记录下爬取招聘网站上Python实习信息,为了找实习做好准备。
======================================================================
环境准备:
Python3.5
PyCharm
fake_useragent
实习僧还是挺不错的网站,打开http://www.shixiseng.com/interns?k=Python
打算把职位名称、地点、公司、薪水和职位的URL爬取并保存下来
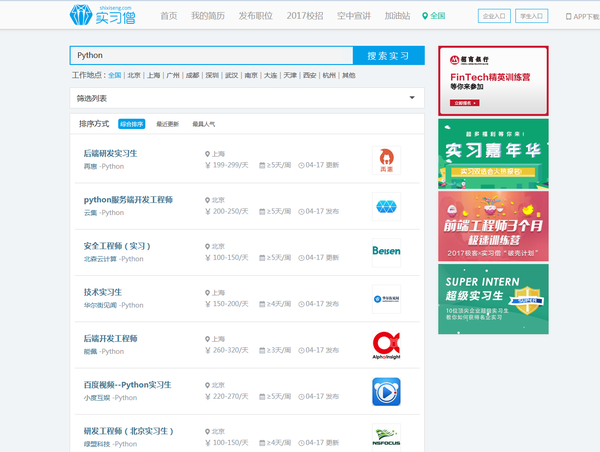
对页面简单分析,发现需要三步爬取所需信息。
1、爬取搜索页面的职位、地点、公司、薪水
用到的工具是requests加xpath,直接上代码
job = []
location = []
company = []
salary = []
link = []
for k in range(1, 10):
url = 'http://www.shixiseng.com/interns?k=python&p=' + str(k)
r = requests.get(url, headers=headers).text
s = etree.HTML(r)
job1 = s.xpath('//a/h3/text()')
location1 = s.xpath('//span/span/text()')
company1 = s.xpath('//p/a/text()')
salary1 = s.xpath('//span[contains(@class,"money_box")]/text()')
link1 = s.xpath('//div[@class="job_head"]/a/@href')
for i in link1:
url = 'http://www.shixiseng.com' + i
link.append(url)
salary11 = salary1[1::2]
for i in salary11:
salary.append(i.replace('\n\n', ''))
job.extend(job1)
location.extend(location1)
company.extend(company1)
job,location,company,salary,link都是list,方便接下来的文件写入
网页只有9页,每一页有10条职位信息,一共90个职位。
可以使用print打印出来看看,结果对不对

fake-useragent是一个可以伪造浏览器头的库,非常好用 hellysmile/fake-useragent
用法:
from fake_useragent import UserAgent
ua = UserAgent()
ua.ie
# Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US);
ua.msie
# Mozilla/5.0 (compatible; MSIE 10.0; Macintosh; Intel Mac OS X 10_7_3; Trident/6.0)'
ua['Internet Explorer']
# Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; GTB7.4; InfoPath.2; SV1; .NET CLR 3.3.69573; WOW64; en-US)
ua.opera
# Opera/9.80 (X11; Linux i686; U; ru) Presto/2.8.131 Version/11.11
ua.chrome
# Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2'
ua.google
# Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4) AppleWebKit/537.13 (KHTML, like Gecko) Chrome/24.0.1290.1 Safari/537.13
ua['google chrome']
# Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11
ua.firefox
# Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:16.0.1) Gecko/20121011 Firefox/16.0.1
ua.ff
# Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:15.0) Gecko/20100101 Firefox/15.0.1
ua.safari
# Mozilla/5.0 (iPad; CPU OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5355d Safari/8536.25
# and the best one, random via real world browser usage statistic
ua.random
2、爬取职位详细页面的信息
打开第一个职位页面 http://www.shixiseng.com/intern/inn_geghnqp8j3oz
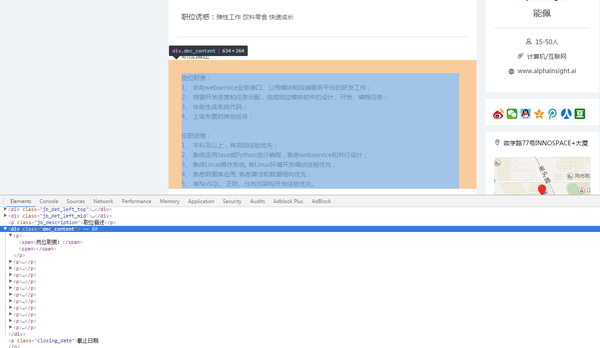 发现所有的描述都在class="dec_content"的div标签下,原本是想使用xpath解析,但是发现了一个问题,某些职位描述是在<span>标签下,某些是在<p>标签下
发现所有的描述都在class="dec_content"的div标签下,原本是想使用xpath解析,但是发现了一个问题,某些职位描述是在<span>标签下,某些是在<p>标签下
 不懂为什么会这样。。
不懂为什么会这样。。
最后选择BeautifulSoup来解决问题
detail = []
for i in link:
r = requests.get(i, headers=headers).text
soup = BeautifulSoup(r, 'lxml')
word = soup.find_all(class_="dec_content")
for i in word:
a = i.get_text()
detail.append(a)
detail也是一个list,get_text()去除标签
OK下一步啦
3、将所爬到的信息保存下来
使用xlwt来保存到excel文件中
book = xlwt.Workbook()
sheet = book.add_sheet('sheet', cell_overwrite_ok=True)
path = 'D:\\Pycharm\\spider'
os.chdir(path)
j = 0
for i in range(len(job)):
try:
sheet.write(i + 1, j, job[i])
sheet.write(i + 1, j + 1, location[i])
sheet.write(i + 1, j + 2, company[i])
sheet.write(i + 1, j + 3, salary[i])
sheet.write(i + 1, j + 4, link[i])
sheet.write(i + 1, j + 5, detail[i])
except Exception as e:
print('出现异常:' + str(e))
continue
book.save('d:\\python.xls')
最后的结果:
 密集恐惧症表示受不了啦
密集恐惧症表示受不了啦
现在我们已经把信息保存下来了,下一步就是对这些信息 进行分析了。
初步想法是,对地点、薪水分析,看看Python实习哪些地方需求大,工资水平如何。对职位要求的分析,基本可以知道需要哪方面的技能才能应聘实习岗位。这些东西下期再说啦=_=
GitHub:zhangslob/PythonIntern
请遵循robots协议 http://www.shixiseng.com/robots.txt
User-agent: *
Disallow: /user/login
Disallow: /user/login?*
Disallow: /user/register
Disallow: /user/register?*
Disallow: /summerstorm/feedback
Sitemap: http://www.shixiseng.com/sitemap.xml
喜欢写爬虫吗? 喜欢就加入我新建的群(个人微信:zhang7350)
======================================================================
最近知乎好像对Python这一块关注比较多,好像大V都抵制爬虫,萌新表示难以理解。
爬虫只是最基本的数据收集,数据清洗、数据分析、可视化才是重点。
但是就Python爬虫这一块,保存信息到数据库、多线程、分布式、代理设置、Ajax请求、PySpider、Scrapy框架、Selenium、Redis、图像识别与文字处理等等,以上这些我都不会
所以我还是会继续写爬虫文章,不喜欢就不看呗。

