作者:数据取经团-白云飞

基于五种机器算法的信用风险评估是一个系列文章,从互金数据出发,经过数据预处理,特征工程,建立机器学习模型,以及模型评估四个部分来分析建模。文章将按照一般的建模流程来组织:确定业务目标→数据获取→数据检验→变量选择(数据清洗)→变量转化→数据输入模型算法→模型评估。本文的重点放在建模前期的数据准备上,包括数据基本信息的分析,数据异常值、缺失值的分析,单变量分析以及变量的相关性分析上。为下一期的特征工程做好准备。
(1)数据预处理
数据准备
数据字段有18个分别为status、paid.ratio和16个模型变量。
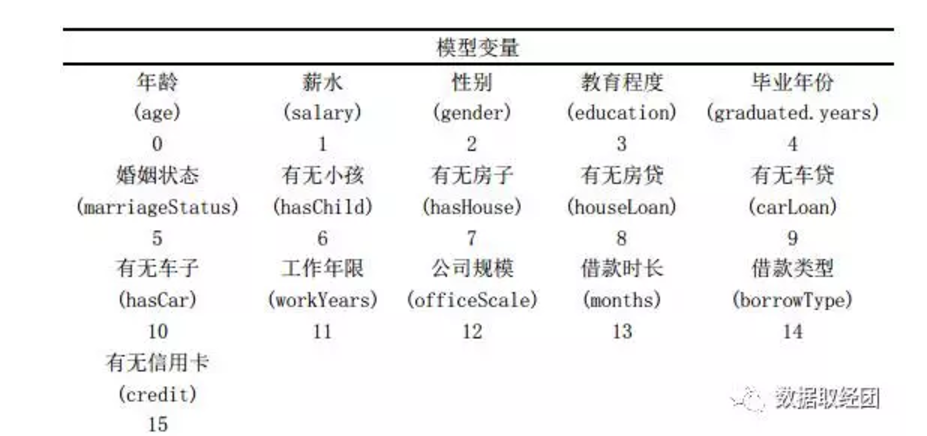
备注:
1. 教育程度一项给高中、大专、本科、研究生分别打分3、6、8、10。未填 此项打分为0(0值有三人,均无逾期)。
2. 对给出数额范围的项目做了取边界和平均的平滑处理。例如,薪水小于1000算作1000;1000-2000算作1500;2000-5000算作3500等等。
3. 分类使用status变量作为y值,0表示没有违约、1表示违约。
4. 回归使用paid.ratio变量,变量值表示已付的比例。
5. 给每个变量标号后,图形的坐标可视化更加友好。
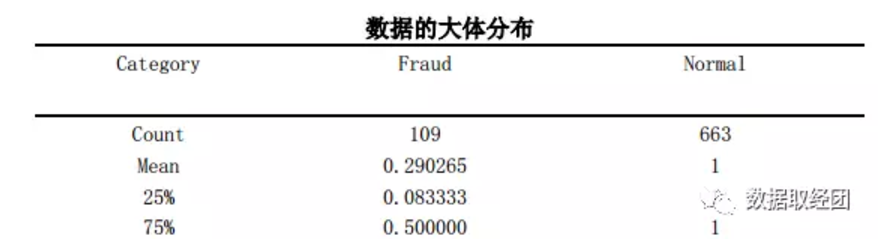
数据大体分布
1. 数据为不平衡数据,正负数据比例为6:1,考虑采用重采样的方法增加样本量。
2. 且负样本中还款率均值为30%,说明一旦出现未还的账目,借款人就倾向于不还钱(破窗效应)
3. 3/4分为点才达到50%的还款率,进一步说明还款率较低
数据处理
如何在这些字段中提取出模型要使用的特征变量实际上决定了模型的上限,数据预处理显得十分重要,一般对信用评分的模型数据采用以下预处理步骤:
1. 贷后的相关变量除了target变量,其余直接剔除,因为贷后表现在客户申请时是没有的,如果贷后数据进入模型实际上就成了未来变量(本文不涉及这个问题);
2. 缺失率太高的变量直接剔除,一般按65%的阈值来剔除的(本文不涉及这个问题);
3. 删除缺失率太高的数据后,对剩余存在缺失的数据进行填充,具体需要根据业务逻辑以及经验可以采用经验、线性差值、众数、均值以及向前向后的方法补齐数据(本文中变量graduated.years(连续型)和marriageStatus(离散型)存在缺失数据,已经用-1补齐,-1按照单独一类来处理)。
4. 数值变量中所有值方差太小接近常量的变量剔除,因为不能提供更多信息(本文采用VIF>5为界,没有剔除变量);
5. 按业务逻辑完全不可解释的变量直接剔除(本文不涉及这个问题)
6. 分类变量中unique值大于20的直接剔除或者按照连续变量来处理(分类变量类别太多没有意义,处理graduated.years其实是离散的数据,但是由于类别>20,需要采用连续型方法);
7. 将object类型数据转换成数值类型(本文不涉及这个问题).
缺失值分析和处理
变量graduated.years(离散型)和marriageStatus(离散型)存在缺失数据,已经用-1补齐,-1将按照单独一类来处理。
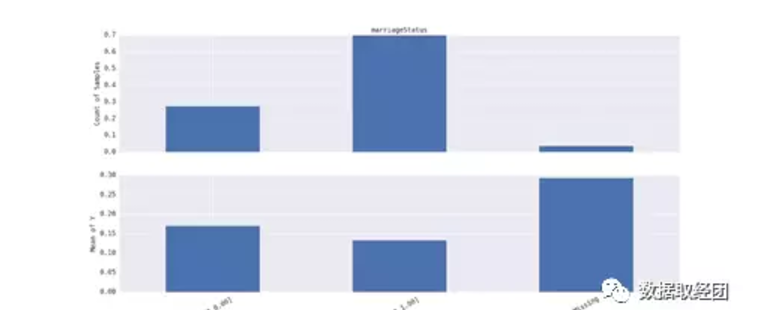
对单变量marriageStatus和Y做分析图,发现存在missing值违约概率异常高 ,可以进一步分析。
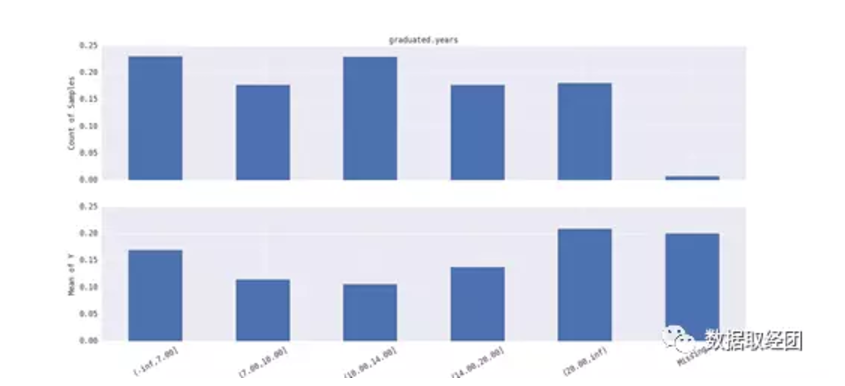
对单变量graduated.years和Y做分析图,发现存在missing值违约概率异常高 ,可以进一步分析。
异常值分析和处理
对单变量进行分箱处理:
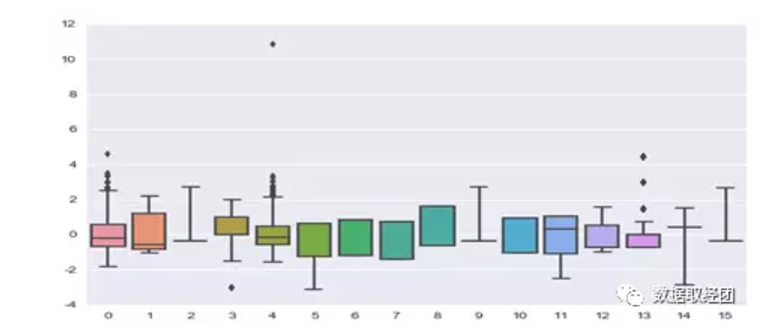
存在异常值的variable:age,education,graduated.years,months
1. age、education、months中的异常值可以解释为数据本身的特点,无需处理。
2. graduated.years 存在较大的离群点 ,进一步,id=66号的特征中graduated.year=113,不符合常理,予以剔除。(且此人逾期,可以加规则来识别)
变量分析
单变量分析
我们可以简单地看下部分变量的分布,比如对于age变量,如下图:
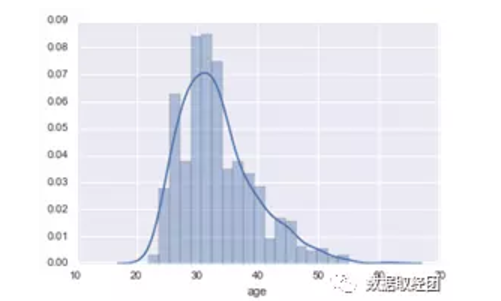
可以看到年龄变量大致呈正态分布,符合统计分析的假设。
再比如毕业年限变量,也可以做图观察观察,如下:
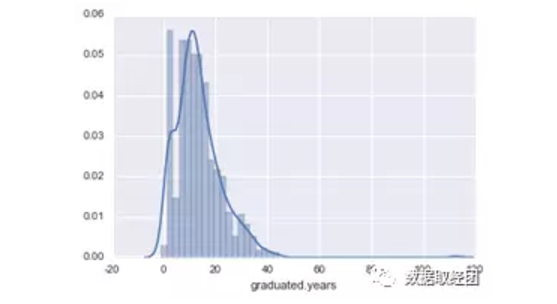
也大致呈正态分布,符合统计分析的需要。
变量之间相关性分析
建模之前首先得检验变量之间的相关性,如果变量之间相关性显著,会影响模型的预测效果。下面通过corrplot函数,画出各变量之间,包括响应变量与自变量的相关性。
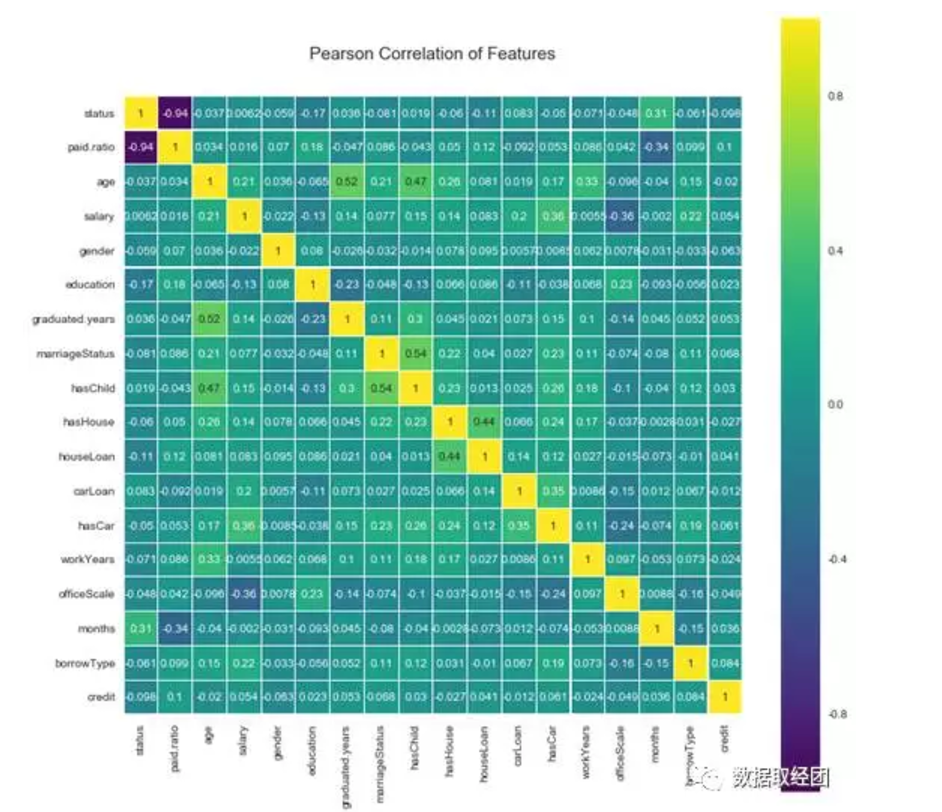
由上图可以看出,除了status和paid.ratio之间存在极强的负相关,其他各自变量之间的相关性是非常小的。
一些超过0.5的相关度的变量之间本身存在较强的联系:graduated.year 和 age、hasChild 和 marriageStatus,存在一定的相关度,且较容易解释。
在Logistic回归,首先需要检验多重共线性问题,此处由于各变量之间的相关性较小,可以初步判断不存在多重共线性问题,而且我们在建模后还可以用VIF(方差膨胀因子)来检验多重共线性问题。如果存在多重共线性,即有可能存在两个变量高度相关,需要降维或剔除处理。
基于数据处理的一些简单特征分析
通过识别graduated.years>固定值的id,目前的数据表明这样的id极有可能为欺诈id。
通过单变量X和Y值的分析发现:salary、officeScale、graduated.years、education、age 、borrowType这些变量,status的分布不均衡,salary在7500左右,officeScale在55左右的人,他们的薪资水平无法匹配他们的消费水平,可能容易逾期,后期将利用特征工程,进一步分析变量的重要性。
下期预告:将采用重采样,改善数据集的好坏样本分布,对连续变量做WOE转化提升模型效果,初步建立LogisticRegression模型,给变量打分,最终确定入模特征。

