
01 测试与训练
机器学习的目的,就是要让程序从已知的数据中自己找出规律,然后将规律应用到未知的数据中去。不同于常规程序的步骤,由程序员事先设置好各种条件与跳转指令或者步骤,由程序一步步执行,直到程序结尾。机器学习的程序,程序员只负责设计程序如何去学习,至于学到什么规律,那主要是由给定的数据来决定的。再将学到的规律,应用到未知的数据集上去,这才是机器学习的核心魅力。
这其中便涉及两份数据集,一份给“机器”用于学习的数据,通常也叫训练数据集(training data),机器学习到的知识,通常叫模型。最后机器使用学习到的模型,对未知数据进行预测,这份数据通常叫测试数据(testing data)。因此,在程序中,会看到大量的train和test相关的变量,基本上的意思都指训练数据与测试数据相关。
比如,有一份数据如下:
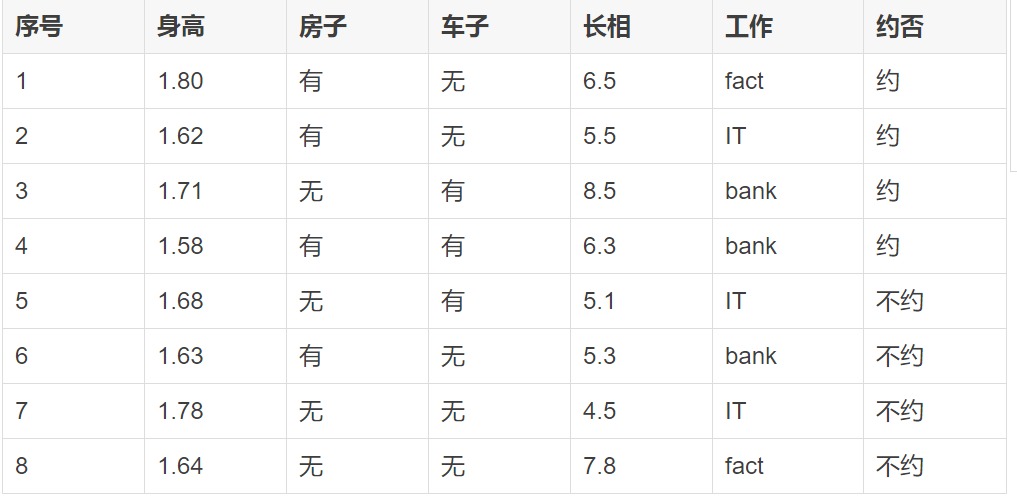
这份数据是过往的约会记录,全部信息都是来自于真实的记录,本身并不需要我们进行预测。我们的目的,是希望通过这份数据,来构建一个预测模型,预测一个新的对象会不会约会的模型。
那么,问题来了:构建机器学习模型时最重要的是什么?是模型的评估,即如何评价一个模型的好坏,或者说模型的准确率(或者误差率)到底如何。当然,如果还有另外一份过往的记录数据,我们可以用上面8条数据构建一个模型,然后用那份记录来进行测试,看预测的结果和记录的结果相同的次数,从而计算模型的准确率。
但问题是,假定只有这8条过往的记录,没有更多的数据,如何评价构建的模型的好坏呢?聪明如你,肯定已经想到了。可以把这8条记录分成两份,第一份为6条数据,第二份为2条数据,用第一份的6条数据来构建预测模型,然后将模型应用到第二份的2条数据,进行预测。预测时只需要传前面5个特征,最后的“约”与”不约“不作为特征,这个正是要预测的结论。看预测的“约”与“不约”结论是否和本身的记录一致,如果2条预测结果与原来数据记录的结果都一致,那么说明模型准确率为100%;如果只预测对一条,那么为50%;如果全部预测错误,那么模型准确率为0,此时就需要回过头去分析一下,看模型是否用对,或者参数是否都设置正确了。
02 交叉验证
验证模型准确率,是机器学习非常重要的内容。前面将数据手工切分为两份,一份做训练(train),一份做测试(test)便是最常用的手段。
术语上,叫交叉验证(Cross Validation),上面的方式,便是其中的“留一手”(Hold-Out)交叉验证。
交叉验证,在scikit-learn中,位于sklearn.cross_validation包中,而”留一手“的方式,使用train_test_split方法很容易实现:
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=42)
其中的X为特征数据,y为响应变量,test_size=0.1表示将数据按90%的训练与10%的训练比例进行划分。因为程序会对原数据进行随机切分,而设置random_state是为了在对程序进行调试的时候,能保证每次都按固定的随机序列进行划分。
上面的“留一手”划分方式,通常留下的“一手”不只一个。还有极端的情况,“留一个”(Leave-One-Out),即只保留一条数据作为测试数据,剩下全部用于训练模型。训练好的模型,用这留下的一条数据来进行训练,在分类上,准确率要么是0,要么是100%。
当然,睿智如你般,肯定也想到了,上面的方式也有局限。因为只进行一次测试,并不一定能代表模型的真实准确率。因为,模型的准确率和数据的切分有关系,在数据量不大的情况下,影响尤其突出。自然,前辈们也早就想到了,并提出了比较好的解决方案。
那就是采用K折(K-Flod)交叉验证,将数据随机且均匀的分成K份,常用的K为10,数据预先分好并保持不动。假设每份数据的标号为0-9,第一次使用标号为0-8的共9份数据来作训练,而使用标号为9的这一份数据来进行测试,得到一个准确率。第二次使用标记为1-9的共9份数据进行训练,而使用标号为0的这份数据进行训练,得到第二个准确率,以此类推,每次使用9份数据作为训练,而使用剩下1份进行训练,这样共进行10次,最后模型的准确率为10次准确率的平均值。这样便避免了由于数据划分而造成的评估不准确的问题。
K-Flod交叉验证的方式,经常在实际的项目中使用。通常一个模型没有经过K-Fold的评估,那么得出的准确率都是不太可靠的。
也可以在K-Fold交叉验证的时候使用“留一个”的方式,即训练多个模型,让每条数据都有机会作一次测试,而除了作为测试的那条数据外,剩下的全部用于训练。这样有多少条数据,就训练多少个模型,然后这些模型的平均准确率为最后模型的准确率。但因为这样的训练代价太高(通常是太费时),实际上估计很少采用。
03 验证数据
使用训练数据与测试数据进行了交叉验证,只有这样训练出的模型才具有更可靠的准确率,也才能期望模型在新的、未知的数据集上,能有更好的表现。这便是模型的推广能力,也即泛化能力的保证。
除了最常用的training data与testing data外,在一些算法中,还会用到validation data(验证数据),其作用和testing data差不多。
Validation data通常是直接应用于模型的构建过程中,尤其是多次迭代的算法中,比如多层神经网络算法中,算法在每一轮迭代过程中,会更新网络连接中各层的权重值,当完成一轮更新过后,算法会使用验证数据(validation data)来进行一次验证,以测试在这份数据上,算法的改进效果。
和testing data的主要区别,是验证数据用来调整模型的参数,以及用来设置提前停止(Early stop)的条件,比如在深度学习框架keras中,有如下示例代码:
save_best = ModelCheckpoint('model.nn', verbose=1, save_best_only=True)
early_stop = EarlyStopping(monitor='val_loss', patience=10, verbose=1)
model.fit(X_train, y_train,
batch_size=64,
nb_epoch=100,
show_accuracy=False,
validation_split=0.1,
callbacks=[save_best, early_stop],
verbose=1)
说明:
通过参数validation_split来设置在训练数据中分出10%来作为验证数据,剩下90%作为训练数据。
通过定义两个回调函数,early_stop这个回调方法,就是指让程序监控val_loss(validation loss)这个条件,容忍度为10次,即在迭代10次的过程中,在验证数据上的验证效果(通过val_loss体现)都没有改善(降低),那么就停止运行。
另外一个回调方法save_best保证在每轮迭代的过程中,只要在验证数据上效果有改善,就将训练好的模型进行覆盖保存,没有改善则不保存。这样保证在early_stop退出的时候,保存的模型是训练过程中最好的。
04 OOB数据
随机森林(Random Forest)算法中,在构建每颗树的时候,对原始数据都是采取的有放回抽样,根据统计发现,每次都有大约1/3的数据不会被选中,即用于构建每颗决策树的数据都大约只有原数据的2/3,那么其中的1/3未被选中的数据,也就叫袋外数据OOB(Out Of Bag)。
这部分数据没有参与构建决策树,正好可以被利用来对模型进行评估。它甚至可以取代前面使用的测试集来评估模型误差,因为它并没有参与模型的训练,正是天然的测试数据。每颗树的OOB数据都是不太相同的,测试的时候,也是用每颗树自己的OOB数据来进行测试,最后组合所有OOB数据的测试结果,并求平均(回归问题)。
在scikit-learn的随机森林中,参数oob_score(bool型),用于配置是否使用oob样本来评估模型的泛化误差的参数。当设置为true后,在最后的模型上,即可以通过 oob_score_ 这个属性来打印模型的oob分数。oob_score_这个属性,获取的是使用OOB数据测试的R^2(判定系数)分数,也即是在oob_prediction_数据上的R^2分数。
比如,一共有10颗树,第一颗没有被选中的袋外数据(OOB)为编号1,5,8,9,那么就用这些编号的数据,来对第一颗树进行测试,得出的值为y11,y15,y18,y19(第一个下标为树的编号,第二个下标为数据编号),依此类推。测试全部的10颗树,其中可能编码为1的数据,测试了2次,最后求两次的平均(回归问题),即为编码为1的数据在随机森林模型中的预测值。将所有的OOB数据的预测值与真实值求一次R^2系数,即为模型oob_score_的值。
另外,如果需要对训练数据本身的预测,也需要使用oob_prediction_这个属性,这个属性是使用oob的样本来对模型进行预测,而不是训练数据。如果直接将训练数据送入predict()方法中去,得出的结论和原来的基本上是一样的,因为完全生长的决策树,会简单的存储所有的分支,使用训练数据构建得出的决策树,再对训练数据进行测试,结果当然不会变。
