今天我们用R语言来处理一下。首先来说一下我们会用到的知识:
(1)正则表达式
(2)中文分词
(3)词频统计
(4)文本可视化
(5)ggplot2绘图
如果你对这几地方有不懂得地方可以在文末根据 推荐阅读 点击查看相关文章。
一.数据处理
首先我们要讲QQ聊天记录导出成txt文件,至于怎么导,我相信大家都会,不会自行百度。导出来之后我们打开文件看看。
首先读入数据
root<-"C:/Users/henry wang/Documents/"
file<-paste(root,"18考研备战群.txt",sep="")
#读取数据
file.data<-scan(file,what = "",sep="\n",
encoding = "UTF-8")
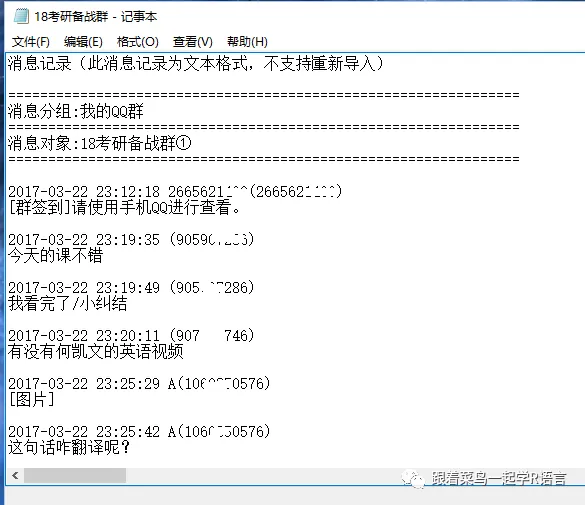
通过head(file.data)查看数据如下,可以看到前5行都是一些没有的信息,我们需要删掉。

file.data<-file.data[-1:-5]#删除文件开头的说明内容
现在我们要通过正则表达式提取聊天记录里面的时间,用户,聊天消息。
#正则表达式解析时间time,发布人user,留言信箱,message,存储在一个data数据框中
time <- c();#时间
user <- c();#用户
message <- c();#消息
data<-data.frame(user=c(),time=c(),message=c())
for(i in 1:length(file.data))
{
reglog <- regexpr('
[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]+:[0-9]+:[0-9]+',
file.data[i])
if(reglog[1]==1)
{
time[i] <- substr(file.data[i],1,19)
user[i] <- substr(file.data[i],21,nchar(file.data[i]))
}
else
{
message[i] <- file.data[i]
}
}
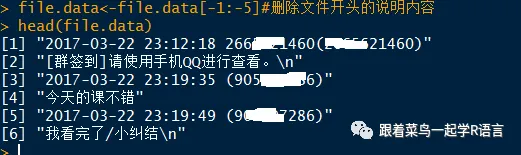
数据框进行合并。
#message第一行na,所以不读如第一行
data<- data.frame(
time=time,user=user,message=message[-1]
)
head(data)
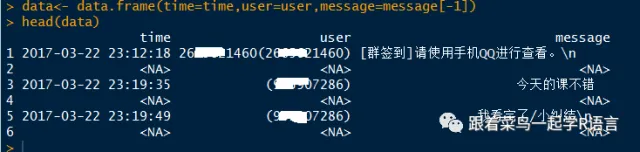
我们可以看到数据框中有na存在,所以接下来我们要删掉这些行。
for(i in 1:dim(data)[1])
if(is.na(data[i,1]))
{
if(is.na(data[i,2]))
{
if(is.na(data[i,3]))
{
data<- data[-i,]
}
}
}head(data)#查看删掉NA之后的数据

现在我们数据处理基本完成。
二. 分析讨论话题
library(rJava)
library(Rwordseg)
library(dplyr)
text<-as.character(data$message)
text<-enc2utf8(text) #转utf-8
text<-text[Encoding(text)!='unknown']#删除无法识别的字符
#下面这几个词在分词是会被分开
insertWords(c("何凯文","泪奔","卖萌","考研"),save=TRUE)
word.message<-segmentCN(text)#分词
#删除停用词
stop_words=readLines('停词.txt')
target_words <- unlist(word.message)
seg_word=target_words[
which(is.element(target_words,stop_words)==FALSE)
]
#分词结束,现在开始统计词频
p=as.data.frame(table(unlist(seg_word)))%>%
arrange(desc(Freq))
head(p)
library(wordcloud2)
wordcloud2(p)

为什么会有一个飘字。打开聊天记录我们会发现,有一个叫天天考研的管理员人用这个在刷屏。

那也许就有人会有疑问,那为什么没有过字,那是因为我们的停用词中有“过”,所以在删除停用词的时候就给删了。因此我们需要要把“飘”字删除,然后重新绘制。
seg_word=gsub(pattern="[飘]","",seg_word);
q=as.data.frame(table(unlist(seg_word)))%>%
arrange(desc(Freq))
wordcloud2(q)

看来图片和表情才是大家聊天的主要方式,怪不得表情包那么火,有人要做表情包可以拉我一块做(偷笑)。
三. 讨论时间点
现在,我们来一起讨论在这个群里大家一般在几点比较活跃。直接给出代码。
user.time<-data$time
user.time<-as.character(user.time)
user.time.h<-c()
for(i in 1:length(user.time))
{
user.time.h[i]<-substr(user.time[i],12,19)
}
#下面这句是提取时分秒
user.time.h<- as.POSIXct(user.time.h,format="%H:%M:%S")
hour <- format(user.time.h,"%H") #统计出小时发言
hour <- as.data.frame(table(hour))
library(ggplot2)
ggplot(data=hour,aes(x=hour,y=Freq,group=1))+
geom_bar(stat = 'identity')+
geom_line(color="red");#折线图和条形图叠加
在这里需要说明几点,如果上面substr(user.time[i],12,19)写成substr(user.time[i],12,13)在后面会出错的,因为当时间在10点到23点之间没错,但如果是0点到9点,它也会把后面的那个冒号读进去。
结果如下图:

看来大家一般在11点下午2点和晚上8点左右比较活跃。11点左右一般是快要下课了,2点左右上快要上课了,晚上8点我估计是刚刚做到图书馆准备复习吧。这些还是比较大学生的习惯。
三.分析谁是话痨
一般在任何QQ群或者讨论组里面都有几个特别活跃的人家,现在我们就来分析一下。
#统计发言频率
user.n<-as.data.frame(table(user))
user.n.20<-user.n[order(user.n[,2],decreasing=T),]
user.n.20<-user.n.20[1:20,]
ggplot(data=user.n.20,aes(x=user,y=Freq))+
geom_bar(stat='identity')+coord_flip()
#coord_flip()的作用就是讲条形图这些这样90度的旋转。
结果这这样的:

由此可知,测控技术与仪器-六花这个人可真是话痨啊。
注:由于隐私问题,所有QQ号部分都已打码。
推荐阅读☞☞☟☟☟☟
《R语言之正则表达式》
《ggplot2你需要知道的都在这》
《R语言如何画个性化词云图》
《R语言怎么给中文分词》


