昨天万众瞩目的2017NBA总决赛G1,想必各位JRs们都看了吧?不是骑士不尽力,奈何对面有高达,比赛结果是书包杜和打卡库双星闪耀先下一城。恰好前两天的数模课上的是多元统计,于是便复习了下主成分分析与典型相关分析的一些知识。小编今天用R语言简单的典型相关分析看看这些球员们身体数据与技术统计之间有何相关性。
1 ,典型相关分析统计原理
简单而言,典型相关分析就是在纷繁的变量关系中通过降维的方式研究两组变量之间的相关关系。通常情况下,为了研究两组变量X=(x1,x2,...xp),Y=(y1,y2,...,yq) 之间的相关关系,用最原始的方法即计算两组变量之间全部的相关系数,一共有pq个相关系数,难以抓住主要矛盾计算又非常麻烦。这时我们就可以借助主成分分析的思想,分别找出两组变量的各自某个线性组合,讨论线性组合之间的相关关系,这样问题就简化了许多。在实际问题中,这种方法也有广泛的应用,比如我们要研究产品的q个质量指标(y1,y2,...,yq) 和p个原材料指标X=(x1,x2,...xp)之间的相关关系,就可以采用典型相关分析方法来处理。
典型相关分析的核心思想如下:
首先分别在每组变量中找出第一对线性组合,使其有最大的相关性,然后再在每组变量中找出第二对线性组合,使其分别与本组内的第一对线性组合不相关,而第二对有着第二大的相关性,如此下去,直至两组变量的相关性被提取完。
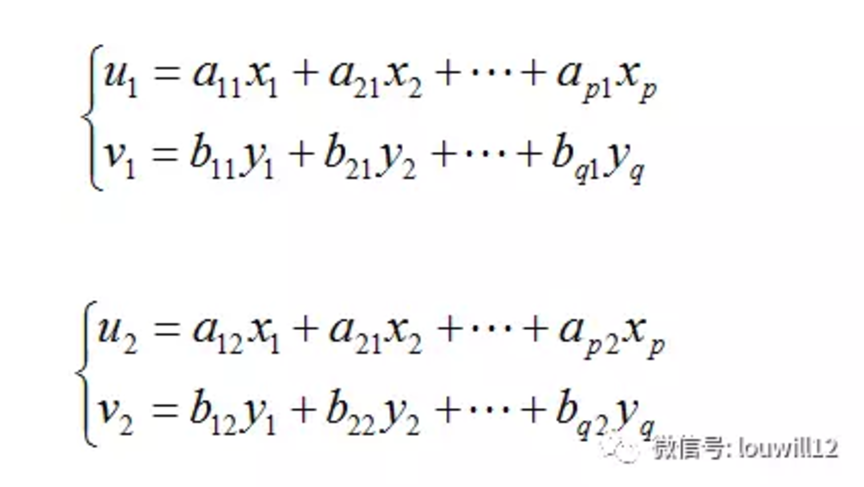
至于典型相关分析的数学推导,小编这里就不贴上了,总之推导到最后还是要转化到求优化问题上面,最近发现简直是什么问题都要求优化。
2,NBA球员的典型相关分析
至于典型相关分析的工具实现,大家可能都会用SPSS去做。SPSS里面没有提供典型相关分析的菜单选项,需要在语句窗口中调用Canonical corralation.sps宏功能。有点麻烦,所以我们今天仅用R语言的一条代码就可以实现SPSS那么繁琐的操作。小编用Rvest从NBA中文网简单抓取了部分NBA球员的身体素质数据和技术统计数据,通过筛选后提取了10名NBA联赛当红的超级球星的数据。数据包括球员姓名、身高、体重、臂展、得分、助攻、篮板、抢断、投篮命中率以及2015-16赛季以来的球队胜场数等变量。小编将这些变量指标分为两组变量:身体素质变量组和技术统计变量组。R语言中cancor函数即可实现典型相关分析。且看cancor函数使用代码:
cancor(x,y,xcenter=TRUE,ycenter=TRUE)
其中x、y为两组不同的变量数据矩阵,xcenter、ycenter取逻辑值,指的是样本是否去中心化。通过cancor函数我们简单看下NBA球员的身体素质数据与技术统计数据之间有多少相关关系。
nbaplayer<-read.csv("D:/Rdata/datasets/nbaplayer.csv")
nba<-scale(nbaplayer[,2:10])
ca<-cancor(nba[,1:3],nba[,4:9])
ca
将原始数据读入后进行scale标准化处理,然后将数据分为两组变量放入cancor函数中,ca的结果如下:
$cor
[1] 0.9916247 0.8867111 0.8023318
$xcoef
[,1] [,2] [,3]
height -0.7366761 -0.1910185 -0.6036883
weight 0.5825631 0.3859985 -0.2647233
armlet 0.3238704 -0.4418187 0.6941731
$ycoef
[,1] [,2] [,3]
scores 0.01132183 -0.1950769 0.40835815
rebounds 0.01085479 -0.6941907 0.12475701
assists 0.16098246 0.1524297 -0.29155895
steals -0.10015342 0.4211629 -0.24876921
FG 0.27541733 0.3482109 -0.56970961
wingames -0.31661763 -0.4412749 0.06668427
$xcenter
height weight armlet
6.772360e-16 -6.397660e-16 1.765255e-15
$ycenter
scores rebounds assists
2.624637e-16 4.510281e-18 -1.694391e-16
由计算结果可知,cancor函数给两组变量提取了三组相关系数,两组变量各自的线性组合为:

ui vj分别为各自变量组的线性组合,也即主成分。于是我们可知两组变量的三组线性组合之间的相关系数为0.99、0.88、0.80 。到这里我们典型相关分析还没做完,我们还得对三组的典型相关系数做显著性检验,来确定最终选择哪一组典型变量作为两组的相关关系的代表。
编写显著性检验函数:
corcoef.test<-function(r, n, p, q, alpha=0.1){
m<-length(r); Q<-rep(0, m); lambda <- 1
for (k in m:1){
lambda<-lambda*(1-r[k]^2);
Q[k]<- -log(lambda)
}
s<-0; i<-m
for (k in 1:m){
}
s<-0; i<-m
for (k in 1:m){
Q[k]<- (n-k+1-1/2*(p+q+3)+s)*Q[k]
chi<-1-pchisq(Q[k],(p-k+1)*(q-k+1))
if (chi>alpha){
i<-k-1; break
}
s<-s+1/r[k]^2
}
i
}
其中r为cor系数个数、n为样本容量、p和q为各自典型相关变量个数、alpha为置信水平。利用该自编函数我们可以对三组相关系数进行显著性检验:
corcoef.test(r=ca$cor,n=10,p=3,q=3)
[1] 3
由结果看以得出:虽然前两组的相关系数很大,两组变量之间的相关性明显,但在0.1的置信水平下通过不了显著性检验,所以我们选择第三组作为两组变量之间的相关关系的代表。计算结果表明,NBA球员们的身体素质和其个人技术统计表现有着密切的关系,詹皇库里们之所以有着傲人的技术统计数据,这是与他们自身优秀的身体素质是分不开哒,当然了,这背后肯定少不了日复一日、年复一年的职业体育的艰苦训练啦。
原本还想做个pls偏最小二乘回归的,但是发现数据支撑不太好,自变量不太好选择,也就放弃啦。有些人可能会说,你这分析没什么技术含量和实际意义,NBA球员的身体素质普遍那么高,可并不是个个都能像威少哈登那样数据骇人的。说的没错,但小编此举只是为了测试在R语言中典型相关分析的实现方法,旨在锻炼实际的数据分析能力,各位JRs们尽可付之一笑就好。最后放张图,祝两队在G2中打出更精彩的表现。





