QQmining,这是我第一次尝试写的R包,由于还存在着一些警告问题,所以还无法从github上面进行安装,但是可以本地进行安装。如果要访问我的github,请点击阅读原文。如果你需要这个包的话就在后台回复QQmining 即可获取百度网盘分享链接。
不过这个包是我在R 3.3.2版本开发的,尽量在3.3.2版本或更新的版本上面使用。
现在来对这个包进行一个简单介绍。
首先这个包依赖以下五个包,分别为:
rJava,Rwordseg,dplyr,wordcloud2,ggplot2
因此你在使用这个包的时候一定要确保已经装了这五个包。将QQmining包下载之后直接复制到library文件夹里面即可直接加载使用。
QQmining这个包有四个函数,作用分别如下:
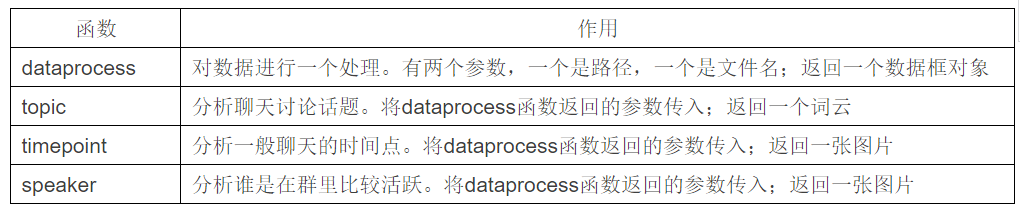
如果你也可以查看帮助文档,比如查看topic()函数,既可以输入指令
?topic
就可以查看,不过由于时间上的关系,帮助文件写的比较简单粗糙,还存在许多问题,用的时候希望大家不要太在意细节(偷笑)。
那么我们现在就用四行代码来分析一个QQ群的聊天记录吧!

qqdata<-dataprocess ("C:/Users/henry wang/Desktop/",
"数据分析师之家.txt")

topic(qqdata)
结果如下:

因为我们没有删除停用词,所以说效果不是很好。

timepoint(qqdata)
结果如下:


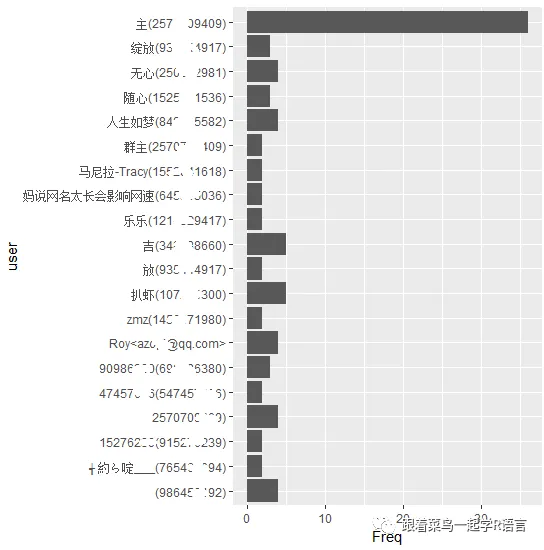
speaker(qqdata)
结果如下:
好了,我们用了4行代码就轻轻松松的分析了一份QQ聊天记录,是不是很简单。但是这个包对以下情况可能会出现一些错误

原因:如果存在语音聊天记录,在导出的.TXT文件里面是空白的一行。在删除NA之后无法合并在一个数据框里面。如下图:


原因:speaker()函数分析活跃成员时,用户名作为一个坐标轴的属性,ggplot函数无法识别一些特殊字符则报错。如下图:

总结
一方面,这个包是我做的第一个包,也许还存在着一些bug,如果遇到了欢迎告诉我;另外一方面,这个包功能还太简单,每一个函数也只有一到两个参数,对于输出结果也太单一。在后期我也会继续对这个包进行更新和完善,让每一个函数包含更多的参数,不断丰富每一个函数的功能。谢谢大家的支持。


