航空客户价值分析不同于传统的RFM模型,其考虑了5个因素:入会时长L,消费时间间隔R,消费频率F,飞行里程M,和折扣系数的平均值C,简记为LRFMC模型,通过对这5个变量对应下的观测数据进行聚类,从而将客户分成不同价值等级的群体。
##读入数据
>airdata<-read.csv("E:\\R语言\\图书配套数据、代码\\chapter7\\上机实验\\data\\air_data.csv",header=T)
说明:共有62988条记录,44个变量
>names(airdata)
[1] "MEMBER_NO" "FFP_DATE" "FIRST_FLIGHT_DATE"
[4] "GENDER" "FFP_TIER" "WORK_CITY"
[7] "WORK_PROVINCE" "WORK_COUNTRY" "AGE"
[10] "LOAD_TIME" "FLIGHT_COUNT" "BP_SUM"
[13] "EP_SUM_YR_1" "EP_SUM_YR_2" "SUM_YR_1"
[16] "SUM_YR_2" "SEG_KM_SUM" "WEIGHTED_SEG_KM"
[19] "LAST_FLIGHT_DATE" "AVG_FLIGHT_COUNT" "AVG_BP_SUM"
[22] "BEGIN_TO_FIRST" "LAST_TO_END" "AVG_INTERVAL"
[25] "MAX_INTERVAL" "ADD_POINTS_SUM_YR_1" "ADD_POINTS_SUM_YR_2"
[28] "EXCHANGE_COUNT" "avg_discount" "P1Y_Flight_Count"
[31] "L1Y_Flight_Count" "P1Y_BP_SUM" "L1Y_BP_SUM"
[34] "EP_SUM" "ADD_Point_SUM" "Eli_Add_Point_Sum"
[37] "L1Y_ELi_Add_Points" "Points_Sum" "L1Y_Points_Sum"
[40] "Ration_L1Y_Flight_Count" "Ration_P1Y_Flight_Count" "Ration_P1Y_BPS"
[43] "Ration_L1Y_BPS" "Point_NotFlight"
##选择需要的变量
由于变量个数很多,许多都是分析中不需要的,可以选择性的对可能需要的变量进行探索性分析。
>airdatanew<-airdata[,c(1:2,10:11,15:18,20:29)]#实际的选择可以自己确定,但是涉及到LRFMC模型的变量一定要选进来。
说明:由于本分析中不涉及客户特征相关的分析,所以可以剔除。另外积分相关的数据也不涉及可以剔除。
##数据探索
>summary(airdatanew)
MEMBER_NO FFP_DATE LOAD_TIME FLIGHT_COUNT SUM_YR_1
Min. : 1 2011/1/13 : 184 2014/3/31:62988 Min. : 2.00 Min. : 0
1st Qu.:15748 2013/1/1 : 165 1st Qu.: 3.00 1st Qu.: 1003
Median :31495 2013/3/1 : 100 Median : 7.00 Median : 2800
Mean :31495 2010/11/17: 99 Mean : 11.84 Mean : 5355
3rd Qu.:47241 2011/1/14 : 95 3rd Qu.: 15.00 3rd Qu.: 6574
Max. :62988 2012/9/19 : 88 Max. :213.00 Max. :239560
(Other) :62257 NA's :551
SUM_YR_2 SEG_KM_SUM WEIGHTED_SEG_KM AVG_FLIGHT_COUNT AVG_BP_SUM
Min. : 0 Min. : 368 Min. : 0 Min. : 0.2500 Min. : 0.0
1st Qu.: 780 1st Qu.: 4747 1st Qu.: 3219 1st Qu.: 0.4286 1st Qu.: 336.0
Median : 2773 Median : 9994 Median : 6978 Median : 0.8750 Median : 752.4
Mean : 5604 Mean : 17124 Mean : 12777 Mean : 1.5422 Mean : 1421.4
3rd Qu.: 6846 3rd Qu.: 21271 3rd Qu.: 15300 3rd Qu.: 1.8750 3rd Qu.: 1690.3
Max. :234188 Max. :580717 Max. :558440 Max. :26.6250 Max. :63163.5
NA's :138
BEGIN_TO_FIRST LAST_TO_END AVG_INTERVAL MAX_INTERVAL ADD_POINTS_SUM_YR_1
Min. : 0.0 Min. : 1.0 Min. : 0.00 Min. : 0 Min. : 0.0
1st Qu.: 9.0 1st Qu.: 29.0 1st Qu.: 23.37 1st Qu.: 79 1st Qu.: 0.0
Median : 50.0 Median :108.0 Median : 44.67 Median :143 Median : 0.0
Mean :120.1 Mean :176.1 Mean : 67.75 Mean :166 Mean : 540.3
3rd Qu.:166.0 3rd Qu.:268.0 3rd Qu.: 82.00 3rd Qu.:228 3rd Qu.: 0.0
Max. :729.0 Max. :731.0 Max. :728.00 Max. :728 Max. :600000.0
ADD_POINTS_SUM_YR_2 EXCHANGE_COUNT avg_discount
Min. : 0.0 Min. : 0.0000 Min. :0.0000
1st Qu.: 0.0 1st Qu.: 0.0000 1st Qu.:0.6120
Median : 0.0 Median : 0.0000 Median :0.7119
Mean : 814.7 Mean : 0.3198 Mean :0.7216
3rd Qu.: 0.0 3rd Qu.: 0.0000 3rd Qu.:0.8095
Max. :728282.0 Max. :46.0000 Max. :1.5000
说明:
1、只有SUM_YR_1和SUM_YR_2存在缺失值
2、 删除票价为0,但是平均折扣和总飞行公里数大于0的记录(逻辑错误值)
>str(airdatanew)#全部是连续型变量
'data.frame': 62988 obs. of 18 variables:
$ MEMBER_NO : int 54993 28065 55106 21189 39546 56972 44924 22631 32197 31645 ...
$ FFP_DATE : Factor w/ 3068 levels "2004/11/1","2004/11/10",..: 498 923 913 1473 1703 1279 590 2095 2519 2183 ...
$ LOAD_TIME : Factor w/ 1 level "2014/3/31": 1 1 1 1 1 1 1 1 1 1 ...
$ FLIGHT_COUNT : int 210 140 135 23 152 92 101 73 56 64 ...
$ SUM_YR_1 : num 239560 171483 163618 116350 124560 ...
$ SUM_YR_2 : int 234188 167434 164982 125500 130702 76946 114469 114971 87401 60267 ...
$ SEG_KM_SUM : int 580717 293678 283712 281336 309928 294585 287042 287230 321489 375074 ...
$ WEIGHTED_SEG_KM : num 558440 367777 355967 306901 300834 ...
$ AVG_FLIGHT_COUNT : num 26.25 17.5 16.88 2.88 19 ...
$ AVG_BP_SUM : num 63164 45310 43895 42164 34231 ...
$ BEGIN_TO_FIRST : int 2 2 10 21 3 11 11 0 7 2 ...
$ LAST_TO_END : int 1 7 11 97 5 79 1 3 6 15 ...
$ AVG_INTERVAL : num 3.48 5.19 5.3 27.86 4.79 ...
$ MAX_INTERVAL : int 18 17 18 73 47 52 28 45 94 73 ...
$ ADD_POINTS_SUM_YR_1: int 3352 0 3491 0 0 0 0 0 0 0 ...
$ ADD_POINTS_SUM_YR_2: int 36640 12000 12000 0 22704 2460 12320 9500 500 0 ...
$ EXCHANGE_COUNT : int 34 29 20 11 27 10 20 7 5 13 ...
$ avg_discount : num 0.962 1.252 1.255 1.091 0.971 ...
说明:
FFP_DATE 和LOAD_TIME 都是因子,后面构建模型前需要将其转化为date格式,计算日期差。
#查看缺失值
>library(mice)
>library(VIM)
>md.pattern(airdatanew)
MEMBER_NO FFP_DATE LOAD_TIME FLIGHT_COUNT SEG_KM_SUM WEIGHTED_SEG_KM AVG_FLIGHT_COUNT AVG_BP_SUM BEGIN_TO_FIRST LAST_TO_END AVG_INTERVAL
62299 1 1 1 1 1 1 1 1 1 1 1
551 1 1 1 1 1 1 1 1 1 1 1
138 1 1 1 1 1 1 1 1 1 1 1
0 0 0 0 0 0 0 0 0 0 0
MAX_INTERVAL ADD_POINTS_SUM_YR_1 ADD_POINTS_SUM_YR_2 EXCHANGE_COUNT avg_discount SUM_YR_2 SUM_YR_1
62299 1 1 1 1 1 1 1 0
551 1 1 1 1 1 1 0 1
138 1 1 1 1 1 0 1 1
0 0 0 0 0 138 551 689
>aggr(airdatanew,prop=F,numbers=T)
说明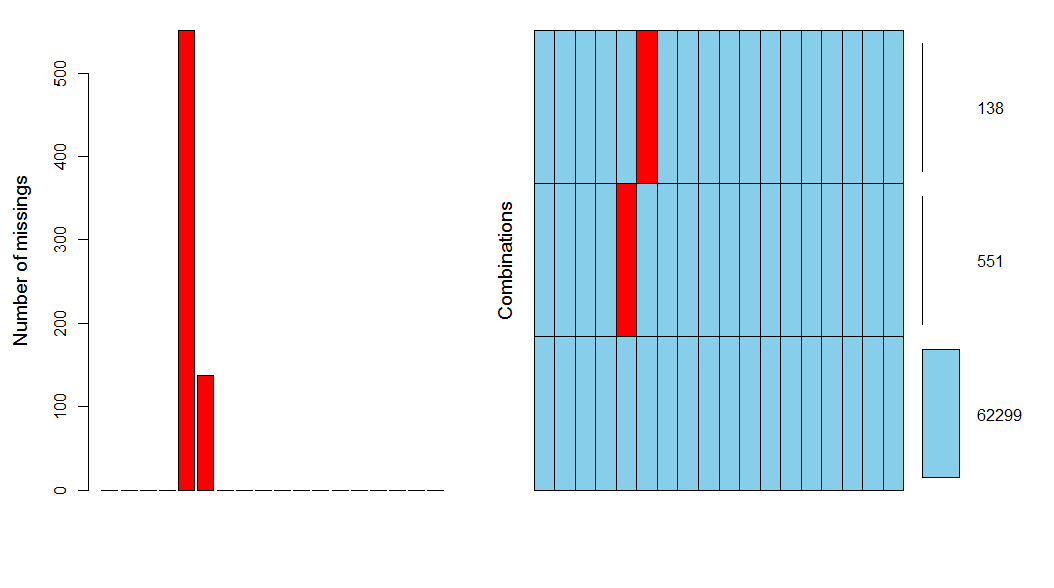
说明:只有两个变量有缺失值,且缺失值个数为138+551,较之于整体观测记录非常小可以直接删除
#缺失值和不符逻辑值处理
#删除缺失值
>airdatanew<-airdatanew[complete.cases(airdatanew),]#保留完整观测行
#去除逻辑值异常的观测,即删除票价为0,但是平均折扣和总飞行公里数大于0的记录
>index<-which(airdatanew$SUM_YR_1==0&airdatanew$SUM_YR_2==0&airdatanew$avg_discount!=0&airdatanew$SEG_KM_SUM>0)
>airdatanew<-airdatanew[-index,]
说明:删除缺失值和逻辑错误值后,剩下62051个观测
##属性规约:根据LRFMC模型挑选有用的变量
>airdatanew<-airdatanew[,c("MEMBER_NO","FFP_DATE","LOAD_TIME","LAST_TO_END","FLIGHT_COUNT","SEG_KM_SUM","avg_discount")]
>DT::datatable(airdatanew)
说明:至此,分析所需变量以筛选和清洗出来,但是挑选出来的变量要带入模型需要进行变量转换。
##数据变换
#L="LOAD_TIME"-"FFP_DATE"(观测窗口的结束时间-入会时间)(单位:月)
#R="LAST_TO_END"(最后一次乘机时间至观测窗口末端时间长)(单位:月)
#F="FLIGHT_COUNT"(观测窗口内的飞行次数)(单位:次)
#M="SEG_KM_SUM"(观测窗口的总飞行公里数)(单位:公里)
#C="avg_discount"(平均折扣率)
>airdatanew$FFP_DATE<-as.Date(airdatanew$FFP_DATE)#由于是因子变量,需要进行日期转换
>airdatanew$LOAD_TIME<-as.Date(airdatanew$LOAD_TIME)
>airdatanew$L<-as.numeric(round((airdatanew$LOAD_TIME-airdatanew$FFP_DATE)/30,3))#两日期相减得出的是天数,因而需要转化为月份数,这种转换可能和实际月份数有差别,但是不大。
>names(airdatanew)[4:7]<-c("R","F","M","C")#更改变量名
##采用多种方法对数据进行预处理
#将数据标准化处理
>airdata_scale<-scale(airdatanew[,-c(1:3)])#删除"MEMBER_NO","FFP_DATE","LOAD_TIME"这3个字段,剩余字段构建模型
>summary(airdata_scale)
#将数据进行归一化处理
>library(caret)
>airdata_range<-preProcess(airdatanew[,-c(1:3)],method = c("range"))
>airdata_range_pre<-predict(airdata_range,airdatanew[,-c(1:3)])
#将数据进行中心化处理
>airdata_center<-preProcess(airdatanew[,-c(1:3)],method = c("center"))
>airdata_center_pre<-predict(airdata_center,airdatanew[,-c(1:3)])#数据中心化是数据标准化的步骤之一,即x-均值,其并没有消除量纲的影响。
##聚类分析构建模型
>fit_kmeans_scale<-kmeans(airdata_scale,5)
>fit_kmeans_range<-kmeans(airdata_range_pre,5)
>fit_kmeans_center<-kmeans(airdata_center_pre,5)
#得出每个类别的中心
>centers_scale<-as.data.frame(fit_kmeans_scale$centers)
R F M C L
1 -0.37732916 -0.08717321 -0.09498699 -0.1557095 1.1604978
2 1.68554920 -0.57392324 -0.53674300 -0.1743790 -0.3137005
3 -0.41494899 -0.16116894 -0.16107783 -0.2530821 -0.7003074
4 -0.79944875 2.48351216 2.42472275 0.3087468 0.4829613
5 -0.00249783 -0.22544385 -0.22944009 2.1972694 0.0554208
>centers_range<-as.data.frame(fit_kmeans_range$centers)#归一化处理后,虽然数据都在0-1之间分布,但是从结果可以看出不同类别之间的区分度降低,特征反而不明显了。
R F M C L
1 0.63233743 0.01032082 0.01091188 0.4740049 0.1604486
2 0.09778936 0.07880935 0.04507924 0.4997665 0.7739829
3 0.60450929 0.01269875 0.01161781 0.4840201 0.6438978
4 0.12500165 0.04596936 0.02873297 0.4708241 0.1267417
5 0.11229993 0.06062228 0.03554612 0.4866022 0.4397122
>centers_center<-as.data.frame(fit_kmeans_center$centers)#结果可以看出其并没有消除量纲的影响,因而效果比较差,接下来不用考虑。
R F M C L
1 -144.93048 39.941543 64949.181 0.066787595 14.960921
2 -121.84085 18.093129 27394.168 0.030237551 8.645472
3 60.14267 -7.000593 -10964.442 -0.011601076 -3.325117
4 -151.46053 63.959112 141851.836 0.124879307 20.491782
5 -73.68072 3.136913 4054.564 0.004602331 2.189649
##存储每个类别的中心及频数
#标准化数据聚类结果
>centers_scale$freq<-as.data.frame(table(fit_kmeans_scale$cluster))[,2]
>centers_scale<-centers_scale[,c("freq","L","R","F","M","C")]
>write.csv(centers_scale,"centers_scale.csv",row.names = T)
对存储的数据在excel中作图分析
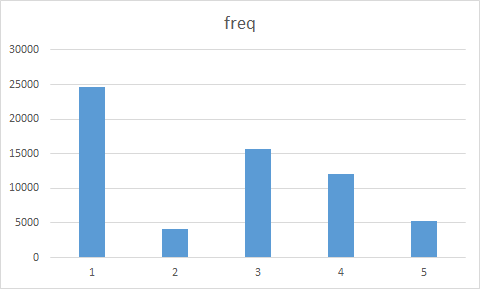
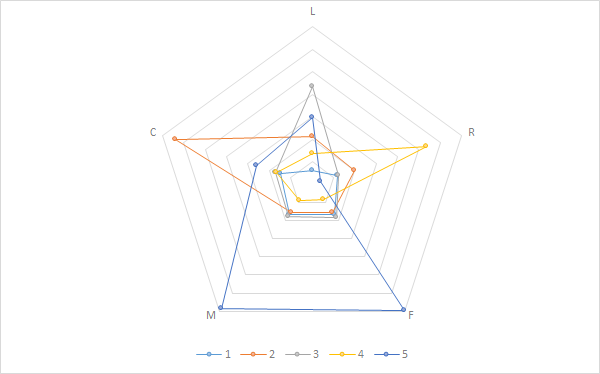
#归一化数据聚类结果
>centers_range$freq<-as.data.frame(table(fit_kmeans_range$cluster))[,2]
>centers_range<-centers_range[,c("freq","L","R","F","M","C")]
>write.csv(centers_range,"centers_range.csv",row.names = T)
对存储的数据在excel中作图分析:
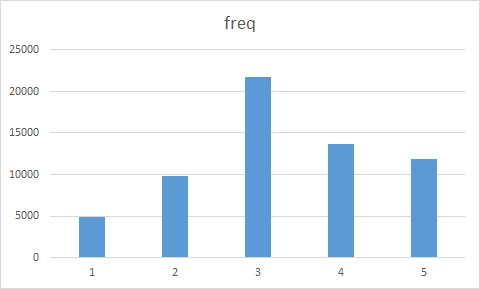
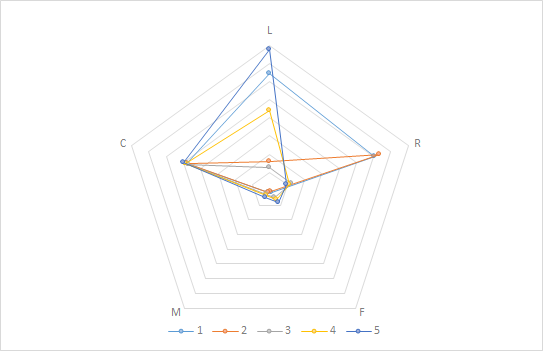
说明:
通过两种数据预处理后的聚类分析结果对比,scale后的数据聚类在LRFMC5个变量上的分布更加明显,而range后的数据聚类结果主要差别集中在L和R上,所以分辨的效果不太好,所以采用scale预处理效果比较好。
#如果需要对客户贴上聚类类别标签,则将分类标签组合到包含客户会员号的数据中
>airdatanew$cluster<-as.data.frame(fit_kmeans_scale$cluster)
##聚类结果解读和应用
L和R越大,表示时间越长。L短表示新客户,意味着要激励,长意味着要挽留,在优劣势分析时,将L越长的设置为优势。
C越大,表示折扣越低,那么暗示客户对价格不敏感
M和F越大,表示客户乘机需求越大。
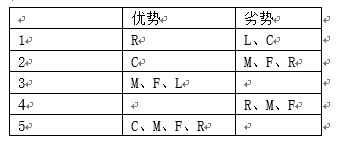
类别5的乘机需求高,折扣率排第二,其价值比较高,属于重要保持客户
类别2的乘机需求较低,但是其折扣率最高,表明其对价格不敏感,而且这部分客户量最小,属于重要发展客户。后期需要进一步刺激其需求,采取差异化策略。
类别3的乘机需求相对较高,但是其入会时间最长,因而属于重要的挽留客户。
类别4的乘机需求低,且最近乘机间隔时间最久,很有可能流失,因而属于低价值客户。
类别1的客户量最多,其乘机需求一般,但是乘机间隔较短,且入会时间最短,属于一般客户。


