一、统计学基础知识(虽然枯燥,但是硬着头皮也要看)

![2.png]()
二、基于朴素贝叶斯定理的条件概率

三、朴素贝叶斯分类的工作流程
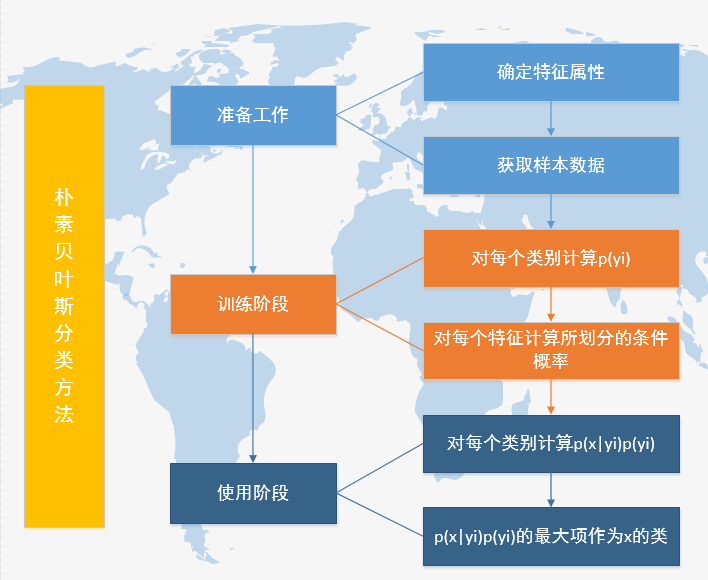
四、朴素贝叶斯分类中需要注意的问题
⑴假设条件:每一个属性值在给定类上面的影响是独立于其他属性的,也就是说属性与属性之间是相互独立的,称之为“类条件独立性”。
⑵如果属性是分类变量,那么“边际似然概率”是可以用计数的形式来加以计算。具体会在后面的小案例中呈现。
⑶如果属性是连续变量,那么则假设其实服从于均值为μ,方差为σ的高斯分布:
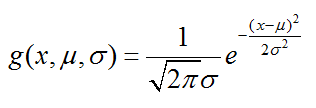
则具体的“边际似然概率”可以通过上面的概率密度公式求得。具体会在后面的小案例中呈现。
⑷拉普拉斯估计:考虑到某一属性的某一特征的样本量为0,这样会给分类带来很大的误差,可以在每个特征的数量加1,这样有效的避免概率值为0的情况。
五、朴素贝叶斯分类适用解决的问题
在考虑一个结果的概率时候,要考虑众多的属性,贝叶斯算法利用所有可能的数据来进行修正预测,如果大量的特征产生的影响较小,放在一起,组合的影响较大,适合于朴素贝叶斯分类。
六、朴素贝叶斯分类的两个小案例
⑴通过对词语“伟哥”,“金钱”,“杂货”的监测来对垃圾邮件进行过滤,这三个词汇(记为A1,A2,A3)的似然表来训练朴素贝叶斯算法,对100封电子邮件分析后的似然表如下:

①下面我![5.png]() 们利用贝叶斯定理,定义这样一个问题的概率—一封电子邮件中含有“伟哥”,不含“金钱”和“杂货”,那么这封邮件是垃圾邮件的概率:
们利用贝叶斯定理,定义这样一个问题的概率—一封电子邮件中含有“伟哥”,不含“金钱”和“杂货”,那么这封邮件是垃圾邮件的概率:

②现在考虑这么一个问题:一封电子邮件中含有“伟哥”和“杂货”,不含“金钱”,那么这封邮件是垃圾邮件的概率:
这时我们发现在20封垃圾邮件中出现“杂货”的次数为0,这就影响了对概率的计算,现在要利用拉普拉斯估计:对每个似然函数,分子加1,分母加上分子中1的总个数
⑵以作者本人班级上学期三门专业课成绩为例,进行属性是连续变量的朴素贝叶斯分类。然后用作者本人的成绩来进行预测:
![7.png]()
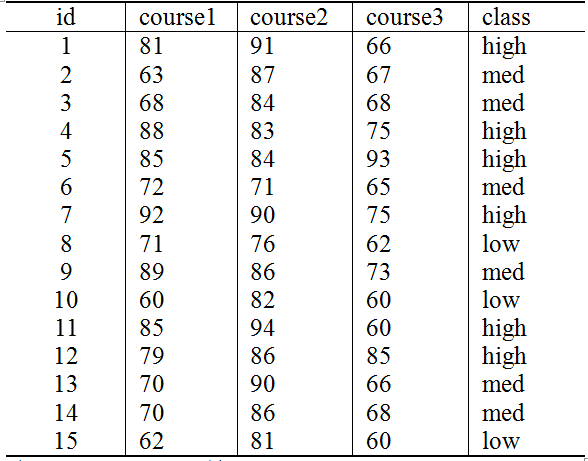
由此计算作者本人三门课程的成绩(A1:course1=86, A2: course2=75,A3:course3=61),来查看对他的分类
假设这三门成绩都服从正态分布,通过样本计算均值和方差,得到正态分布的密度函数,从而可以计算出某一点的密度函数值。
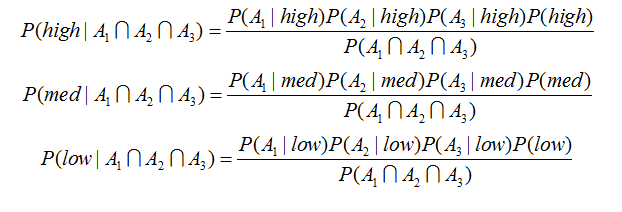
由于以上三式的分母值一样,为此,我们只是来比较分子的值,R代码如下:
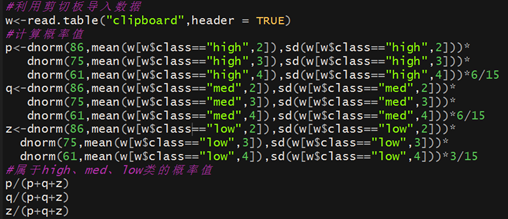
因此本人有55.25%的可能性拿一等奖学金,36.16%的可能性拿二等奖学金,8.59%可能性拿三等奖学金。
谢谢大家!



