环境:BIEE11.1.1.7... MSSQL....ORACLE
背景:
某天和同事针对BIEE中设置左连接,然后又在前端限定了左表的查询条件后,左连接功能失效的问题进行讨论验证。
发现确实如标题所说。
忍不住让人感慨,原来又是记忆出了错,看来好久不用的功能,就会慢慢模糊直至遗忘。
之间一直没有时间抽空整理。今天翻箱倒柜找到以前学习MSSQL分享的文章,再次学习下,贴出来与大家共享。
PS: 以下内容可以直接下载附件查看;以下select过程从MSSQL的角度所写,仅适用于MSSQL2000+,虽然和oralce的原理类似,不要生搬硬套至oracle。
LEFTJOIN引发的SELECT过程探究
前置条件:
create table a(a1 int,a2 varchar(10))
go
create table b(b1 int,b2 varchar(10))
go
insert into a(a1,a2) values(1,'a')
insert into a(a1,a2) values(1,'aa')
insert into a(a1,a2) values(1,'aaa')
insert into a(a1,a2) values(2,'aaaaa')
insert into a(a1,a2) values(3,'aaaa')
insert into b(b1,b2) values(1,'b')
insert into b(b1,b2) values(1,'bb')
insert into b(b1,b2) values(2,'bbb')
go
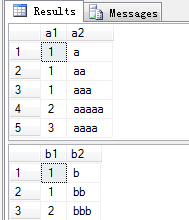
select * from a
select * from b
问题:
select a.a1,a.a2,b.b2
from a left join b on a.a1=b.b1 and a.a1=1
和
select a.a1,a.a2,b.b2
from a left join b on a.a1=b.b1
where a.a1=1
的查询结果相同么?
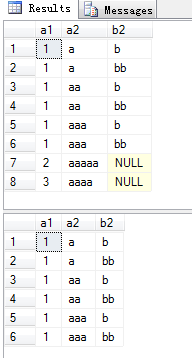
答案:不同
疑问:不是都应该是A表的a1字段等于1的才会显示在结果集么?
探究:SELECT逻辑查询处理的各个阶段:
(5) SELECT (5-2) DISTINCT (5-3) TOP(<top_specification>)(5-1) <select_list>
(1) FROM (1-J) <left_table><join_type> JOIN <right_table> ON <on_predicate>
|(1-A)<left_table> <apply_type> APPLY <right_table_expression> AS<alias>
|(1-P)<left_table> PIVOT (<pivot_specification>) AS <alias>
|(1-U)<left_talbe> UNPIVOT (<unpivot_specification>) AS <alias>
(2) WHERE <where_predicate>
(3) GROUP BY <group_by_specification>
(4) HAVING <having_predicate>
(6) ORDER BY <order_by_list>;
PS: 这里图片复制不过来,需要的TX自己下附件吧
(1) FROM FROM阶段标识出查询的来源表,处理表运算符。每个表运算符也会应用一系列子阶段。例如,在联接运算中涉及的阶段是(1-J1)笛卡尔积、(1-J2)ON筛选器和(1-J3)添加外部行。FROM阶段生成虚拟表VT1。
(1-J1)笛卡尔积 这个阶段对表运算符涉及的两个表执行笛卡尔积(交叉联接),生成虚拟表VT1-J1。
(1-J2)ON筛选器 这个阶段对VT1-J1中的行根据ON子句(<on_predicate>)中出些的谓词进行筛选。只有让该谓词取值为TRUE的行,才能插入VT1-J2中。
(1-J3)添加外部行 如果指定了OUTERJOIN(相对于CROSS JOIN 或INNER JOIN),则将保留表(preservedtable)中没有找到匹配的行,作为外部行添加到VT1-J2中,生成VT1-J3。
(2) WHERE 这个阶段根据在WHERE子句中出些的谓词(<where_predicate>)对VT1中的行进行筛选。只有让谓词计算结果为TRUE的行,才会插入VT2。
(3) GROUP BY 按照GROUP BY 子句中指定的列名列表,将VT2中的行进行分组,生成VT3。最终,每个分组只有一个结果行。
(4) HAVING 根据HAVING 子句中出现的谓词(<having_predicate>)对VT3中的分组进行筛选。只有让谓词计算结果为TRUE的组,才会插入VT4。
(5) SELECT 处理SELECT 子句中的元素,产生VT5。
(5-1)计算表达式 计算SELECT列表中的表达式,生成VT5-1。
(5-2) DISTINCT 删除VT5-1中的重复行,生成VT5-2。
(5-3) TOP 根据ORDER BY子句定义的逻辑排序,从VT5-2中选择前面指定数量或百分比的行,生成表VT5-3。
(6) ORDER BY 根据ORDER BY 子句中指定的列名列表,对VT5-3中的行进行排序,生成游标VC6。
从以上select逻辑过程可以看到前面两个查询的区别是前者虽然在“(1-J2)ON筛选器”中筛选掉了a表a1字段不等于1的,但在“(1-J3)添加外部行”又被添加回来,而后者虽然在“(1-J2)ON筛选器”中未筛选掉a表a1字段不等于1的纪录,但在后面的“(2) WHERE”阶段中筛选调了a表a1字段不等于1的纪录。故前者的查询有包含a表a1字段不等于1的纪录,而后者的查询不包含a表a1字段不等于1的纪录。
实例解析:
初始化数据:
create table TmpVendor(nVendorID int,sDeptNO varchar(20))
go
create table TmpOrder(nVendorID int,sPaperNO varchar(50))
go
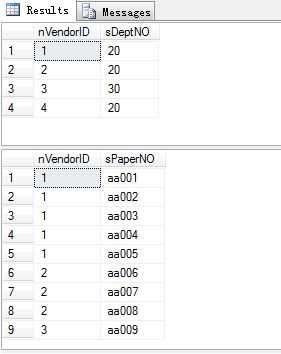
insert into TmpVendor(nVendorID,sDeptNO) values(1,'20')
insert into TmpVendor(nVendorID,sDeptNO) values(2,'20')
insert into TmpVendor(nVendorID,sDeptNO) values(3,'30')
insert into TmpVendor(nVendorID,sDeptNO) values(4,'20')
insert into TmpOrder(nVendorID,sPaperNO) values(1,'aa001')
insert into TmpOrder(nVendorID,sPaperNO) values(1,'aa002')
insert into TmpOrder(nVendorID,sPaperNO) values(1,'aa003')
insert into TmpOrder(nVendorID,sPaperNO) values(1,'aa004')
insert into TmpOrder(nVendorID,sPaperNO) values(1,'aa005')
insert into TmpOrder(nVendorID,sPaperNO) values(2,'aa006')
insert into TmpOrder(nVendorID,sPaperNO) values(2,'aa007')
insert into TmpOrder(nVendorID,sPaperNO) values(2,'aa008')
insert into TmpOrder(nVendorID,sPaperNO) values(3,'aa009')
GO
select TOP 10 v.nVendorID,COUNT(o.sPaperNO) as papernum
from TmpVendor as v
left join TmpOrder as o on v.nVendorID=o.nVendorID
where v.sDeptNO='20'
group by v.nVendorID having COUNT(o.sPaperNO)<5
order by papernum
解析SELECT过程:
1、 from阶段
1-J1笛卡尔积(执行交叉联接)
from TmpVendor as v
left join TmpOrder as o
结果将得到4×9行的VT1-JI
v.nVendorID v.sDeptNO o.nVendorID o.sPaperNO
1 20 1 aa001
1 20 1 aa002
1 20 1 aa003
1 20 1 aa004
1 20 1 aa005
1 20 2 aa006
1 20 2 aa007
1 20 2 aa008
1 20 3 aa009
2 20 1 aa001
2 20 1 aa002
2 20 1 aa003
2 20 1 aa004
2 20 1 aa005
2 20 2 aa006
2 20 2 aa007
2 20 2 aa008
2 20 3 aa009
3 30 1 aa001
3 30 1 aa002
3 30 1 aa003
3 30 1 aa004
3 30 1 aa005
3 30 2 aa006
3 30 2 aa007
3 30 2 aa008
3 30 3 aa009
4 20 1 aa001
4 20 1 aa002
4 20 1 aa003
4 20 1 aa004
4 20 1 aa005
4 20 2 aa006
4 20 2 aa007
4 20 2 aa008
4 20 3 aa009
1-J2应用ON筛选器(联接条件)
on v.nVendorID=o.nVendorID的逻辑值
逻辑值 v.nVendorID v.sDeptNO o.nVendorID o.sPaperNO
TRUE 1 20 1 aa001
TRUE 1 20 1 aa002
TRUE 1 20 1 aa003
TRUE 1 20 1 aa004
TRUE 1 20 1 aa005
FALSE 1 20 2 aa006
FALSE 1 20 2 aa007
FALSE 1 20 2 aa008
FALSE 1 20 3 aa009
FALSE 2 20 1 aa001
FALSE 2 20 1 aa002
FALSE 2 20 1 aa003
FALSE 2 20 1 aa004
FALSE 2 20 1 aa005
TRUE 2 20 2 aa006
TRUE 2 20 2 aa007
TRUE 2 20 2 aa008
FALSE 2 20 3 aa009
FALSE 3 30 1 aa001
FALSE 3 30 1 aa002
FALSE 3 30 1 aa003
FALSE 3 30 1 aa004
FALSE 3 30 1 aa005
FALSE 3 30 2 aa006
FALSE 3 30 2 aa007
FALSE 3 30 2 aa008
TRUE 3 30 3 aa009
FALSE 4 20 1 aa001
FALSE 4 20 1 aa002
FALSE 4 20 1 aa003
FALSE 4 20 1 aa004
FALSE 4 20 1 aa005
FALSE 4 20 2 aa006
FALSE 4 20 2 aa007
FALSE 4 20 2 aa008
FALSE 4 20 3 aa009
只有让<on_predicate>为TRUE的那些行,才会插入到VT1-J2中,如下示:
逻辑值 v.nVendorID v.sDeptNO o.nVendorID o.sPaperNO
TRUE 1 20 1 aa001
TRUE 1 20 1 aa002
TRUE 1 20 1 aa003
TRUE 1 20 1 aa004
TRUE 1 20 1 aa005
TRUE 2 20 2 aa006
TRUE 2 20 2 aa007
TRUE 2 20 2 aa008
TRUE 3 30 3 aa009
1-J3添加外部行
这一步只在外联接(outer join)中才会发生,本例中把左表TmpVendor在VT1-J2中被过滤掉的行及VT1-J2中的行生成VT1-J3(即VT1),如下示:
v.nVendorID v.sDeptNO o.nVendorID o.sPaperNO
1 20 1 aa001
1 20 1 aa002
1 20 1 aa003
1 20 1 aa004
1 20 1 aa005
2 20 2 aa006
2 20 2 aa007
2 20 2 aa008
3 30 3 aa009
4 20 NULL NULL
2、WHERE阶段
对上一步返回的虚拟表中的所有行应用where筛选器,只有让<where_predicate>逻辑条件为TRUE的行,才会组成这一步要返回的虚拟表(VT2)
本例中应用以下过滤条件
where v.sDeptNO='20'
这一步返回的虚拟表VT2如下示:
v.nVendorID v.sDeptNO o.nVendorID o.sPaperNO
1 20 1 aa001
1 20 1 aa002
1 20 1 aa003
1 20 1 aa004
1 20 1 aa005
2 20 2 aa006
2 20 2 aa007
2 20 2 aa008
4 20 NULL NULL
3、GROUP BY 阶段
在本阶段,根据<group_by_specification>指定的列表,将上一步返回的虚拟表中的行分组,本例中应用以下的分组条件
group by v.nVendorID
得到的虚拟表VT3如下示:
分组 v.nVendorID v.sDeptNO o.nVendorID o.sPaperNO
1 1 20 1 aa001
1 20 1 aa002
1 20 1 aa003
1 20 1 aa004
1 20 1 aa005
2 2 20 2 aa006
2 20 2 aa007
2 20 2 aa008
4 4 20 NULL NULL
4、HAVING阶段
HAVING筛选器对上一步返回的虚拟表中的组进行筛选。只有使<having_predicate>逻辑条件取值为TRUE的组,才会组成这一步返回的虚拟表(VT4)的一部分。
在本例中应用以下筛选条件
having COUNT(o.sPaperNO)<5
分组1因为包含5张订单被删除。生成的虚拟表VT4如下示:
分组 v.nVendorID v.sDeptNO o.nVendorID o.sPaperNO
2 2 20 2 aa006
2 20 2 aa007
2 20 2 aa008
4 4 20 NULL NULL
PS:在这里指定的是COUNT(o.sPaperNO)而不是count(*) ,这一点很重要。因为本例中联接是外联接,没有订单的供应商也会作为外部行被添加到结果集。count(*)会把外部行也统计在内,错误的将供应商编号为4的订单数统计为1。而COUNT(o.sPaperNO)则可以准确的统计每个供应商的订单数,为供应商编号为4生成期望的统计值0。和其他聚合函数一样,count(<expression>)将忽略NULL值。
PS:子查询不能作为聚合函数的输入。例如,不能使用Having sum((select……))>5
5、SELECT阶段
5-1计算表达式
本例中将应用以下语句:
select v.nVendorID,COUNT(*) as papernum
将得到虚拟表VT5-1表如下所示:
v.nVendorID papernum
2 3
4 0
5-2应用DISTINCT子句
本例中将忽略步骤5-2,因为在查询中没有指定DISTINCT子句。即使指定了,它也不会删除任何行(虚拟表VT5-1中本身没有重复行)
5-3应用TOP选项
TOP选项是T-SQL特有的一项功能,循序指定要返回的行数或者百分比(向上取整)。根据查询的ORDER BY子句来选择指定数量的行。最终生成虚拟表VT5-3(VT5)如下示:
v.nVendorID papernum
4 0
2 3
6、ORDER BY 排序阶段
这一步按ORDER BY子句中的列名列表对上一步返回的行进行排序,返回游标VC6。ORDER BY子句是以为可以重用SELECT列表中创建的列别名的步骤。
如果指定了DISTINCT,则ORDER BY子句中的表达式只能访问上一步返回的虚拟表(VT5)。如果没有指定DISTINCT,则ORDER BY子句中的表达式可以访问SELECT阶段的输入和输出虚拟表。也就是说,可以在ORDER BY子句中指定任何可以在SELECT子句使用的表达式。即,可以按不在最后返回的结果集中的表达式来进行排序。
本例中应用了以下排序条件:
order by papernum
直接访问VT5,生成游标VC6如下示:
v.nVendorID papernum
4 0
2 3
输出得到如下结果集
nVendorID papernum
4 0
2 3


