第一篇 Hadoop环境搭建部分,分为3个章节。
Haddop环境准备
Hadoop完全分步式集群搭建
HDFS测试
每一章节,都会分为”文字说明部分”和”代码部分”,保持文字说明与代码的连贯性。
Haddop环境准备
文字说明部分:
首先环境准备,这里我选择了Linux Ubuntu操作系统12.04的64位版本,大家可以根据自己的使用习惯选择顺手的Linux。
但JDK一定要用Oracle SUN官方的版本,请从官网下载,操作系统的自带的OpenJDK会有各种不兼容。JDK请选择1.6.x的版本,JDK1.7版本也会有各种的不兼容情况。
http://www.oracle.com/technetwork/java/javase/downloads/index.html
完全分步式的Hadoop集群,这个选择5台一样配置的虚拟机,通过内网的一个DNS服务器,指定5台虚拟机所对应的域名。
每台虚拟机,1G内存,系统硬盘2G,外接硬盘16G。hadoop会存储在外接硬盘上面。
外接硬盘,需要先进行格式化,然后创建目录,再mount到操作系统,通过修改/etc/fstab配置,系统每次重起都是自动加载外接硬盘。
(如果用户操作系统的硬盘够大,不用外接硬盘,这步可以省略)
接下来,为hadoop集群创建访问账号hadoop,创建访问组hadoop,创建用户目录/home/hadoop,把账号,组和用户目录绑定。
再为hadoop的hdfs创建存储位置/hadoop/conan/data0,给hadoop用户权限。
设置SSH自动登陆,从nn.qa.com虚拟机开始,通过ssh-keygen命令,生成id_rsa.pub,再合并到 authorized_keys的文件。再通过scp把authorized_keys复制到其他的虚拟机。循环生成authorized_keys并合并文件。使得5台虚拟机,都有了相互的SSH自动登陆的配置。
环境准备完成,参考下面代码部分,动手实现。
代码部分:
1. 操作系统Ubuntu 12.04 x64
~ uname -a
Linux domU-00-16-3e-00-00-85 3.2.0-23-generic #36-Ubuntu SMP Tue Apr 10 20:39:51 UTC 2012 x86_64 x86_64 x86_64 GNU/Linux
2. JAVA环境
~ java -version
java version "1.6.0_29"
Java(TM) SE Runtime Environment (build 1.6.0_29-b11)
Java HotSpot(TM) 64-Bit Server VM (build 20.4-b02, mixed mode)
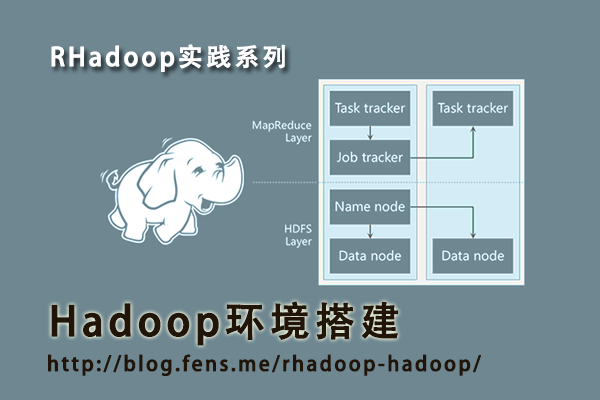
3. Hadoop集群:5台机器,1个NameNode,4个DataNode,通过DNS指定域名
虚拟机名字 域名 内存 硬盘
namenode: nn.qa.com 1G 2G+16G
datanode1: dn0.qa.com 1G 2G+16G
datanode2: dn1.qa.com 1G 2G+16G
datanode3: dn2.qa.com 1G 2G+16G
datanode4: dn3.qa.com 1G 2G+16G
挂载硬盘16G
1. mkfs.ext4 -j /dev/xvdb
2. mkdir /hadoop
3. mount /dev/xvdb /hadoop
4. vi /etc/fstab
/dev/xvdb /hadoop ext4 noatime 0 1
创建hadoop账号和组
1. groupadd hadoop
2. useradd hadoop -g hadoop;
3. passwd hadoop
4. mkdir /home/hadoop
5. chown -R hadoop:hadoop /home/hadoop
创建hadoop工作目录
1. mkdir /hadoop/conan/data0
2. chown -R hadoop:hadoop /hadoop/conan/data0
配置ssh及密码
nn.qa.com:
1. su hadoop
2. ssh-keygen -t rsa
3. cd /home/hadoop/.ssh/
4. cat id_rsa.pub >> authorized_keys
5. scp authorized_keys dn0.qa.com:/home/hadoop/.ssh/
dn0.qa.com:
1. su hadoop
2. ssh-keygen -t rsa
3. cd /home/hadoop/.ssh/
4. cat id_rsa.pub >> authorized_keys
5. scp authorized_keys dn1.qa.com:/home/hadoop/.ssh/
dn1.qa.com:
1. su hadoop
2. ssh-keygen -t rsa
3. cd /home/hadoop/.ssh/
4. cat id_rsa.pub >> authorized_keys
5. scp authorized_keys dn2.qa.com:/home/hadoop/.ssh/
dn2.qa.com:
1. su hadoop
2. ssh-keygen -t rsa
3. cd /home/hadoop/.ssh/
4. cat id_rsa.pub >> authorized_keys
5. scp authorized_keys dn3.qa.com:/home/hadoop/.ssh/
dn3.qa.com:
1. su hadoop
2. ssh-keygen -t rsa
3. cd /home/hadoop/.ssh/
4. cat id_rsa.pub >> authorized_keys
5. scp authorized_keys nn.qa.com:/home/hadoop/.ssh/
nn.qa.com:
1. su hadoop
2. cd /home/hadoop/.ssh/
3. scp authorized_keys dn0.qa.com:/home/hadoop/.ssh/
4. scp authorized_keys dn1.qa.com:/home/hadoop/.ssh/
5. scp authorized_keys dn2.qa.com:/home/hadoop/.ssh/
6. scp authorized_keys dn3.qa.com:/home/hadoop/.ssh/
Hadoop完全分步式集群搭建
文字说明部分:
说明:本文以hadoop-0.20.2为例,与系列中其他几篇文章中的hadoop-1.0.3版本,安装和配置上是一样。
首先,我们在namenode(nn.qa.com)节点上面,下载hadoop。
修改hadoop配置文件hadoop-env.sh,hdfs-site.xml,core-site.xml,mapred-site.xml,设置master和slaves节点
把配置好的namenode(nn.qa.com)节点,用scp复制到其他4台虚拟机同样的目位置。
启动namenode(nn.qa.com)节点,
第一次启动时要先进行格式化,bin/hadoop namenode -format
启动hadoop,bin/start-all.sh
输入jps命令,可以看到所有Java的系统进程。 只要下面三个系统进程出现,SecondaryNameNode,JobTracker,NameNode,就恭喜你hadoop启动成功。
通过netstat -nl,可以检查系统打开的端口。其中包括,hdfs的9000,jobtracker的9001,namenode的web监控的50070,Map/Reduce的web监控的50030
其他的节点的测试检查是一样的,在这里就不重复说明了。
代码部分:
下载及配置hadoop
nn.qa.com:
1. cd /hadoop/conan
2. wget http://mirror.bjtu.edu.cn/apache/hadoop/common/hadoop-0.20.2/hadoop-0.20.2.tar.gz
3. tar zxvf hadoop-0.20.2.tar.gz
4. cd /hadoop/conan/hadoop-0.20.2/conf
5. vi hadoop-env.sh
export JAVA_HOME=/etc/java-config-2/current-system-vm
6. vi hdfs-site.xml
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/hadoop/conan/data0</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
7. vi core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://nn.qa.com:9000</value>
</property>
</configuration>
8. vi mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>nn.qa.com:9001</value>
</property>
</configuration>
9. vi masters
nn.qa.com
10. vi slaves
dn0.qa.com
dn1.qa.com
dn2.qa.com
dn3.qa.com
同步hadoop配置到其他虚拟机
- cd /hadoop/conan
- scp -r ./hadoop-0.20.2 dn0.qa.com:/hadoop/conan
- scp -r ./hadoop-0.20.2 dn1.qa.com:/hadoop/conan
- scp -r ./hadoop-0.20.2 dn2.qa.com:/hadoop/conan
- scp -r ./hadoop-0.20.2 dn3.qa.com:/hadoop/conan
启动namenode节点
- cd /hadoop/conan/hadoop-0.29.2
- bin/hadoop namenode -format
- bin/start-all.sh
检查hadoop启动是否成功
- jps
9362 Jps
7756 SecondaryNameNode
7531 JobTracker
7357 NameNode
- netstat -nl
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:5666 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8649 0.0.0.0:* LISTEN
tcp6 0 0 :::50070 :::* LISTEN
tcp6 0 0 :::22 :::* LISTEN
tcp6 0 0 :::39418 :::* LISTEN
tcp6 0 0 :::32895 :::* LISTEN
tcp6 0 0 192.168.1.238:9000 :::* LISTEN
tcp6 0 0 192.168.1.238:9001 :::* LISTEN
tcp6 0 0 :::50090 :::* LISTEN
tcp6 0 0 :::51595 :::* LISTEN
tcp6 0 0 :::50030 :::* LISTEN
udp 0 0 239.2.11.71:8649 0.0.0.0:*
HDFS测试
文字说明部分:
hadoop环境启动成功,我们进行一下hdfs的简单测试。
通过命令在hdfs上面,创建一个目录bin/hadoop fs -mkdir /test
通过命令复制一个本地文件到hdfs文件系统中,bin/hadoop fs -copyFormLocal README.txt /test
通过命令查看刚刚上传的文件bin/hadoop fs -ls /test
代码部分:
nn.qa.com:
- cd /hadoop/conan/hadoop-0.29.2
- bin/hadoop fs -mkdir /test
- bin/hadoop fs -copyFormLocal README.txt /test
- bin/hadoop fs -ls /test
Found 1 items
-rw-r--r-- 2 hadoop supergroup 1366 2012-08-30 02:05 /test/README.txt
最后,恭喜你完成了,hadoop的完成分步式安装,环境成功搭建。
继续学习,请看第二篇 RHadoop实践系列文章之RHadoop安装与使用。
注:由于两篇文章并非同一时间所写,hadoop版本及操作系统,分步式环境都略有不同。
两篇文章相互独立,请大家在理解的基础上动手实验,不要完成依赖两篇文章中的运行命令。
作者介绍:
张丹,R语言中文社区专栏特邀作者,《R的极客理想》系列图书作者,民生银行大数据中心数据分析师,前况客创始人兼CTO。
10年IT编程背景,精通R ,Java, Nodejs 编程,获得10项SUN及IBM技术认证。丰富的互联网应用开发架构经验,金融大数据专家。个人博客 http://fens.me, Alexa全球排名70k。
著有《R的极客理想-工具篇》、《R的极客理想-高级开发篇》,合著《数据实践之美》,新书《R的极客理想-量化投资篇》(即将出版)。

《R的极客理想-工具篇》京东购买快速通道:https://item.jd.com/11524750.html
《R的极客理想-高级开发篇》京东购买快速通道:https://item.jd.com/11731967.html
《数据实践之美》京东购买快速通道:https://item.jd.com/12106224.html
