





本站文章版权归原作者及原出处所有 。内容为作者个人观点, 并不代表本站赞同其观点和对其真实性负责。本站是一个个人学习交流的平台,并不用于任何商业目的,如果有任何问题,请及时联系我们,我们将根据著作权人的要求,立即更正或者删除有关内容。本站拥有对此声明的最终解释权。
25 个评论
可以有
请问 为什么我的preview里只有{"code":0,"data":0,"msg":"suc"},定位不到任何内容
那应该怎么办呢,怎么根据网页新结构定位呢
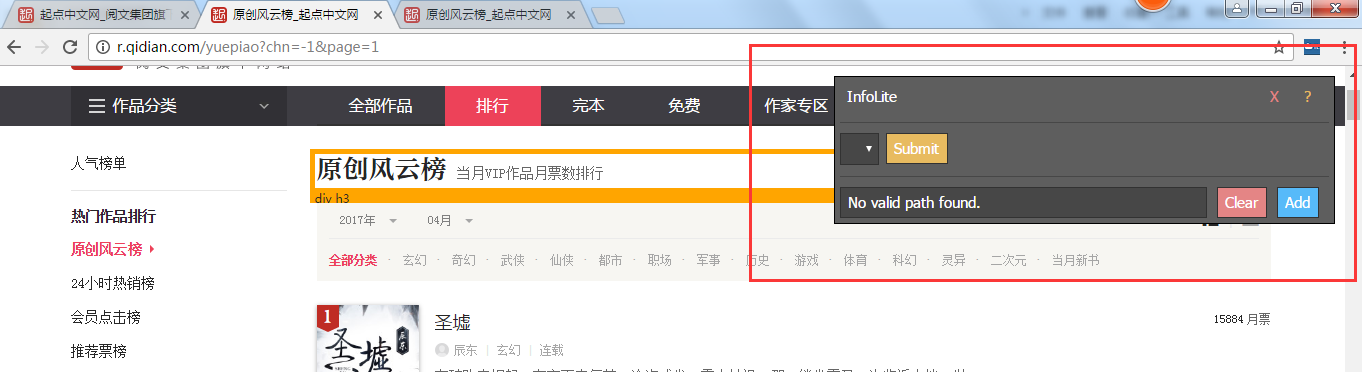
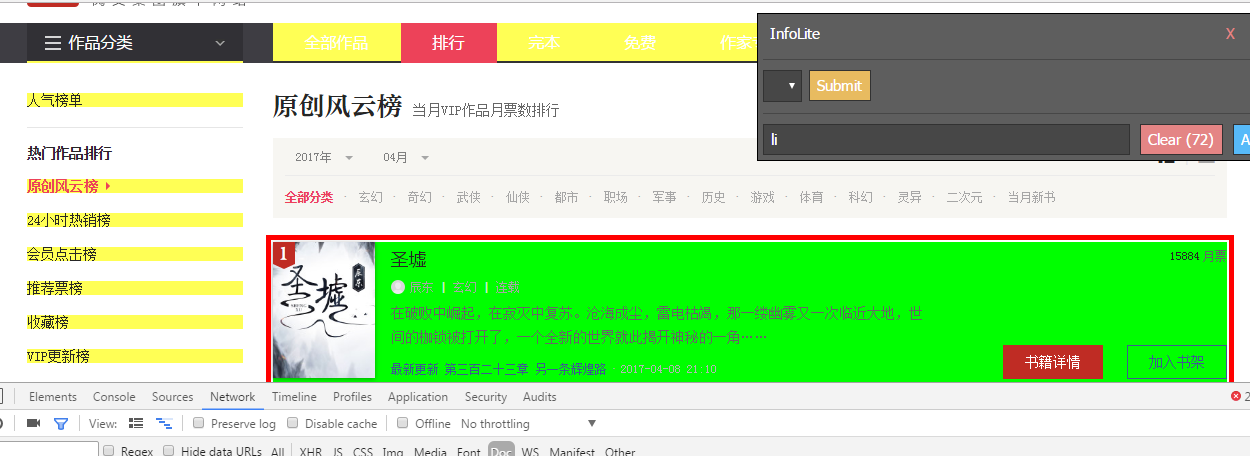
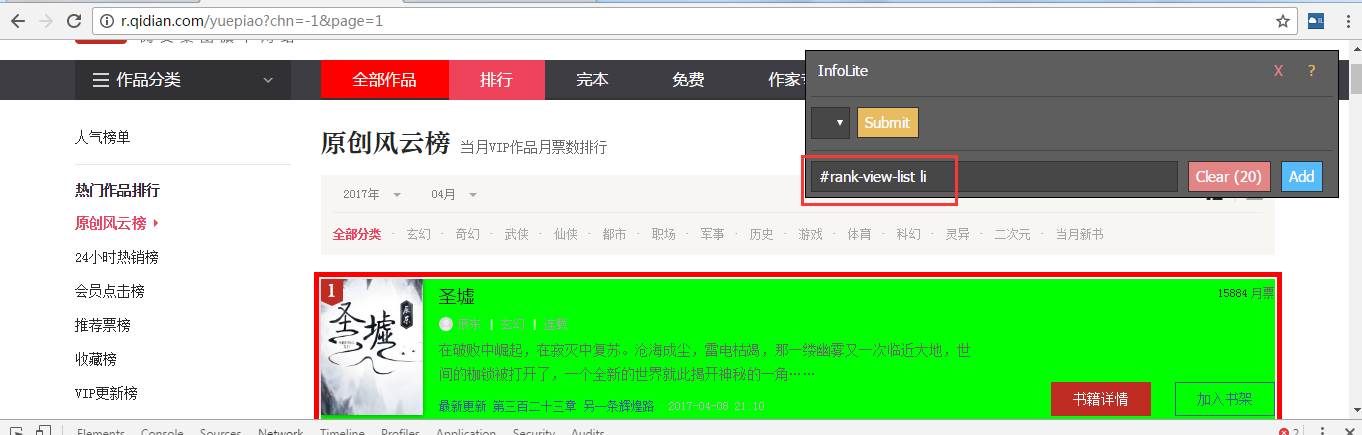
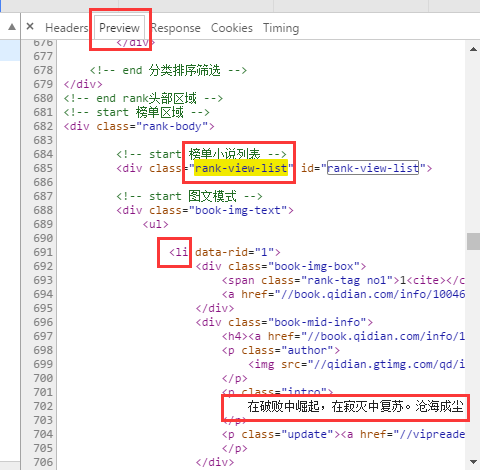
for news in soup.select('.rank-view-list li'):#定位
print(news)
为什么运行后只有“最新更新 第七百二十五章 灭个干净。。。“这些数据,前面题目介绍都不显示,我就是按照你写的代码运行的
print(news)
为什么运行后只有“最新更新 第七百二十五章 灭个干净。。。“这些数据,前面题目介绍都不显示,我就是按照你写的代码运行的
起点的网站结构变了,把上面那条语句替换成这个就可以了,不然爬取不到评论
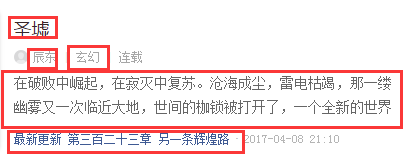
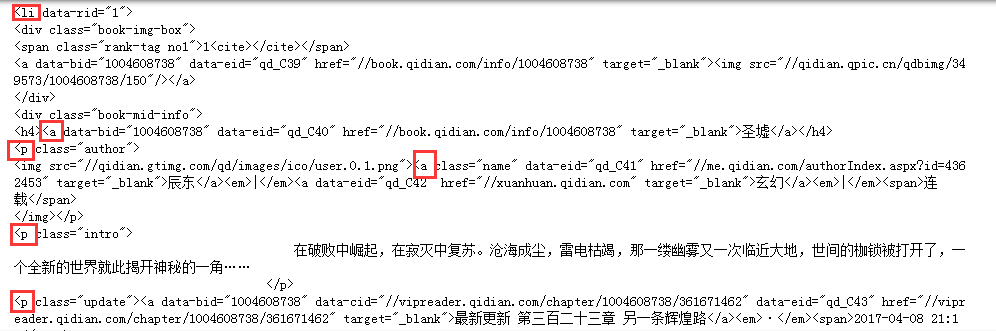
newsary.append({'title':news.select('a')[1].text,'name':news.select('a')[2].text,'style':news.select('a')[3].text,'describe':news.select('p')[1].text,'lastest':news.select('p')[2].text,'url':news.select('a')[0]['href']})
newsary.append({'title':news.select('a')[1].text,'name':news.select('a')[2].text,'style':news.select('a')[3].text,'describe':news.select('p')[1].text,'lastest':news.select('p')[2].text,'url':news.select('a')[0]['href']})
老师 还有定位软件推荐不?上面那个打不开 求推荐
老师 还有定位软件推荐不?上面那个打不开 求推荐
老师 还有定位软件推荐不?上面那个打不开 求推荐
老师 还有定位软件推荐不?上面那个打不开 求推荐
老师 还有定位软件推荐不?上面那个打不开 求推荐
老师 还有定位软件推荐不?上面那个打不开 求推荐
老师 还有定位软件推荐不?上面那个打不开 求推荐
推荐学习BeautifulSoup
https://chrome.google.com/webstore/detail/infolite/ipjbadabbpedegielkhgpiekdlmfpgal 丘老师这个打不开,请问有其他推荐吗,谢谢

ID王大伟 回复 bensentray
使用BeautifulSoup 用谷歌浏览器的开发者模式

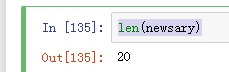
newsary是啥,我这里报错name 'newsary' is not defined,不知道怎么弄额
尽管不能全部看懂,但是照葫芦画瓢从另一个网页上抓了一个报告更新列表下来。谢谢王老师dalao~