你的浏览器禁用了JavaScript, 请开启后刷新浏览器获得更好的体验!
(这里是本章会用到的 GitHub 地址)
(这篇东西我真是觉得又臭又长 ┑( ̄Д  ̄)┍)
SMO 是由 Platt 在 1998 年提出的、针对软间隔最大化 SVM 对偶问题求解的一个算法,其基本思想很简单:在每一步优化中,挑选出诸多参数()中的两个参数(、)作为“真正的参数”,其余参数都视为常数,从而问题就变成了类似于二次方程求最大值的问题,从而我们就能求出解析解
具体而言,SMO 要解决的是如下对偶问题:
使得对、都有
、
其大致求解步骤则可以概括如下:
先来看如何选取参数。在 SMO 算法中,我们是依次选取参数的:
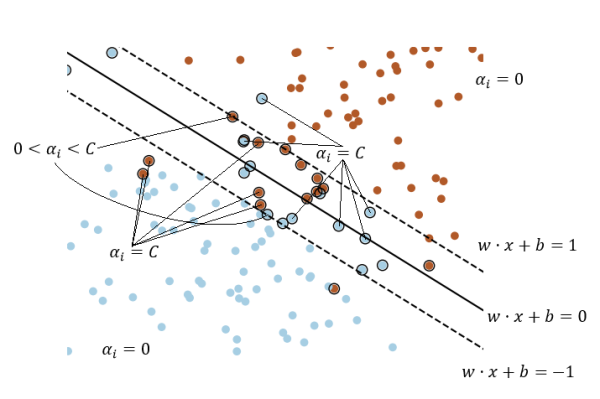
这里就有了一个叫 KKT 条件的东西,其详细的陈列会放在文末,这里就仅简要的说明一下。具体而言,对于已有的模型来说,及其对应样本的 KKT 条件为:
注意我们之前提过样本到超平面的函数间隔为,所以上述 KKT 条件可以直观地叙述为:
【注意:这里的间隔超平面即为满足方程的平面;由于可以取正负一两个值,所以间隔超平面会有两个——和。而分类超平面则是满足的平面,需要将它和间隔超平面加以区分】
可以以一张图来直观理解这里提到的诸多概念:
(画得有点乱,见谅……)
图中外面有个黑圆圈的其实就是传说中的“支持向量”,其定义会在文末给出
那么我们到底应该如何刻画“违反 KKT 条件”这么个东西呢?从直观上来说,我们可以有这么一种简单有效的定义:
得益于 Numpy 强大的 Fancy Indexing,上述置 0 的实现非常好写(???):
# 得到 alpha > 0 和 alpha < C 的 mask con1 = alpha > 0 con2 = alpha < C # 算出“差异向量”并拷贝成三份 err1 = y * y_pred - 1 err2 = err1.copy() err3 = err1.copy() # 依次根据三个 KKT 条件,将差异向量的某些位置设为 0 # 不难看出为了直观、我做了不少重复的运算,所以这一步是可以优化的 err1[(con1 & (err1 <= 0)) | (~con1 & (err1 > 0))] = 0 err2[((~con1 | ~con2) & (err2 != 0)) | ((con1 & con2) & (err2 == 0))] = 0 err3[(con2 & (err3 >= 0)) | (~con2 & (err3 < 0))] = 0 # 算出平方和并取出使得“损失”最大的 idx err = err1 ** 2 + err2 ** 2 + err3 ** 2 idx = np.argmax(err)
第二个参数则可以简单地随机选取,虽然这不是特别好,但效果已然不错,而且不仅实现起来更简便、运行起来也更快(其实就是我太懒)(喂)。具体代码如下:
idx = np.random.randint(len(self._y)) # 这里的 idx1 是第一个参数对应的 idx while idx == idx1: idx = np.random.randint(len(self._y)) return idx
至于 SMO 算法的第二步,正如前文所说,它的本质就是一个带约束的二次规划,虽然求解过程可能会比较折腾,但其实难度不大。具体步骤会放在文末,这里就暂时按下
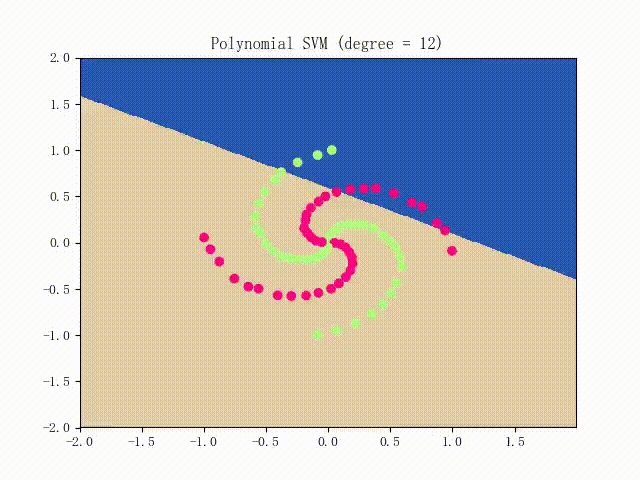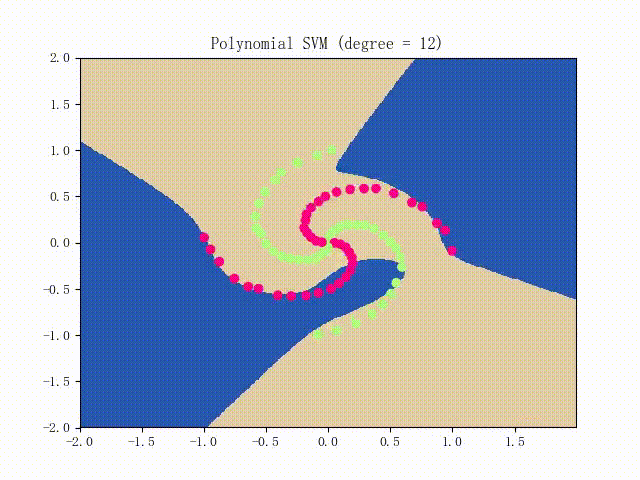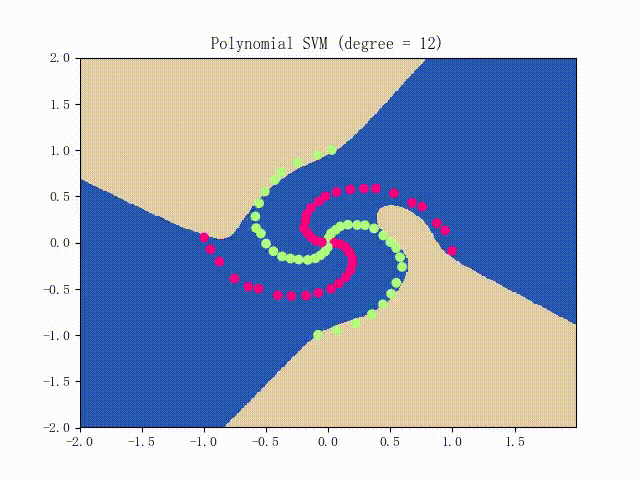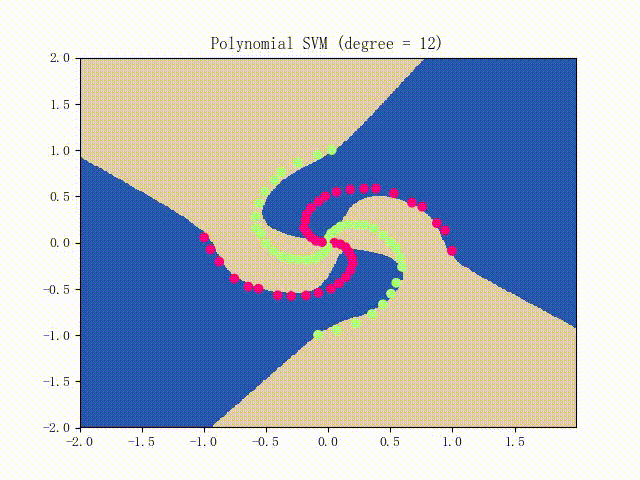
仍是先看看螺旋线数据集上的训练过程:
略显纠结,不过还是不错的
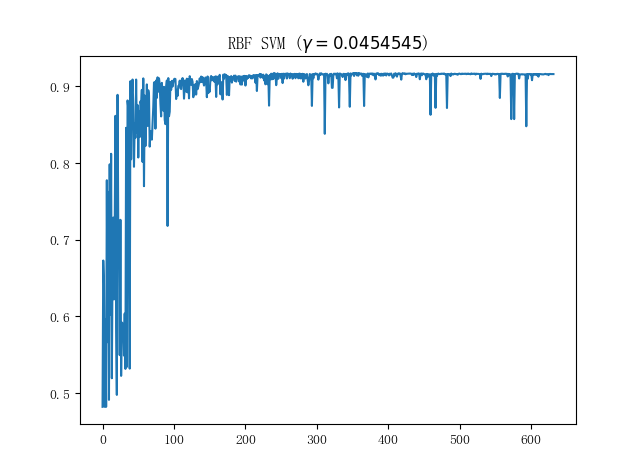
接下来看看蘑菇数据集上的表现;单就这个数据集而言,我们实现的朴素 SVM 和 sklearn 中的 SVM 表现几乎是一致的(在使用 RBF 核时),比较具有代表性的训练曲线则如下图所示:
也算是符合 SMO 这种每次只取两个参数进行更新的训练方法的直观
1)KKT 条件的详细陈列
注意到原始问题为
所以其拉格朗日算子法对应的式子为
于是 KKT 条件的其中四个约束即为(不妨设最优解为、、、和):
从而原始问题转为;而对偶问题的实质,其实就是将原始问题转为。在求解后,可以得到如下对偶问题:
(虽然这些在 Python · SVM(二)· LinearSVM 中介绍过,不过为了连贯性,这里还是再介绍一遍)
于是,最优解自然需要满足这么个条件:
这个条件即是最后一个 KKT 条件
2)何谓“支持向量”
为方便说明,这里再次放出上文给出过的图:
图中带黑圈的样本点即是支持向量,数学上来说的话,就是对应的样本点即是支持向量。从图中不难看出,支持向量从直观上来说,就是比较难分的样本点
此外,支持向量之所以称之为“支持”向量,是因为在理想情况下,仅利用支持向量训练出来的模型和利用所有样本训练出来的模型是一致的。这从直观上是好理解的,粗略的证明则可以利用其定义来完成:非支持向量的样本对应着,亦即它对最终模型——没有丝毫贡献,所以可以直接扔掉
3)带约束的二次规划求解方法
不妨设我们选取出来的两个参数就是和,那么问题的关键就在于如何把和相关的东西抽取出来并把其它东西扔掉
注意到我们的对偶问题为
且我们在 Python · SVM(一)· 感知机 的最后介绍过 Gram 矩阵:
所以就可以改写为
把和、无关的东西扔掉之后,可以化简为:
约束条件则可以化简为对和,都有、,其中是某个常数
而带约束的二次规划求解过程也算简单:只需先求出无约束下的最优解,然后根据约束“裁剪”该最优解即可
无约束下的求解过程其实就是求偏导并令其为 0。以为例,注意到
令,则亦是常数,且由于、都只能取正负 1,故不难发现,从而
于是
考虑到、、Gram 矩阵是对称阵、且模型在第个样本处的输出为,从而可知
令,则
注意到,从而
令、,则
从而
接下来就要对其进行裁剪了。注意到我们的约束为
、为常数
所以我们需要分情况讨论的下、上界
综上可知
那么直接做一个 clip 即可得到更新后的:
alpha1_new = np.clip(alpha1_new_raw, u, v)
注意由于我们要保持为常数,所以(注意)
综上所述,我们就完成了一次参数的更新,之后就不断地更新直至满足停机条件即可
此外,我在 Python · SVM(三)· 核方法 这篇文章中提到过,对 SVM 的对偶形式应用核方法会非常自然。表现在 SMO 上的话就是,我们可以通过简单粗暴地将核矩阵代替 Gram 矩阵来完成核方法的应用。直观地说,我们只需将上面所有出现过的都换成就行了
至此,SVM 算法的介绍就大致告一段落了。我们从感知机出发,依次介绍了“极大梯度法”、MBGD(Batch 梯度下降)法、核方法和 SMO 算法;虽然都有点浅尝辄止的味道,但覆盖的东西……大概还是挺多的
希望观众老爷们能够喜欢~
天源清浅
射命丸咲 回复 天源清浅
要回复文章请先登录或注册