大家好,我是零一。这一篇给大家介绍聚类/分类。
我们先讲一讲聚类。
上一篇的探索关系,很多朋友反映说非常有趣,这一篇,聚类分析也是相当有趣的。
聚类分析简称聚类,俗话说物以类聚,人以群分,聚类就是划分子类的过程。算法上面多用k-means和k-medoids,当然,大家可以跳过这些算法的过程,用程序来完成即可。
说简单一点,通过聚类,可以将我们的数据进行分类,并且描述每个类的特征。
聚类应用非常广泛,包括在电商领域的应用也是多不胜数。比如
(1)对客户数据进行聚类分析得到多个客户群组,并且得到各个群组的特征,这可以帮助我们发现客户的共性和差异性;
(2)竞争对手数据进行聚类分析得到多个对手群组和各自的特征,这一样可以让我们找到对手们的共性和差异性;
(3)对行业数据进行聚类分析得到多个行业群组和各自的特征,这个可以来发现不同行业之间的共性和差异性
(4)对销售数据进行聚类分析(比如以其中的地域聚类),可以告诉我们那些地域之间的共性和差异性
不难发现,我举的4个例子都是在发现共性和差异性。对的!我们了解了这些信息,可以指导我们的运营决策,对不同群组制定不同的策略。
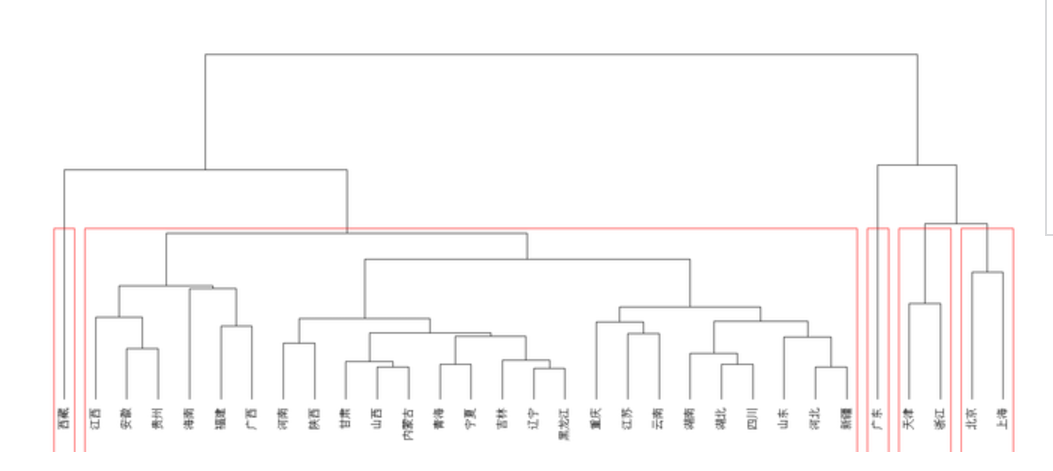
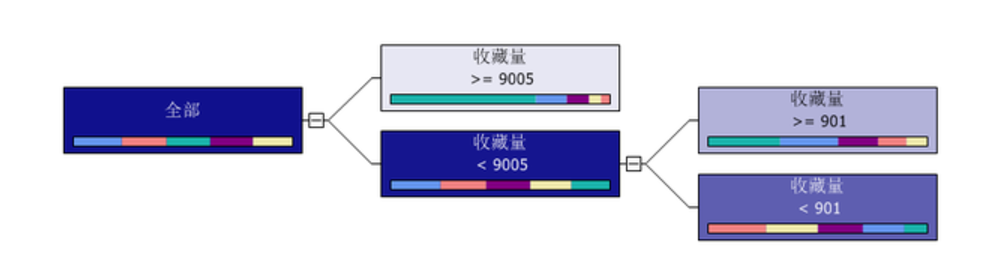
下图是对地域数据做的聚类分析,得到的一个谱系图,我们从上往下看,首先是分成两大类
广东,天津,浙江,北京和上海这五个省市为一类,其余的多省为一类。
再往下看又分成了四大类,西藏作为单独一个分类,广东也作为单独的一个分类,天津和浙江为一类,北京和上海为一类。
从上往下,越分越细。红色的边框把多个省市划分成5个分类。一般没必要分得太细,这个数据目测是分成了20个细分的分类,除非是确实是需要细分到很细的时候,才需要看最低层的分类。
当我们知道天津和浙江聚为一类的时候,他们必然存在共性,才会聚在一起。当我们知道天津-浙江类和北京-上海类,作为两个不同的群组聚集,它们之间肯定是存在某种差异。
=======================================
下面,我们用上篇共享的数据,跟大家一起探讨聚类,和寻找他们的共性和差异性。
先处理下缺失值,选择清除数据里面的离群值
中间要选择需要处理的字段,选择好后,进入以下界面,也一样下一步即可
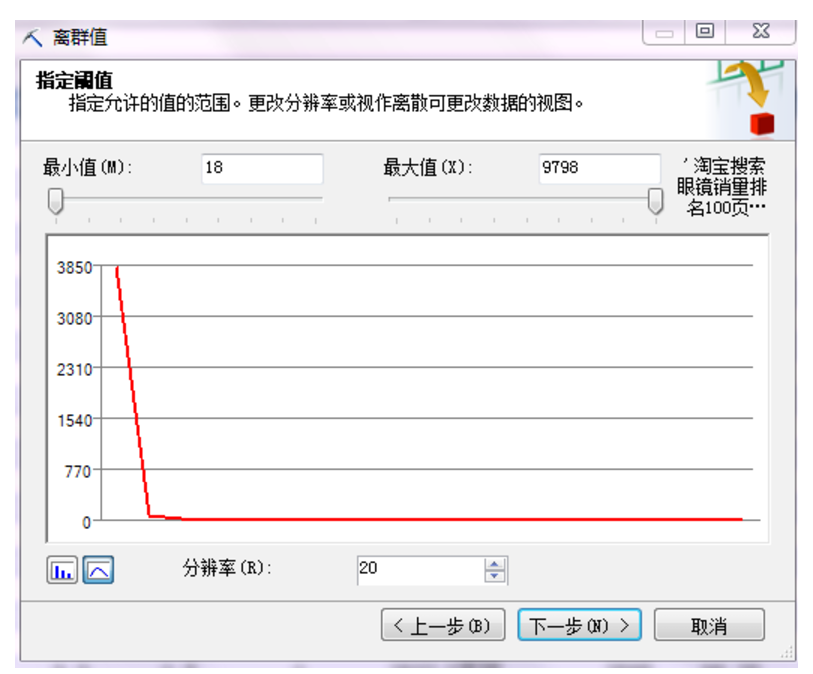
选择删除包含离群点的行(因为这里数据量不少,可以删了)
一般情况下,我们都避免直接修改源数据,需要新建一个变量或者空间或者工作表来存放处理过后的数据。这里选择复制到新的工作表就可以了。
数据处理好后,就可以进行聚类分析了。在数据挖掘套件里面直接选择聚类分析即可。

选择需要的数据进入模型里面
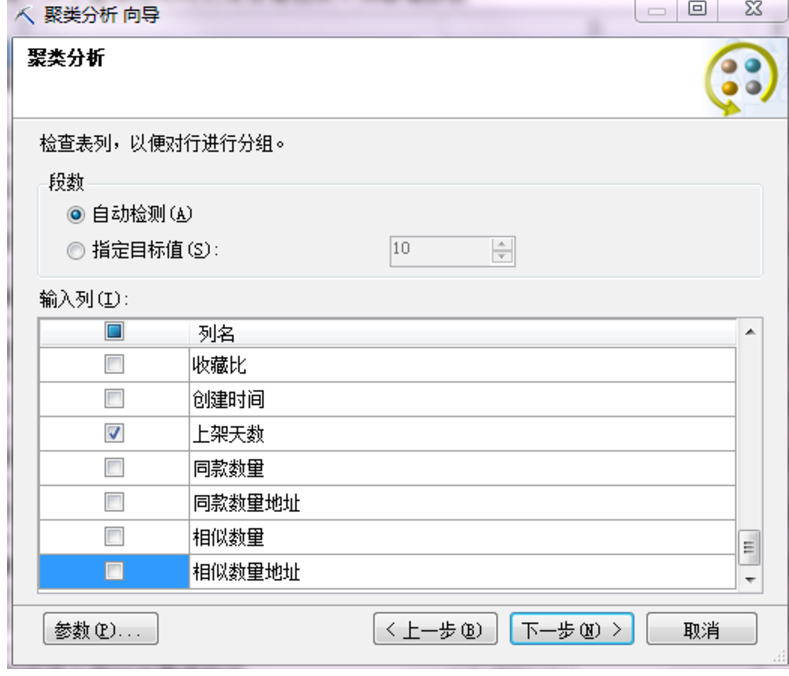
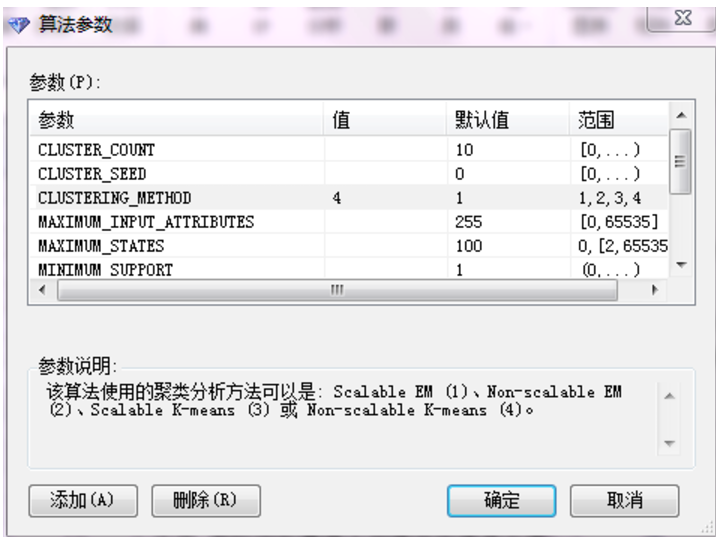
点击参数,然后就会看到下图这个对话框,可以手动输入数字来更改聚类算法,可以看到微软提供的聚类算法有4种,分别是可变的EM,固定的EM,可变的K-means跟固定K-means(EM是最大期望算法,K-means是K平均值算法,可变的是可以伸缩调整的,固定的就是固定不可调整的)
这里我输入4,选择固定的K-means算法
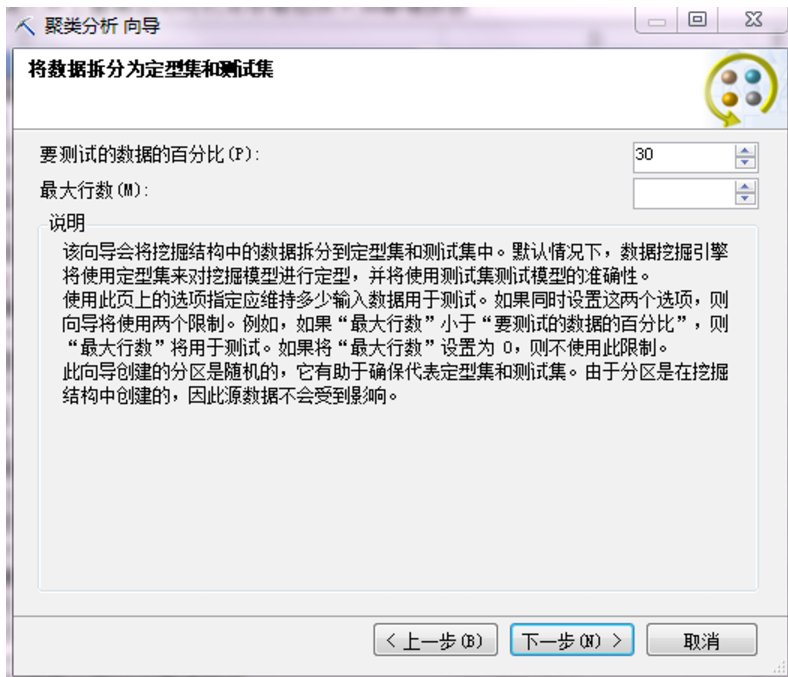
下图是选择测试集的比例,默认是30%。【测试集】是数据挖掘特有的名词,数据挖掘里头将数据集一分为二,大头的部分用来训练建立模型,称之为【训练集】,小的部分就用来测试模型,称之为【测试集】。这是数据挖掘和统计学最大的差异之一。统计学是通过统计方法来验证模型是否可靠,而数据挖掘技术是利用测试集来验证模型的可靠性。一般用于预测模型,聚类分析其实可以不用测试集,可以把数值改为0。但我就不改了。就用随机抽取出来的70%的数据来建立模型。
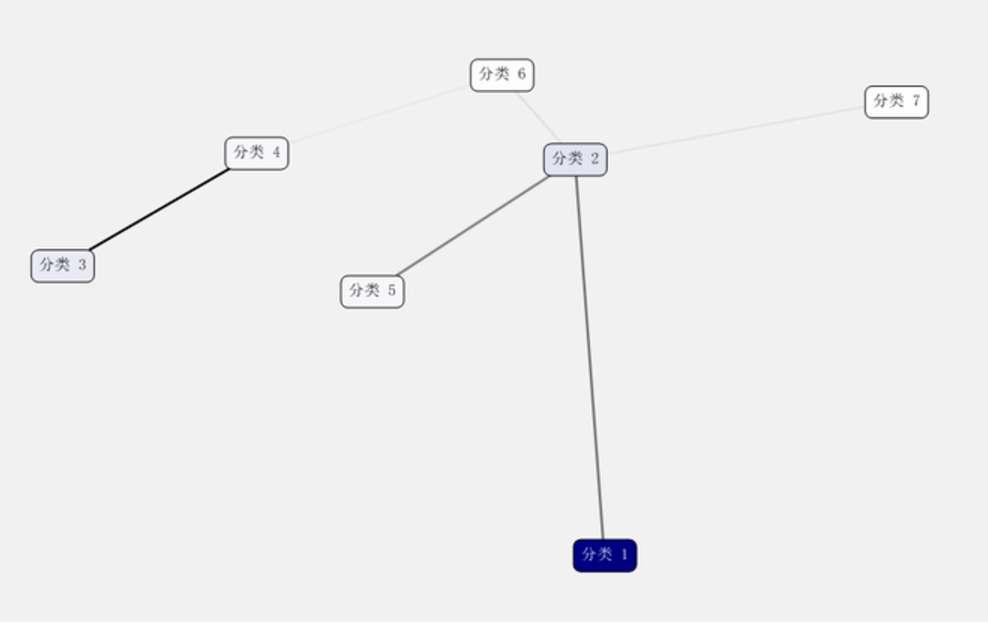
完成后,就会进入模型浏览界面,我们看到共有划分了7个,这有点儿多,我们可以在选择输入列的时候指定分类的数量,刚才我们是选了自动检测来着。
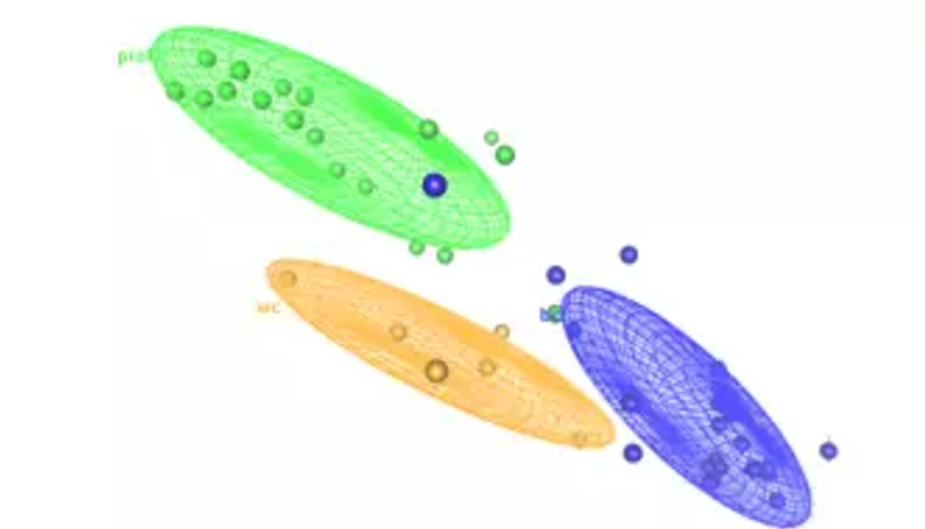
线粗代表两个分类之间的关系的强度,越粗关系越强。分类的颜色代表密度,颜色越是深蓝代表这个分类的数据个数越多。那非常明显,系统把大部分的数据归入分类1里头了。
下面是分类的剖面图,每个分类对应的指标范围在这里一览无遗。

简单解读一下上面这个分类情况
【分类1】包含2768个数据,最鲜明的是30天成交量偏大,价格偏低的这一个群组,是中低端爆款类
【分类2】只有246个数据,这个群组比较失败,发货分丶服务分丶好评率都偏低,销量偏低,价格偏高一点,典型就是卖货不卖服务类
【分类3】只有187个,集中在广东深圳,DSR很好,评价很好,价格很高,但退款率也很高,应该是高端市场的卖家,标准的价格高,服务好,但不知为何退款率也高,可能是买家收到了,觉得不划算吧,这一类是高端类,但产品或品牌的价值感可能没有做好。
【分类4】只有65个,也是DSR超好,价格中档,产品的价值完美体现,退款率不错,同样集中在广东深圳,是中档性价比类。
【分类5】只有61个,这个群组很惨,集中在浙江金华(估计是义乌),价格超低,DSR超烂,好评率很惨,是低端烂货类
【分类6】和【分类7】规模很小,就不解读了。以上解读仅供参考。一般分个4-5个群组就差不多了,如果数据量确实大,可以考虑分细一些。
每一个分类都可以单独提取出这个分类下的数据的。
下图是分类的一些特征,每个特征的概率情况
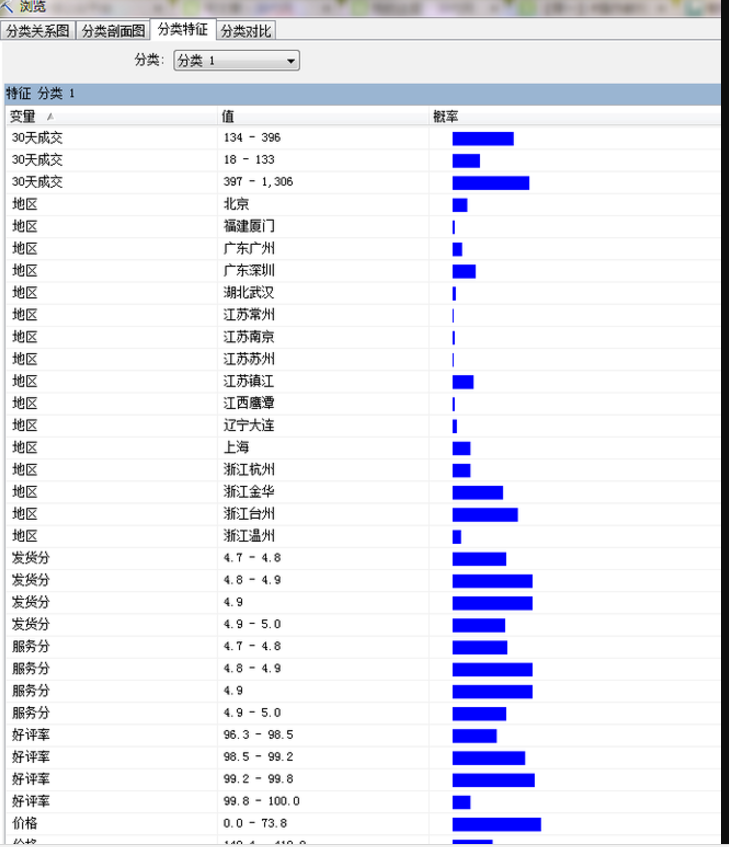
下图是分类间的差异性,通过对比可以发现,分类1多是天猫,非分类1的多是C店。

下面我着重看下分类3和分类4的区别,因为分类3败在退款率上面,而分类四就解决了这个问题。
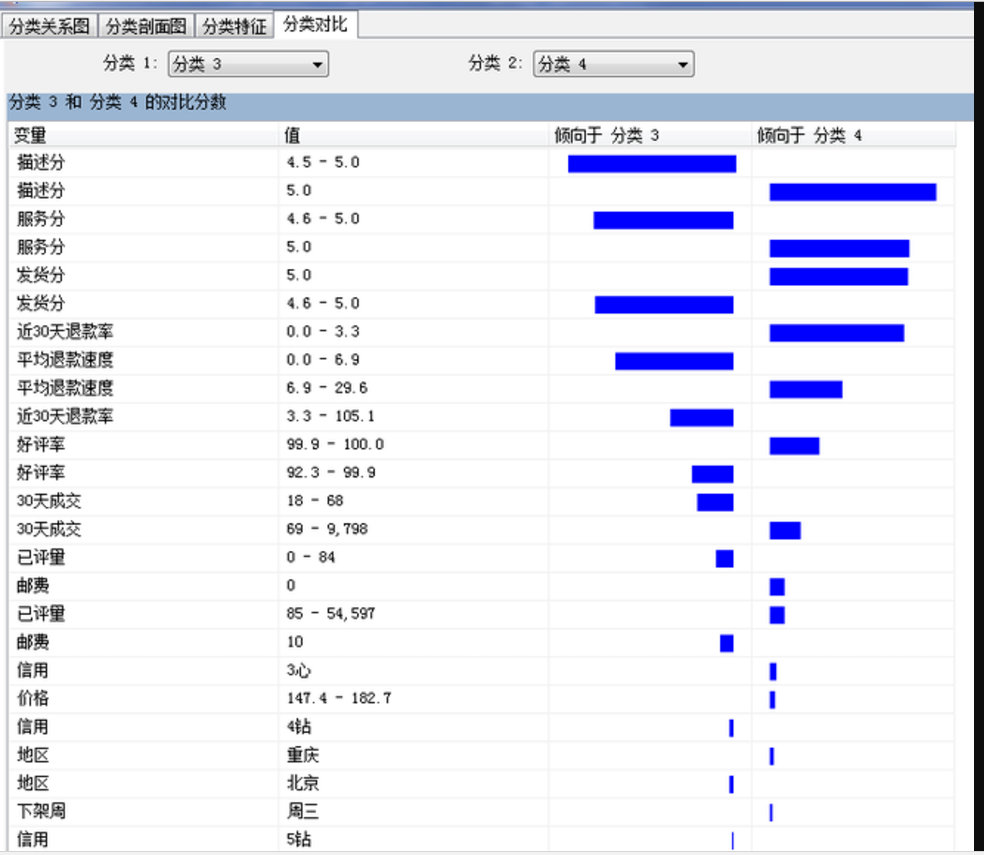
我大致上看出来了,分类3的服务(DSR,退款速度)没有分类4的做得好,但分类4的价格又要比分类3低,并且包邮。那作为消费者,肯定选个价格中肯,服务又好的店家。而且分类4的销量还不低,有少部分是心店,我对心店的印象就是心店的服务一般要比大店的要好。
以上就是对这儿聚类分析结果的简单解读,具体的,亲们实操一下吧。
=============================================
下面说说分类。
聚类和分类,从语义来讲,看似很像,但有一点重要的差异。分类是指定了我们要分析的列(维度),然后通过决策树算法(默认方法是用贝叶斯分类器),来告诉我们,影响这个目标的维度有哪些。下面我们看下过程。

选择要分析的列,我这里选择的是30天销量,看下会影响销量的是什么因子。
下图是结果,告诉我们,收藏很重要!收藏跟销量有很强的关系。同样第一张图是决策树,一样有分组的作用。
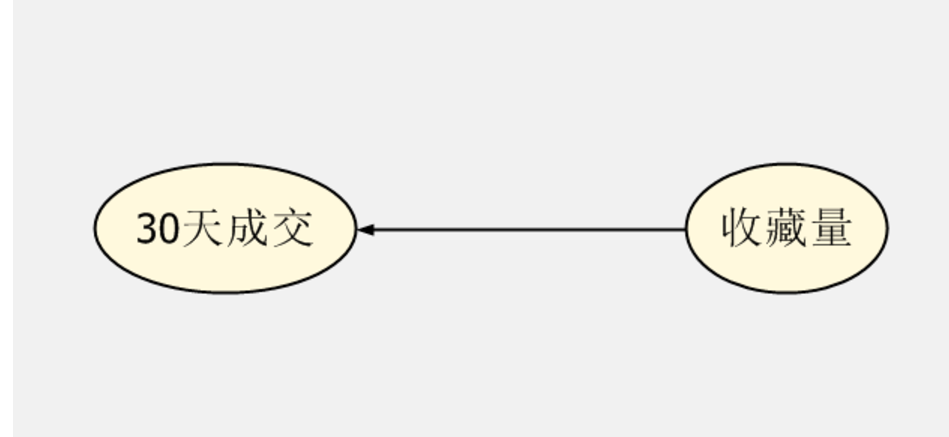
决策树一般用来分析影响客户下单或者流失的因子有哪些。有兴趣的朋友可以自己倒腾一下。试下会有哪些意外的收获。
===========================================
下面,告诉大家测试集的使用方法。
选择准确性图表
选择模型,一般用于预测模型,刚才的决策树是属于预测模型,而聚类就不属于,因此聚类的模型不可用于准确性图表。
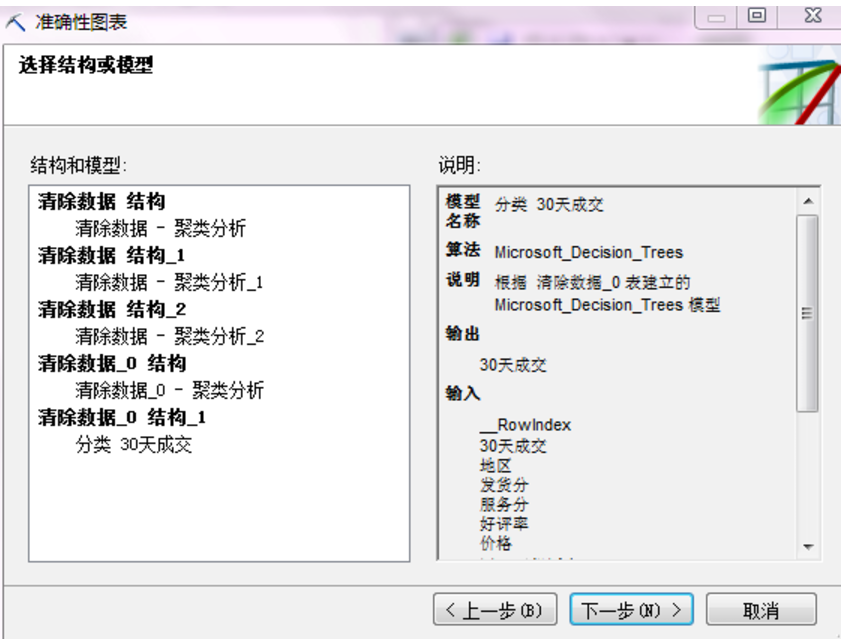
选择要预测的区间,我选择的是30天成交大于122的情况
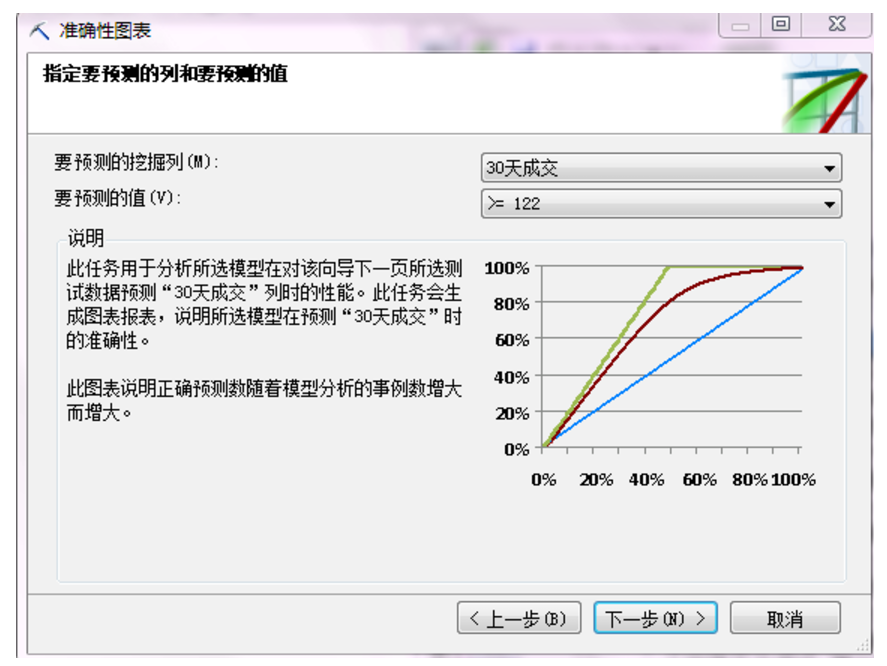
我们之前保留的测试集,就在这里出现了,默认会选择测试集来验证准确性。
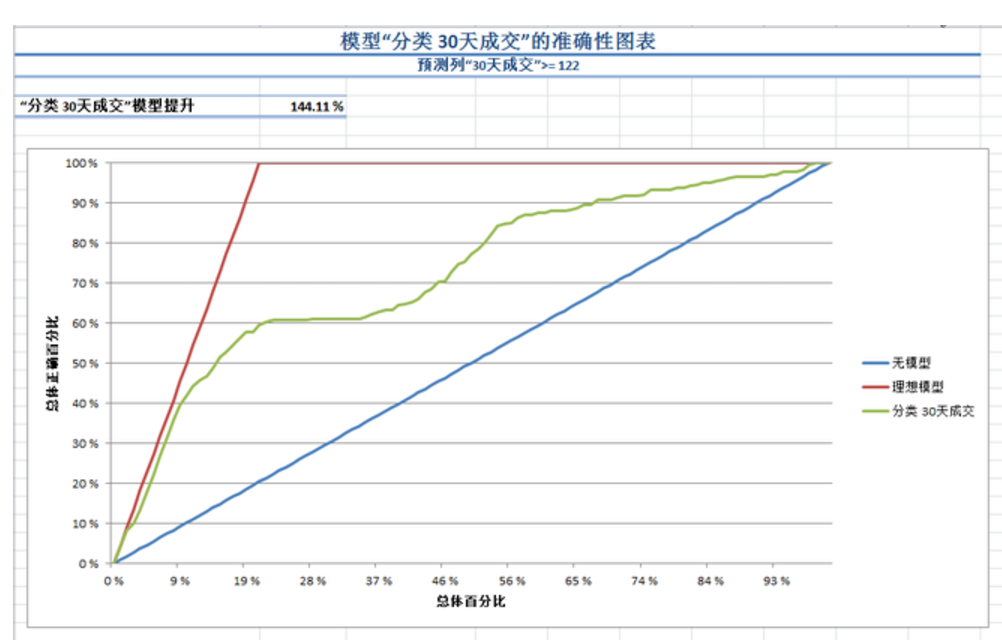
在上图点了完成后,就会得到这样的一个结果(部分截图),会有一个指标, “分类 30天成交”模型提升144.11%,这个数值越大代表模型的准确性越高。但我一般看下面的ROC图。
蓝色代表没有模型的结果,红色代表理想的结果。而绿色代表我们测试得到的结果。
绿色的线越接近红色的就代表越好,一般情况下,只要不要太接近蓝色的线(或者低于蓝色的线),就好了。如果接近蓝色的线或者在蓝色线下面,那就不如不用模型了,此时这个模型就没什么存在的意义,如果硬要用那就只是为了做模型玩玩而已了。
SQL SERVER和数据挖掘套件的下载地址和安装教程:
http://pan.baidu.com/share/link?shareid=1490988699&uk=2164472865

