我的问题:最近在某单位的岗位分类表中看到“会计”属专业技术岗,而一字之差的“统计”属专辅助技术岗,工资待遇的差距可是几何级的,职业发展也是天壤之别。心中一万匹羊驼跑过之后,出现了一个问题:统计有什么用,数据分析的价值到底在哪里?(标题就是答案,下面是小白的R实践过程,大牛请自行跳过)
我的R实践:还是我们熟悉的《朝阳医院2016年销售数据》,课上我们做出了《2016年朝阳医院消费曲线》及月均消费次数、月均消费金额、客单价等三个KPI指标。现在想想,这个结果除满足院领导的显摆欲,顺道搭讪一下业务部门美女小梦外,并没有什么卵用。
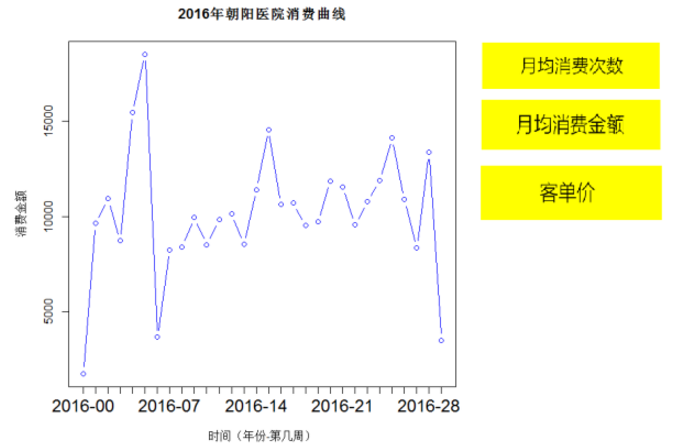
当我怀着然并卵的郁闷,不断的点击着Environment的各种Data和Values时,timeSplit中一个曾被无情忽略的数据引起了我了注意,是不是可以拿它做点什么呢?
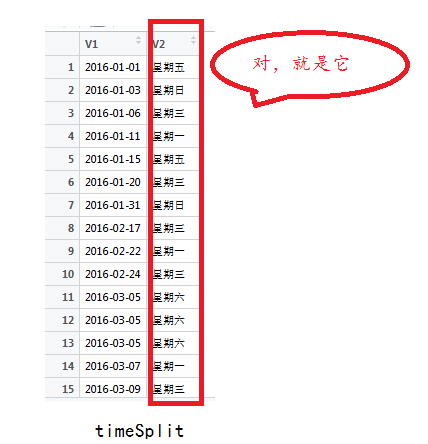
排序面对杂乱无序的数据,第一个想法是排序,照葫芦画瓢,使用order()函数对excelDate排序,decreasing = TURE,还是FALSE返回的结果都是诡异的:“星期二”、“星期六”、“星期日”、“星期三”、“星期四”、“星期五”、“星期一”(或正好反过来)。
关键字 使用中文关键字“R语言 数据排序”,无论是谷哥还是百度,得到的结果基本都是sort(),rank(),order()三个函数的内容。正当我无计可施的时候,想起英文版的R语言实战。阅读它虽然还是没有找到答案,但找到了"sort data"和"in R"两个关键字。(见笑了,奇葩英语学习之路。这也算是英文版的另类用法吧!)
谷哥“How to sort data in R",我找到了提示,原来强在的R也有它小白的一面:想它给你排序,你得用factor()函数先告诉它”谁在先,谁在后“。
weekdaymoney$weekday <- factor(weekdaymoney$weekday,levels=c("星期一","星期二","星期三","星期四","星期五","星期六","星期日"),ordered = T)
汇总还是照葫芦画瓢,但这次我学乖了。在help(tapply)得知它不能计数之后,马上翻译计数(即:count)谷哥”How to count data in R"

安装plyr包,使用count()函数,顺利得到交易量周变化情况。
library(plyr)
COUNT <- count(timeSplit,"timeSplit[,2]")
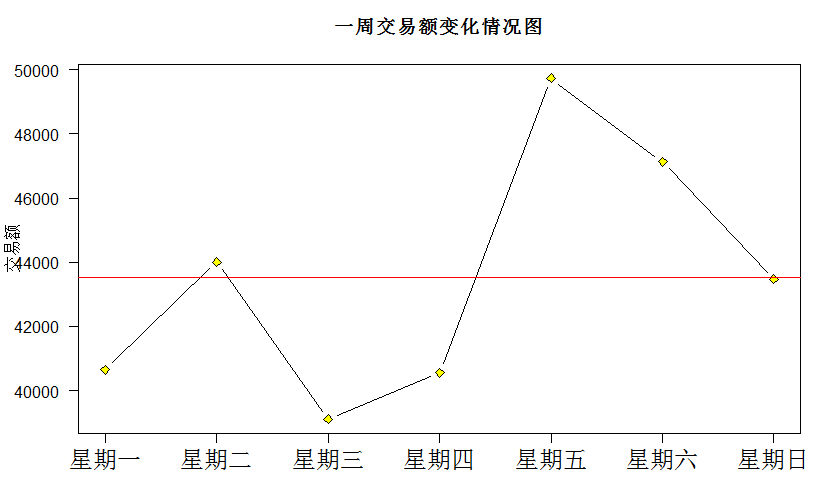
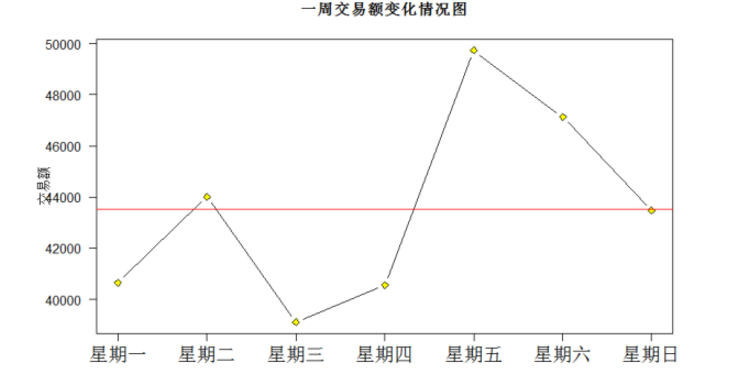
同时还计算了交易额和客单价的周变化情况,过程很顺利,代码如下:
weekdaymoney <-tapply(excelDate$actualmoney,excelDate$wd,sum)
weekdaymoney$mean <- weekdaymoney$actualmoney/weekdaymoney$count
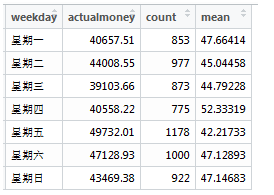
看图说话 看到上面的表格,估计百分之九十以上的人都在懵逼。
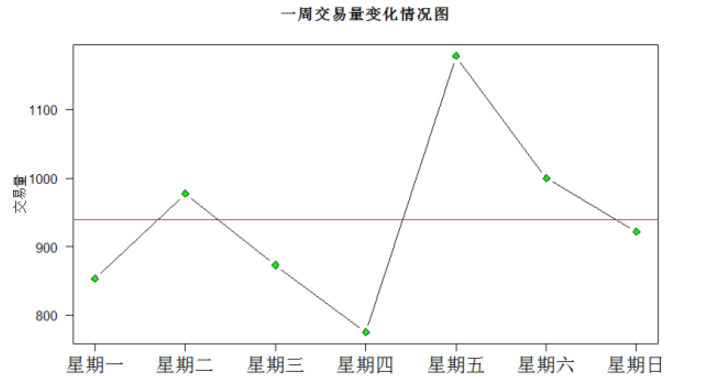
如果你是病人:星期五最好就不要去就诊了,等待你的只能是排队、排队、排队……和人头、人头、人头……;可以的话星期四去吧,等待你的是休息充分,心情轻松的医护人员。
如果你是收费处的排班人员:星期五、星期六两天最好按排多点同事上班。不然,排队的群众有意见,上班的同事也会有意见。
如果你是社保局的督查人员:星期四上班的医院怎么会事,都喜欢开大处方嘛?查
我的答案 首先声明:上述解说纯属玩笑,但说明了一个意思:统计有什么用?关键看是否使用统计结果指导行为。如果把统计结果与行为完全隔裂开来,那么,统计真得没有卵用。反之,统计就炸天了,它作用超乎你想像。同样的数据在不同的人面前其价值是不一样的。对于病人来说,可以指导更好地按排就诊时间;对于一线排班人员,可以指导地安排人员作息;对于监查人员,可以有得放失高效开展督查……虽然价值各不相关,但它们产生价值的途径却是一至的,就是根据数据分析指导自己的行为。
我的代码:
##第一大部分数据处理
#载入Excel数据
library(openxlsx)
readFilePath <- "C:/朝阳医院2016年销售数据.xlsx"
excelDate <- read.xlsx(readFilePath,1)
#处理缺失数据
excelDate <- na.omit(excelDate)
#数据框例重命名
names(excelDate) <- c("time","cardno","drugld","drugName","saleNumber","virtualmoney","actualmoney")
#切割数据
library(stringr)
timeSplit <- str_split_fixed(excelDate$time," ",n=2)
WD <- data.frame(wd=timeSplit[,2])
excelDate <- cbind(excelDate,WD)
##第二部分结果展示
library(plyr)
COUNT <- count(timeSplit,"timeSplit[,2]")
names(COUNT) <- c("weekday","count")
weekdaymoney <-tapply(excelDate$actualmoney,excelDate$wd,sum)
weekdaymoney <- as.data.frame.table(weekdaymoney)
names(weekdaymoney) <- c("weekday","actualmoney")
weekdaymoney <- merge(weekdaymoney,COUNT,by="weekday")
weekdaymoney$weekday <- factor(weekdaymoney$weekday,levels=c("星期一","星期二","星期三","星期四","星期五","星期六","星期日"),ordered = T)
weekdaymoney <- weekdaymoney[order(weekdaymoney$weekday),]
weekdaymoney$mean <- weekdaymoney$actualmoney/weekdaymoney$count
##第三大部分结果展示
attach(weekdaymoney)
layout(matrix(c(2,3,1,1),2,2,byrow=T))
weekdaymoney$Number <- c(1:7)
##生成一周客单价变化情况图
plot(weekdaymoney$Number,weekdaymoney$mean,xlab="",ylab="客单价",main="一周客单价变化情况图",las=2,type="b",xaxt="n",bg="blue")
axis(1,at=weekdaymoney$Number,labels=weekdaymoney$weekday,cex.axis=1.5)
abline(h=mean(weekdaymoney$mean),col="red")
#请左单击鼠标为红线加标备
text(locator(1),"平均值")
##生成一周交易量变化情况图
plot(weekdaymoney$Number,weekdaymoney$count,xlab="",ylab="交易量",main="一周交易量变化情况图",las=2,type="b",xaxt="n",lty=1,pch=23,bg="green")
axis(1,at=weekdaymoney$Number,labels =weekdaymoney$weekday,cex.axis=1.5)
abline(h=mean(weekdaymoney$count),col="red")
#请左单击鼠标为红线加标备
text(locator(1),"平均值")
##生成一周交易额变化情况图 plot(weekdaymoney$Number,weekdaymoney$actualmoney,xlab="",ylab="交易额",main="一周交易额变化情况图",las=2,type="b",xaxt="n",lty=1,pch=23,bg="yellow")
axis(1,at=weekdaymoney$Number,labels =weekdaymoney$weekday,cex.axis=1.5)
abline(h=mean(weekdaymoney$actualmoney),col="red")
#请左单击鼠标为红线加标备
text(locator(1),"平均值")
detach(weekdaymoney)
感谢:
谢谢您花时间读到这里,尤其是作出评论的亲。数据分析学习之路,有您真好!
