在文本或非结构数据处理中往往需要正则表达式的强大功能,需要字符串的处理,下文就讲讲这几天梳理的stringr包中的函数。该包仍然由伟大的Hadley做贡献。
word(),从句子中提取词组(适用于英语环境下的使用)
word(string, start = 1L, end = start, sep = fixed(" "))
string:需要提取的字符串对象
start:整数向量,指定从第几个单词开始提取
end:整数向量,指定取到第几个单词
sep:指定单词之间的分隔符,默认为空格
string <- 'I like using R'
word(string, 1, -1) #取出所有的句子
word(string, 1) #提取第一个单词
word(string, -1) #提取最后一个单词
word(string, 1, 1:4) #提取最后一个单词

str_wrap(),将段落划分为华丽的格式,可设置每行的宽度等。
str_wrap(string, width = 80, indent = 0, exdent = 0)
string:需要被划分的字符串
width:设定每行的宽度
indent:设定每个段落第一行的缩进格式,默认没有缩进
exdent:设定每个段落第一行之后所有行的缩进格式,默认没有缩进
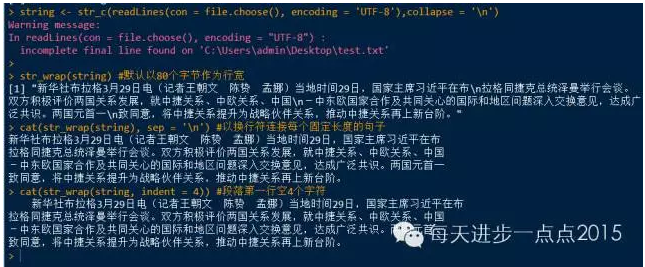
string <- str_c(readLines(con = file.choose(), encoding = 'UTF-8'),collapse = '\n')
str_wrap(string) #默认以80个字节作为行宽
cat(str_wrap(string), sep = '\n') #以换行符连接每个固定长度的句子
cat(str_wrap(string, indent = 4)) #段落第一行空4个字符
str_trim(),剔除字符串多余的首末空格
str_trim(string, side = c("both", "left", "right"))
string:需要处理的字符串
side:指定剔除空格的位置,both表示剔除首尾两端空格,left表示剔除字符串首部空格,right表示剔除字符串末尾空格
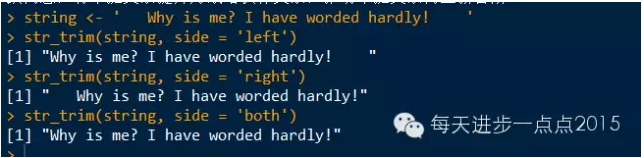
string <- ' Why is me? I have worded hardly! '
str_trim(string, side = 'left')
str_trim(string, side = 'right')
str_trim(string, side = 'both')
str_to_upper(),str_to_lower(),str_to_title(),字符串转换
str_to_upper(string, locale = "")
将字符串统统转换为大写
str_to_lower(string, locale = "")
将字符串统统转换为小写
str_to_title(string, locale = "")
将字符串换为标题格式
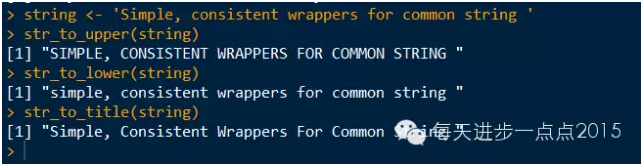
string <- 'Simple, consistent wrappers for common string '
str_to_upper(string)
str_to_lower(string)
str_to_title(string)
str_subset(),根据正则表达式匹配字符串中的值
str_subset(string, pattern)
string,需要处理的字符向量
pattern,需要匹配的字符模式,默认模式可以是正则表达式
该函数与word()函数的区别在于前者提取字符串的子串,后者提取的是单词,而且str_sub也可以其替换的作用。
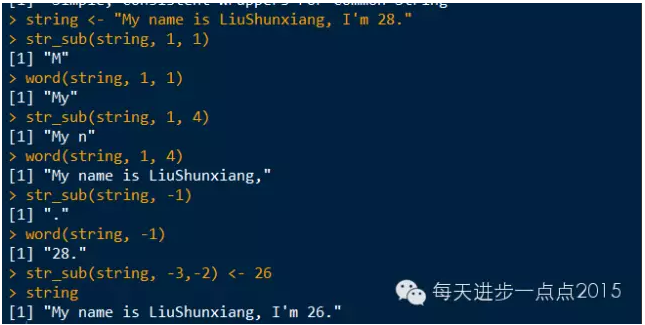
string <- "My name is LiuShunxiang, I'm 28."
str_sub(string, 1, 1)
word(string, 1, 1)
str_sub(string, 1, 4)
word(string, 1, 4)
str_sub(string, -1)
word(string, -1)
str_sub(string, -3,-2) <- 26
string
str_split(),字符串分割函数
str_split(string, pattern, n = Inf)
str_split_fixed(string, pattern, n)
string:被分割的字符串向量
pattern:分割符,可以是正则表达式也可以是固定的字符
n:指定返回分割的个数,需要注意的是,其使用转移法分割字符串
str_split与str_split_fixed的区别在于前者返回列表格式,后者返回矩阵格式
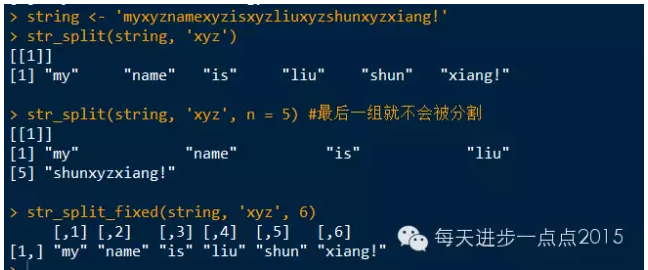
string <- 'myxyznamexyzisxyzliuxyzshunxyzxiang!'
str_split(string, 'xyz')
str_split(string, 'xyz', n = 5) #最后一组就不会被分割
str_split_fixed(string, 'xyz', 6)
str_order(),对字符向量排序
str_order(x, decreasing = FALSE, na_last = TRUE, locale = "", ...)
str_sort(x, decreasing = FALSE, na_last = TRUE, locale = "", ...)
x:需要排序的字符向量
decreasing:排序方式,默认为升序
na_last:是否将缺失值置于末尾,默认为TRUE
str_order和str_sort的区别在于前者返回排序后的索引(下标),后者返回排序后的实际值
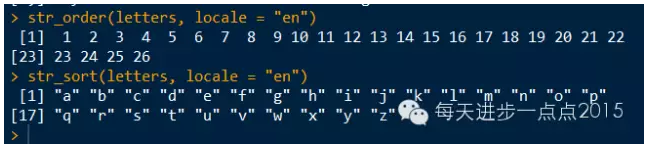
str_order(letters, locale = "en")
str_sort(letters, locale = "en")
str_replace(),字符串替换函数
str_replace(string, pattern, replacement)
str_replace_all(string, pattern, replacement)
str_replace_na(string, replacement = "NA")
string:需要处理的字符向量
pattern:指定匹配模式,
replacement:指定新的字符串用于替换匹配的模式
str_replace与str_replace_all的区别在于前者只替换一次匹配的对象,而后者可以替换所有匹配的对象
string <-'1989.07.17'
str_replace(string, '\\.', '-')
str_replace_all(string, '\\.', '-')

str_pad(),字符填充函数
str_pad(string, width, side = c("left", "right", "both"), pad = " ")
string:需要被填充的字符串
width:指定被填充后的字符长度
side:指定填充的方向,默认向左填充
pad:指定填充的字符,默认用空格填充
string <- 'LiuShunxiang'
str_pad(string,10) #指定的长度少于string长度时,将只返回原string
str_pad(string,20)
str_pad(string,20,side = 'both',pad = '*')

str_match(),str_match_all(),提取匹配的字符串
str_match(string, pattern)
str_match_all(string, pattern)
string:需要处理的字符串
pattern:指定匹配的模式,一般指定正则表达式
str_match()和str_match_all()区别在于前者只提取一次满足条件的匹配对象,而后者可以提取所有匹配对象
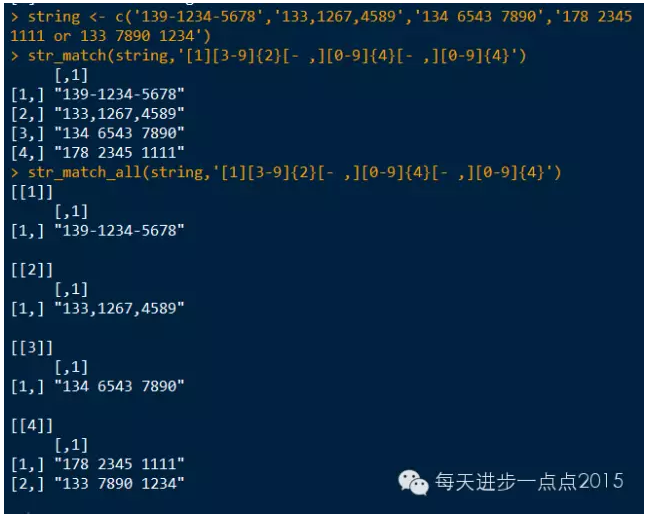
string <- c('139-1234-5678','133,1267,4589','134 6543 7890','178 2345 1111 or 133 7890 1234')
str_match(string,'[1][3-9]{2}[- ,][0-9]{4}[- ,][0-9]{4}')
str_match_all(string,'[1][3-9]{2}[- ,][0-9]{4}[- ,][0-9]{4}')
str_extract(),str_extract_all,提取匹配的字符串,功能与str_match(),str_match_all()函数类似
str_extract(string, pattern)
str_extract_all(string, pattern, simplify = FALSE)
string:需要处理的字符串
pattern:指定匹配的模式,一般指定正则表达式
simplify:默认返回值为列表,如果指定为TRUE,则返回矩阵格式,这样有助于将结果写入二维表中
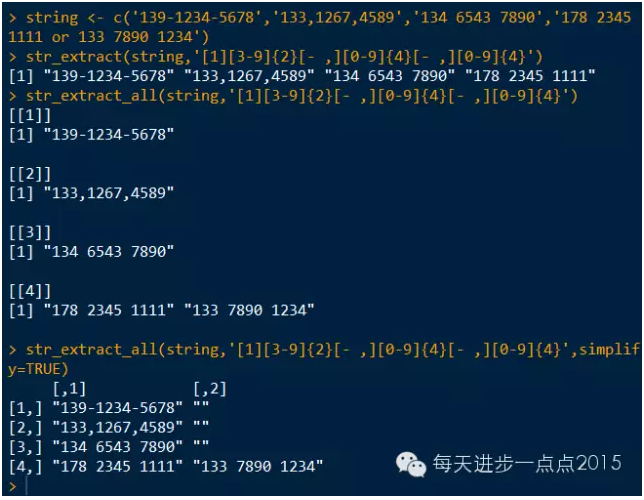
string <- c('139-1234-5678','133,1267,4589','134 6543 7890','178 2345 1111 or 133 7890 1234')
str_extract(string,'[1][3-9]{2}[- ,][0-9]{4}[- ,][0-9]{4}')
str_extract_all(string,'[1][3-9]{2}[- ,][0-9]{4}[- ,][0-9]{4}')
str_extract_all(string,'[1][3-9]{2}[- ,][0-9]{4}[- ,][0-9]{4}',simplify=TRUE)
str_locate(),str_locate_all(),字符定位函数,返回匹配对象的首末位置
str_locate(string, pattern)
str_locate_all(string, pattern)
string:需要处理的字符串
pattern:需要匹配的对象,一般为正则表达式
str_locate()和str_locate_all()的区别在于前者只匹配首次,而后者可以匹配所有可能的值
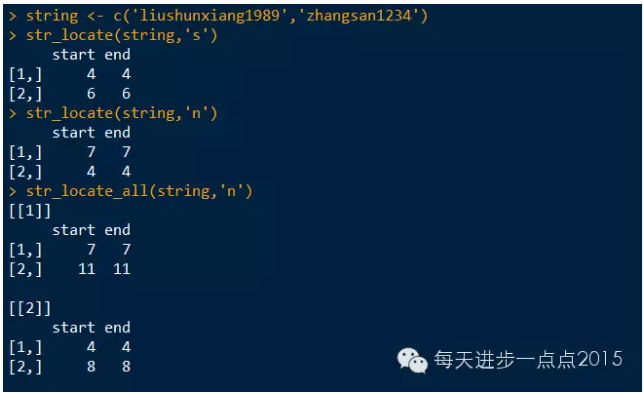
string <- c('liushunxiang1989','zhangsan1234')
str_locate(string,'s')
str_locate(string,'n')
str_locate_all(string,'n')
一般将定位函数与str_sub函数搭配使用。
str_length(),字符长度函数,该函数类似于nchar()函数,但前者将NA返回为NA,而nchar则返回2
str_length(string)
string:需要计算长度的字符串对象
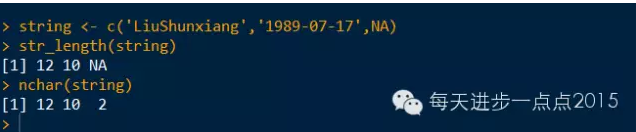
string <- c('LiuShunxiang','1989-07-17',NA)
str_length(string)
nchar(string)
str_c(),将多个字符串连接为单个字符串
str_c(..., sep = "", collapse = NULL)
...:一个或多个字符向量
sep:字符串之间的连接符,功能类似于paste()函数
collapse:如果是向量之间的连接,collapse的作用与sep一样,只不过此时sep无效
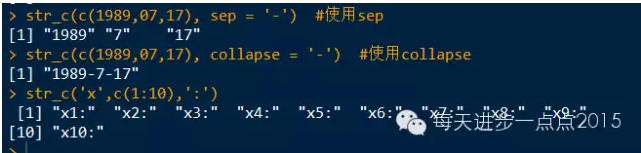
str_c(c(1989,07,17), sep = '-') #使用sep
str_c(c(1989,07,17), collapse = '-') #使用collapse
str_c('x',c(1:10),':')
str_dup(),重复字符串
str_dup(string, times)
string:需要重复处理的字符串
times:指定重复的次数
fruit <- c("apple", "pear", "banana")
str_dup(fruit, 2)
str_dup(fruit, 1:3)
str_c("ba", str_dup("na", 0:5))

str_detect(),检测函数,用于检测字符串中是否存在某种匹配模式
str_detect(string, pattern)
string:检测的字符串对象
pattern:检测模式,可以是正则表达式
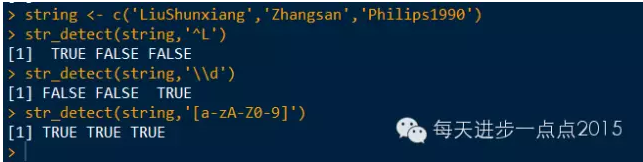
string <- c('LiuShunxiang','Zhangsan','Philips1990')
str_detect(string,'^L')
str_detect(string,'\\d')
str_detect(string,'[a-zA-Z0-9]')
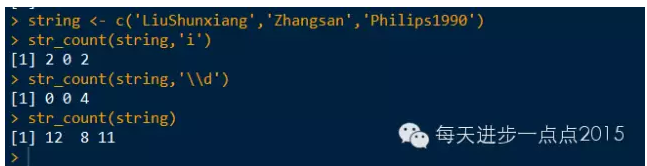
str_count(),计数能够匹配上的字符个数
str_count(string, pattern = "")
string:需要处理的字符串对象
pattern:指定匹配的模式,默认为"",计算每个字符串的长度
string <- c('LiuShunxiang','Zhangsan','Philips1990')
str_count(string,'i')
str_count(string,'\\d')
str_count(string)
下期将给大家介绍数据挖掘包caret。
每天进步一点点2015
学习与分享,取长补短,关注小号!

长按识别二维码 马上关注
