运行日志
topic=streams-plaintext-input #跟上面的配置i一样,把log的信息输出到 streams-plaintext-input。
这样WordCount程序就可以从streams-plaintext-input获取文字信息,并实时统计
运行命令:bin/connect-standalone.sh config/connect-standalone.properties config/connect-steam-source.properties &
再查看下streams-plaintext-output的结果
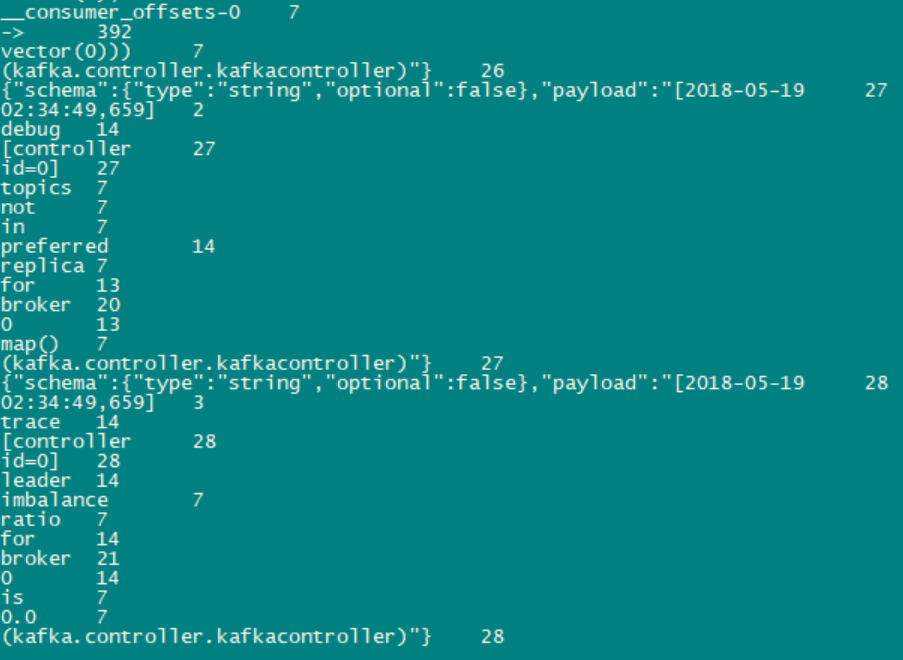
这样算买马马虎虎的搞定了。由于connect-standalone.properties配置的是文字格式为JSON,而WordCount程序又没有解析JSON格式,故出现了上图那种情况。
