在我看来,正则表达式的主要用途有两种:①查找特定的信息②查找并编辑特定的信息,也就是我们经常用的替换。。比如我们要在Word,记事本等里面使用快捷键Ctrl+F,进行查找一个特定的字符,或者替换一个字符,这就使用了正则表达式。
正则表达式的功能非常强大,尤其是在文本数据进行处理中显得更加突出。R中的grep、grepl、sub、gsub、regexpr、gregexpr等函数都使用正则表达式的规则进行匹配。这几个函数原型如下:
grep(pattern, x, ignore.case = FALSE, perl = FALSE, value = FALSE,
fixed = FALSE, useBytes = FALSE, invert = FALSE)
grepl(pattern, x, ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE)
sub(pattern, replacement, x, ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE)
gsub(pattern, replacement, x, ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE)
regexpr(pattern, text, ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE)
gregexpr(pattern, text, ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE)
regexec(pattern, text, ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE)
这里是对参数进行一个解释说明。
参数说明
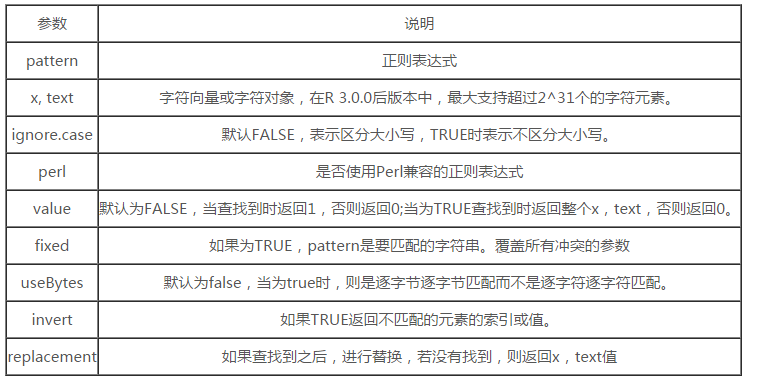
接下来我们对这几个函数谈谈他们的不同点。
函数作用
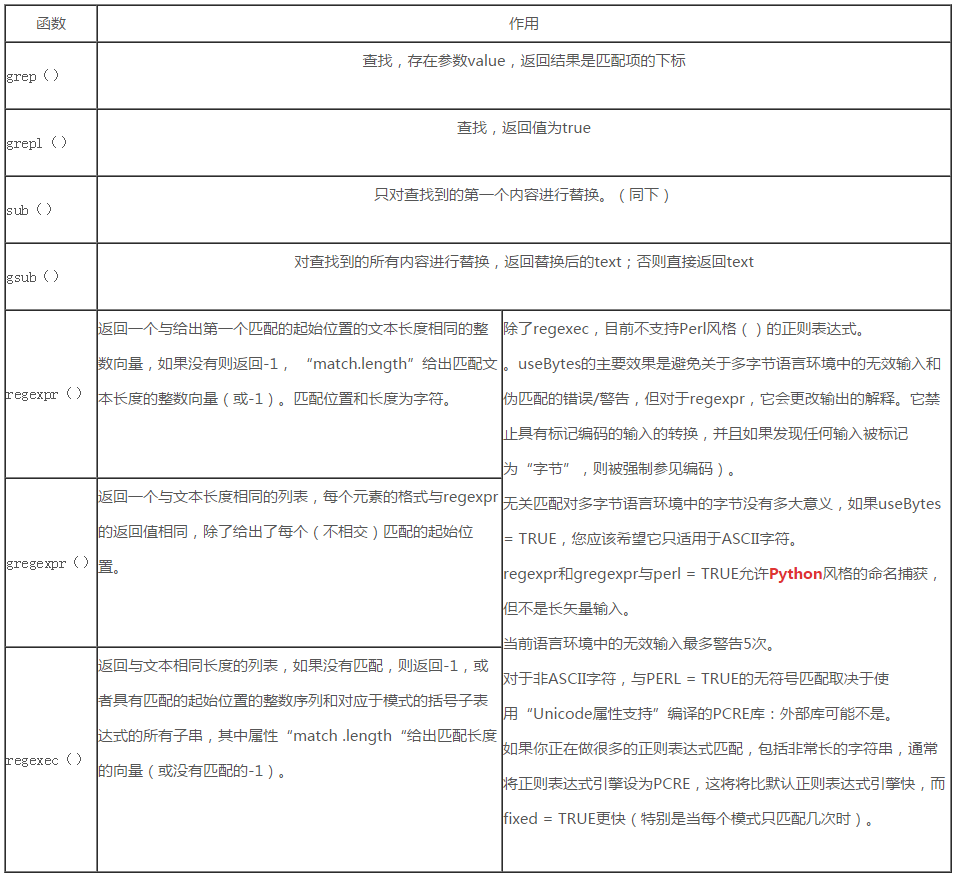
下面是我对正则表达式转义字符的一些总结,但R语言里面grep、grepl、sub、gsub、regexpr、gregexpr这几个函数并不支持使用 “\” 进行转义。
正则表达式转义字符
空白元字符[\b]回退(并删除)一个字符(backspace)
\f换页符
\n换行符
\r回车符
\t制表符(tab)
\v垂直制表符
注:\r\n是windows所用的文本行结束符,Unix和Linux只是用一个换行符来结束一个文本行
匹配数字与非数字\d任何一个数字字符,等价于[0-9]
\D任何一个非数字字符,等价于^[0-9]
匹配字母\非字母与数字\w任何一个字母数字字符(大小写均可以)或下划线字符(等价于[a-zA-Z0-9])
\W任何一个非字母数字或下划线字符(等价于[^a-zA-Z0-9])
匹配空白字符\s任何一个空白字符(等价于[\f\n\r\t\v])
\S任何一个非空白字符(等价于[^\f\n\r\t\v])
POSIX字符类[:alnum:]任何一个字母或数字(等价于[a-ZA-Z0-9])
[:alpha:]任何一个字母(等价于[a-ZA-Z])
[:blank:]空格或制表符(等价于[\t ]) 注:t后面有一个空格
[:cntrl:]ASCII控制字符(ASCII 0到31,再加上ASCII 127)
[:digit:]任何一个数字(等价于[0-9])
[:graph:]和[:print:]一样,但不包括空格
[:lower:]任何一个小写字母(等价于[a-z])
[:print:]任何一个可打印字符
[:punct:]既不属于[:alnum:],也不属于[:cntrl:]的任何一个字符
[:space:]任何一个空格字符,包括空格(等价于[f\n\r\t\v ] 注:v后面有一个空格
[:upper:]任何一个大写字母(等价于[A-Z])
[:xdigit:]任何一个十六进制数字(等价于[a-fA-F0-9])
其他.可以匹配任何单个的字符字母数字甚至.字符本身。同一个正则表达式允许使用多个.字符。但不能匹配换行
\\转义字符,如果要匹配就要写成“\\(\\)”
|表示可选项,即|前后的表达式任选一个
^取非匹配
$放在句尾,表示一行字符串的结束
()提取匹配的字符串,(\\s*)表示连续空格的字符串
[]选择方括号中的任意一个(如[0-2]和[012]完全等价,[Rr]负责匹配字母R和r)
{}前面的字符或表达式的重复次数。如{5,12}表示重复的次数不能小于5,不能多于12,否则都不匹配
*匹配零个或任意多个字符或字符集合,也可以没有匹配
+匹配一个或多个字符,至少匹配一次
?匹配零个或一个字符
现在来举几个例子。
首先使用[]中括号的功能,来查找一下看有没有do组合的单词。
text<-c("Don't","aim","for","success","if","you","want","it","just","do","what","you","love",
"and","believe","in","and","it","will","come","naturally")
#查找含有DO组合的单词
grep("[Dd]o",text)#不区分大小写
grep("[D]o",text)#D要大写
grep("[d]o",text)#D小写
运行结果如下:
> text<-c("Don't","aim","for","success","if","you","want","it","just","do","what","you","love",
+ "and","believe","in","and","it","will","come","naturally")
>
> #查找含有DO组合的单词
> grep("[Dd]o",text)#不区分大小写
[1] 1 10
> grep("[D]o",text)#D要大写
[1] 1
> grep("[d]o",text)#D小写
[1] 10
邮箱匹配:
#邮箱匹配:
text2<-c("704232753@qq.com is my email address.")
grepl("[0-9.*]+@[a-z.*].[a-z.*]",text2)
结果如下
> text2<-c("704232753@qq.com is my email address.")
> grepl("[0-9.*]+@[a-z.*].[a-z.*]",text2)
[1] TRUE
可以已经查找邮箱的。

