万事开头难,知乎专栏申请下来一段时间了,但一直懒癌拖着没写,拖了又拖,终于在一个阴雨绵绵的周六的晚上提笔开始了第一篇爬虫文章。
首先爬虫是啥,爬虫无非是用程序模拟人在浏览器上的行为,抓取网络信息用于分析,用爬虫的最大好处是能够批量、自动化地获取数据和处理信息。例如我们可以通过抓取淘宝、天猫、京东等电商网站的销量及评论数据,对各种商品销量及用户消费场景进行分析;在大众点评、美团等消费类网站抓取店面类信息获取用户的消费习惯及评价;在拉钩、智联招聘等人才招聘网站抓取各大城市的岗位需求和薪资水平….

当然你在浏览器上无法看到的信息爬虫一般也是无法抓取的。所以不要问爬虫能不能破解别人的登录密码,能不能获取电商网站的后台数据,爬虫不是黑客,希望理解。
这篇文章主要介绍使用Python爬取豆瓣上热门电影的信息,包括电影名称、海报、评分等信息。在开始介绍本项目前,先简单介绍下网上的信息是如何被“爬”下来的。
我们看到的网页都是用HTML+CSS+JS等语言写出,而页面中加载文字、图片、视频等元素也是通过嵌入到超文本标记语言中展现。我们可以在打开一个网页后通过键盘上F12键或单击鼠标右键选择“查看源文件”查看该网页的源码,我们想要的抓取的文字、图片、视频等信息也都嵌入在该超文本标记语言中。见图:
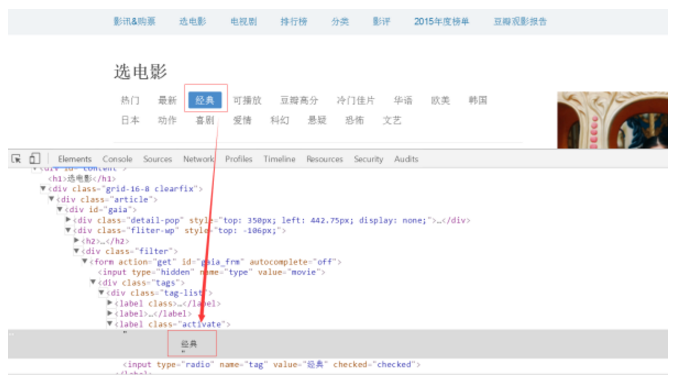
接下来,我们开始正式介绍本项目,Python爬取豆瓣热门电影:
1、 首先准备项目开发环境
安装lxml、Scrapy、urllib、json等关键库文件
pip install lxml
pip install Scrapy
pip install urllib
pip install json
2、 构建整体思路
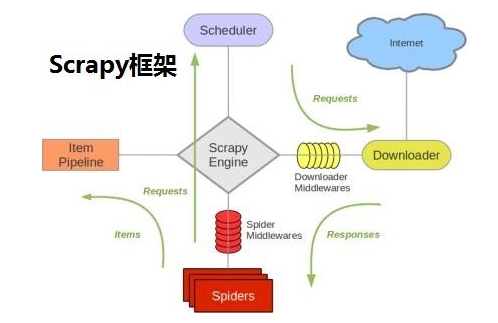
本次爬虫使用scrapy框架,scrapy中定义了数据的请求、返回、调度、保存、持久化等行为,通过调用scrapy大大简化了人为编程量。
执行:scrapy startproject tutorial,安装好scrapy后的文件系统是这样:
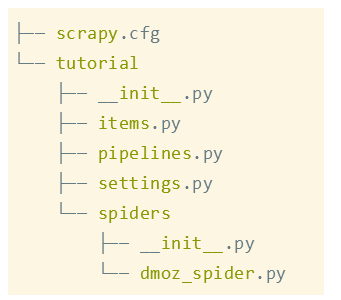
我们只需重写dmoz_spider.py文件即可。
3、 分析网页
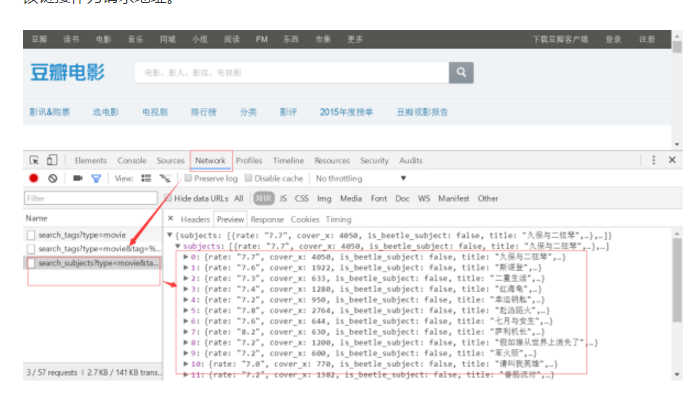
开始动手时一直抓不到豆瓣上电影的信息,掉在在坑里冥思苦想 + 各种搜索学习后发现豆瓣上有关电影的信息都是采用ajax方式加载到HTML中,于是在Network下找到加载ajax的链接,将该链接作为请求地址。
4、动手编程
第一步:先定义请求网页原址:
name = 'douban'
allowed_domains = ["douban.com"]
start_list = []
for i in range(1,14):
url = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=' + str(i*20)
start_list.append(url)
start_urls = start_list # 定义start_urls为一个存储链接的列表
第二步:重写请求头文件:
def start_requests(self):
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0'
headers = {'User-Agent': user_agent}
for url in self.start_urls:
yield scrapy.Request(url=url, headers=headers, method='GET', callback=self.parse)
第三步:在获取的网页源码中提取信息:
def parse(self, response):
hxs = response.body.decode('utf-8')
hjson = json.loads(hxs) # 字典
for lis in hjson['subjects']:
item = Tutorial2Item() # 实例化类
item["info"] = lis['url']
item["pic"] = lis['cover']
item["score"] = lis['rate']
item["title"] = lis['title']
filename = item["title"] + '_' + item["score"] + '分' + '.jpg'
urllib.request.urlretrieve(item["pic"], filename)
5、运行查看
我们在cmd下运行该文件:

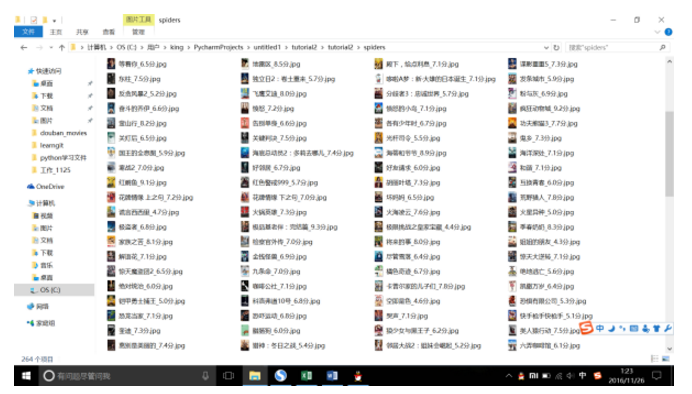
然后可在目标文件夹下看到同步下载的热门电影信息:多次调试后bingo
——————————分割线——————————
说了那么多,我们为啥要从网上爬数据。回答这个问题首先要回答“大数据”时代,数据从何而来?总结来看,数据主要来自以下几个方面:1、企业自己产生的数据:大型互联网公司拥有海量用户数据当然具有天然优势,有数据意识的企业也正逐步积累自己的数据;2、购买数据:可在数据堂、贵阳大数据交易所等平台上购买各类、各行业数据,当然价格不菲你懂的;3、政府/机构公开数据:公开数据实在是有限啊;4、爬取网络数据:想获取海量、丰富、有效的数据,自己动手丰衣足食。——人生苦短,我用Python
本次爬取豆瓣信息源码地址:GitHub-douban_movies

