更优体验:Python爬虫实战——免费图片 - Pixabay

Pixabay,一个挺不错的高清无码图片网站,可以免费下载。
https://pixabay.com/
一些介绍
超过 900000 高质量照片、 插图和矢量图形。可免费用于商业用途。没有所需的归属。
Pixabay是一家高质量图片分享网站。最初,该网站由Hans Braxmeier和Simon Steinberger在德国发展起来。2013年2月,网站拥有由影师和其社区的插画家提供的大约7万张免费的照片和矢量图形。该公司于2010年12月在德国乌尔姆成立。
2012年3月,Pixabay开始从一个私人图像搜集网站转变成一个互动的网上社区,该网站支持20种语言。同年5月,网站推出公共应用程序编程接口,从而使第三方用户和网站开发人员搜索其图像数据库。网站还与Flickr,YouTube和维基共享资源。
Pixabay用户无需注册就可以获得免费版权的高质量图像。根据知识共享契约CC0相关的肖像权,用户在该网站通过上传图片就默认放弃图片版权,从而使图片广泛流通。网站允许任何人使用,修改图片 - 即便是在商业应用 - 不要求许可并且未认可。
Pixabay为了确保高品质图片标准,用户上传的所有图片将由网站工作人员手动审批。大约27%的用户会说英语,20%的用户会说西班牙语,11%的用户会说葡萄牙语,7%的用户会说德语和5%的用户会说法语。其用户主要是博客、图形设计师、作家、记者和广告商。
今天的目标就是爬取小编精选的图片 小编精选 - 照片
一、分析
我们需要写3个函数
一个Download(url),用来下载图片
一个用来获取小编精选一共有的165页FullUrl()
最后用来调用main()
下面开始一个个写吧~
小编精选 - 照片
打开网页,F12,查看图片链接所在的标签
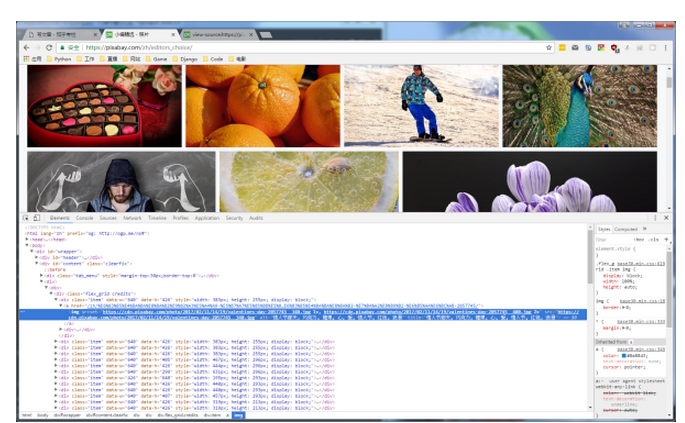
可以看到图片链接都在<img>标签下,但是我自己发现前几张和后几张的属性是不一样的,提取出<img>中“src”就可以了,使用的是xpath
import requests
from lxml import etree
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
url = 'https://pixabay.com/zh/editors_choice/'
r = requests.get(url,headers=header).text
s = etree.HTML(r)
print(s.xpath('//img/@src'))
结果是
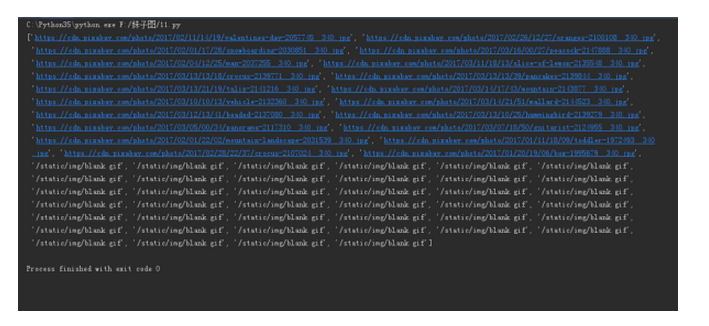
前面都是正确的图片链接,可是后面出现了'/static/img/blank.gif',这个是什么鬼,查看网页源代码,搜索

可以发现确实有这一段字符串,我自己在这一点上花了很多时间。感谢http://www.zhihu.com/people/li-hong-jie-17-58的帮助,Python爬虫动态页面抓取问题? - 爬虫(计算机网络) - 知乎
浏览器中的代码是JavaScript修改过的, 你直接用requests请求然后打印出来看就会发现
<div class="item" data-w="640" data-h="426">
<a href="/zh/%E8%9B%8B%E7%B3%95-%E4%B8%80%E5%9D%97%E8%9B%8B%E7%B3%95-%E9%A3%9F%E8%B0%B1-%E4%B8%80%E7%89%87-%E7%B3%96%E6%9E%9C-%E6%8F%92%E5%9B%BE-%E7%83%98%E7%83%A4-%E7%94%9C%E7%82%B9-%E9%A3%9F%E5%93%81-1971556/">
<img src="/static/img/blank.gif" data-lazy-srcset="https://cdn.pixabay.com/photo/2017/01/11/11/33/cake-1971556__340.jpg 1x, https://cdn.pixabay.com/photo/2017/01/11/11/33/cake-1971556__480.jpg 2x" data-lazy="https://cdn.pixabay.com/photo/2017/01/11/11/33/cake-1971556__340.jpg" alt="">
</a>
<div>
requests返回的数据中可以看到,“data-lazy”总含有我们需要的数据,修改代码
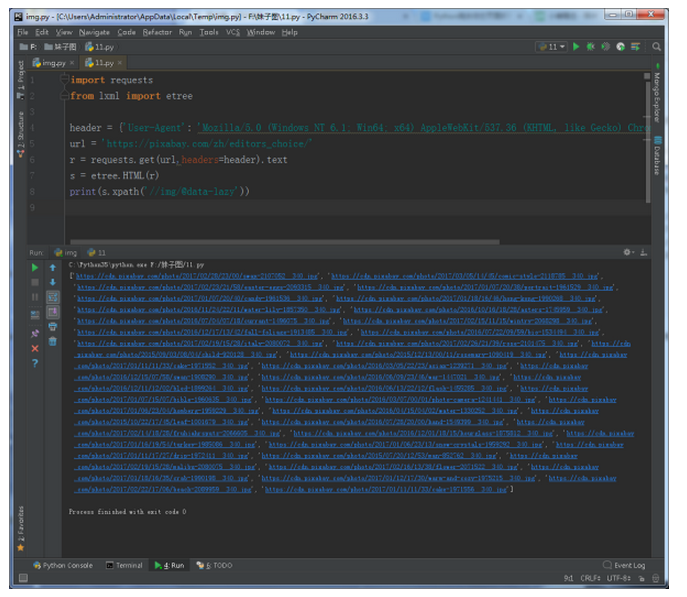
发现现在返回的数据是我们需要的,打开一张图片查看
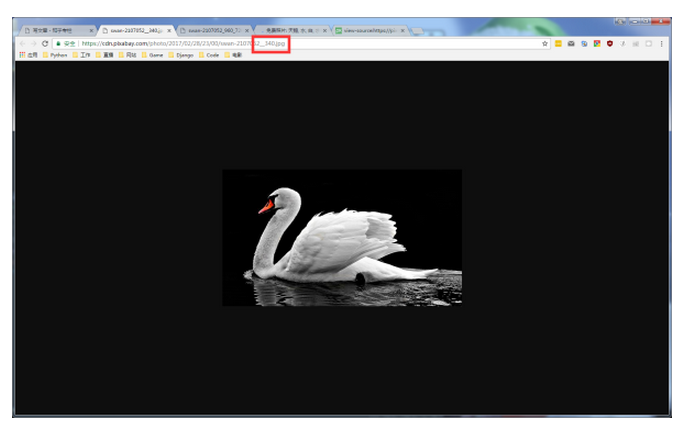
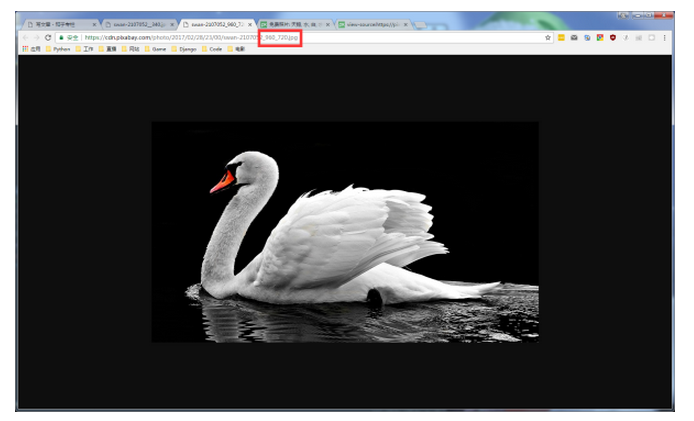
下面的图片要清晰很多,我们只需要把“__340”换成“_960_720”即可
小编精选一共有165页,我们需要获取下一页URL
https://pixabay.com/zh/editors_choice/?media_type=photo&pagi=2
https://pixabay.com/zh/editors_choice/?media_type=photo&pagi=3
。。。
规律很简单
full_link = []
for i in range(1,165):
#print(i)
full_link.append( 'https://pixabay.com/zh/editors_choice/?media_type=photo&pagi='+ str(i))
到现在,准备工作做好了,思路可能不是很清楚,请谅解~
二、代码
import requests
from lxml import etree
import time
import urllib
def Download(url):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
r = s.get(url, headers=header).text
s = etree.HTML(r)
r = s.xpath('//img/@data-lazy')
for i in r:
imglist = i.replace('__340', '_960_720')
name = imglist.split('/')[-1]#图片名称
urllib.request.urlretrieve(imglist,name)
time.sleep(1)
def FullUrl():
full_link = []
for i in range(2,165):
#print(i)
full_link.append( 'https://pixabay.com/zh/editors_choice/?media_type=photo&pagi='+ str(i))
#print(full)
return full_link
if __name__ == '__main__':
urls = FullUrl()
for url in urls:
Download(url)
爬取图片的工作就完成了,粗略的计算6600张,每一张下载需要5秒钟,一分钟60秒、一小时60分钟,天呐,需要9个小时才能爬取全部的图片。想一想还是算了吧,整站爬取还是要使用Scrapy+mongodb
>>> 165*40
6600
>>> from __future__ import division
>>> 6600*5/60/60
9.166666666666666
下载了700多张,108M,也算是留着看看吧。
一会上传到Github上
zhangslob/Pixabay
三、结语
昨天学习了崔庆才老师的爬虫,感觉真的学习到了好多,对Python爬虫提高很有帮助,还有,原来他就是静觅,刚开始学习爬虫就在看他的博客,没想到他现在又在出爬虫教程,打算跟着学习。
分享内容:
1. 分析知乎Ajax请求及爬取逻辑
2. 用Scrapy实现递归爬取
3. 爬取结果存储到MongoDB
废话不多说,自己看看就知道了。
http://cuiqingcai.com/
微课录播 | 03月17日 爬取知乎所有用户详细信息
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------最后的小广告-------------------------------------------------------
有朋友竟然叫我去作一期直播,讲一讲Python。
打算根据自己的经历分享一些经验,主要是关于Python入门的,想听听可以私信我。
时间是周二晚9点~
Hello World! Try to be a Pythoner!