上篇文章为大家介绍了一个高清无水印而且还免费的图片网站Unsplash,并且还写了个40行的小爬虫进行图片下载,方便快捷。
我们知道,python爬虫有一个神奇就是scrapy,抱着学习的态度,我尝试着将上次的代码转化成在scrapy下运行的代码,看看效果如何。以下是使用scrapy的过程:
首先是相关的一些安装,这里就不多说了,网上教程很多,大概就是提前装上pipywin32,lxml等几个包就可以,然后就可以直接pip install scrapy。
下完之后,在cmd命令行中创建scrapy工程:scrapy startproject unsplash
创建工程后,就会自动产生一个文件夹,如图:
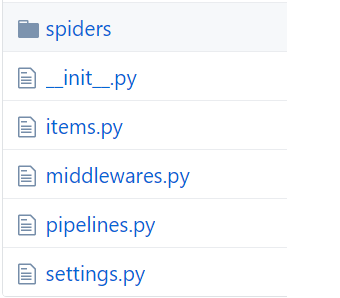
下面解释下各个部分,spiders文件夹用于存放爬虫程序,items用于存放一些存储对象,比如本例中的图片的url,middlewares是用来定义中间件,本例中不用用到,pipelines是用于把我们需要存储的item对象进行存储,也就是根据pic_url来下载图片存储在本地,settings是用于对scrapy工作的一些属性进行设置。
好,解释完毕不多BB,直接来看代码,首先是爬虫的代码,图片看不清楚的话最后附有全部代码地址:
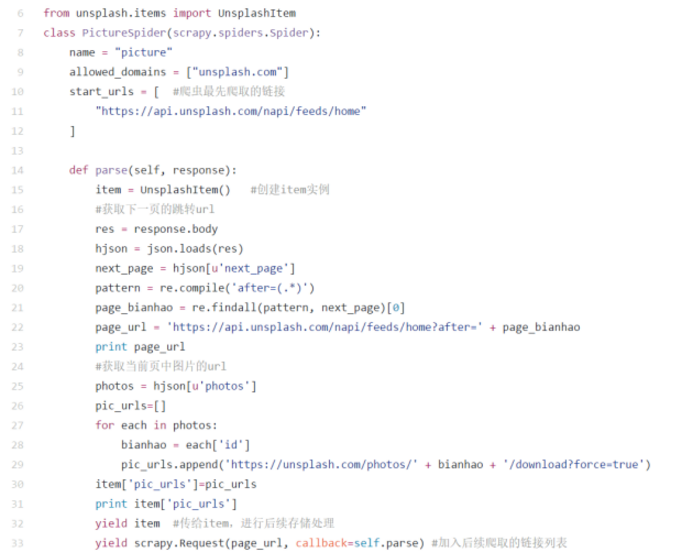
可以看到,爬虫的代码其实跟上一次的代码区别不大,只是按照scrapy的要求进行了部分格式上的修改,parse函数是默认的回调函数,不能改名,大概流程就是创建item实例,然后根据response返回的结果,进行数据提取,获得下一页的链接和图片的链接,图片的链接保存到item中回传,下一页的链接使用scrapy.Request进行递归访问,这样就能继续爬取后面的网页。所以,总的来说还是很简单哒。
接下来看看items.py,这个非常简单,就是把回传的item对象根据需要进行保存,这里pic_urls是一个存着一个页面所有图片url的list列表:
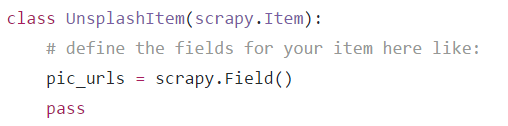
有了图片的url,我们再使用pipeline.py进行图片的下载储存,这里其实就是对每个item进行相应的处理,很简单可以看出,其实就是图片的下载,而pipeline的初始化只是创建一个文件夹而已:

到这里基本代码的部分就大功告成了,最后再编辑一下settings.py进行一些设置,有朋友纳闷,之前代码中的Headers怎么不见了,其实这个直接可以在settings中设置,还有就是启用pipeline。
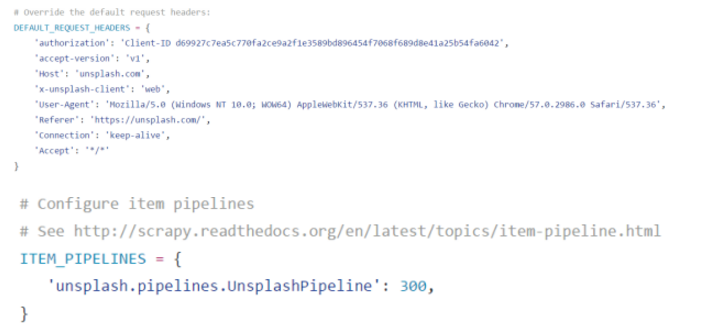

设置完成之后,我们的整个project算是全部完成了,其实也不是很麻烦嘛,只是使用上次的代码稍微一改就完成了,感觉新学scrapy的同学可以把这个当成一个练手的小项目,代码不多,但是对于了解scrapy还是很有帮助的。
最后运行,还是在cmd中,进入对应文件夹,输入 scrapy crawl picture -s LOG_LEVEL=ERROR 即可运行。看看运行效果:
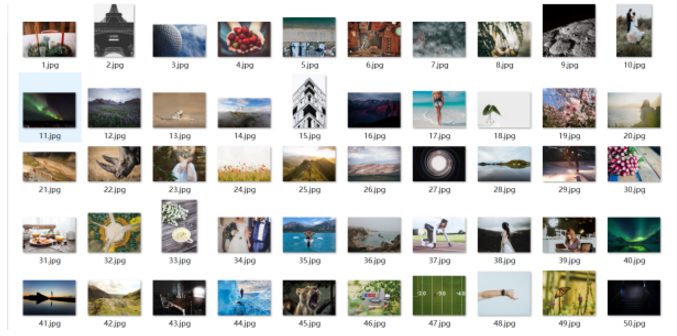
本次文章就到这里,只用于学习目的,欢迎交流。
爬了一两百张图片吧,当壁纸绝对够了,链接:http://pan.baidu.com/s/1nvM6tvF 密码:j78x
欢迎点赞或关注,今后会写更多相关文章。最后附上本次的全部代码地址:PP8818/Unsplash_Crawling,来Star呀~
