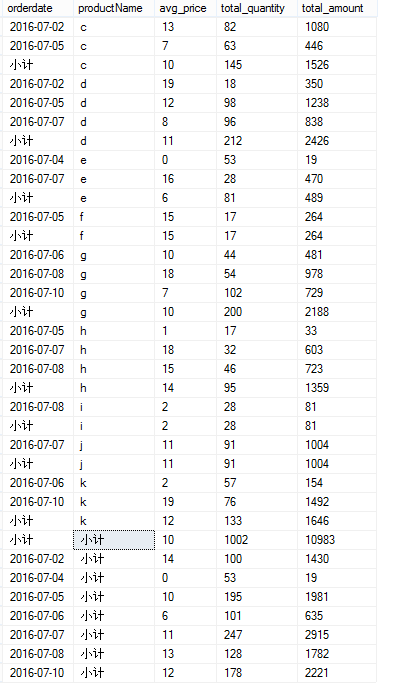
首先,造数据
IF OBJECT_ID('t_test','U') IS NOT NULL
DROP TABLE t_test;
CREATE TABLE t_test
(
id INT ,
productName VARCHAR(200) ,
price MONEY ,
quantity INT ,
amount INT ,
orderdate DATETIME
)
GO
--插入随机数据
DECLARE @i INT
DECLARE @price MONEY
DECLARE @date DATETIME
DECLARE @p INT
DECLARE @DateBase INT
DECLARE @Num int
SET @date = '2016-7-1'
SET @i = 1
WHILE ( @i < 20 )
BEGIN
SET @price= RAND() * 20
SET @p = CEILING(RAND() * 10)
SET @DateBase = CAST(RAND() * 10 AS INT)
SET @Num=RAND()*100
INSERT INTO t_test (id, productName, price, quantity, amount, orderdate )
VALUES ( @i, CHAR(97+@p), @price, @Num,
@price * @Num, @date + @DateBase )
SET @i = @i + 1
END
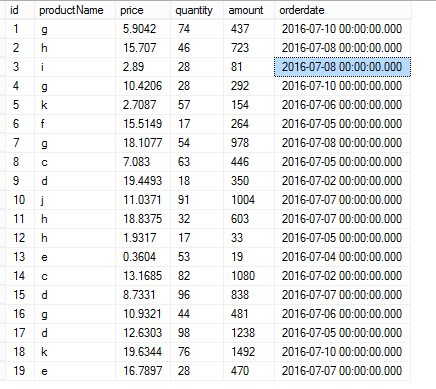
SELECT * FROM t_test
一、先看下ROLLUP的用法:
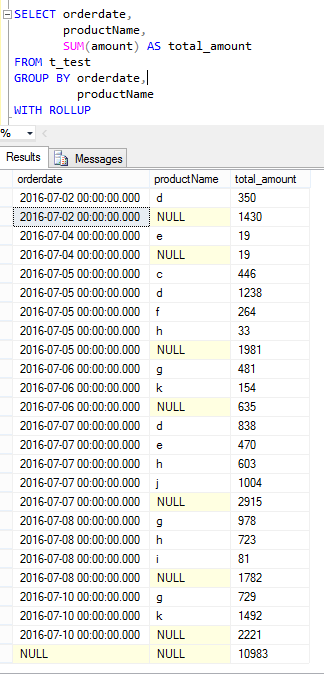
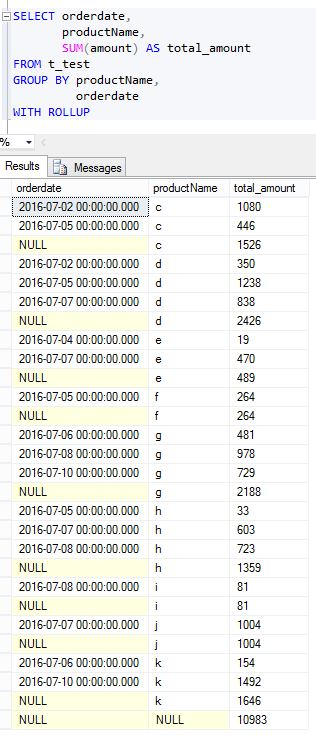
从以上两个截图可以看出,ROLLUP是 按照分组顺序,先对group by 后面的第一个字段进行分组,在组内进行统计,最后给出总的合计。
ps:
SELECT orderdate,
productName,
SUM(amount) / SUM(quantity) AS avg_price,
SUM(quantity) AS total_quantity,
SUM(amount) AS total_amount
FROM t_test
GROUP BY ROLLUP(orderdate, productName); 等同于 GROUP BY orderdate, productName WITH ROLLUP;
二、再看CUBE的用法:
SELECT orderdate,
productName,
SUM(amount) AS total_amount
FROM t_test
GROUP BY productName,
orderdate
WITH CUBE
结果如下:
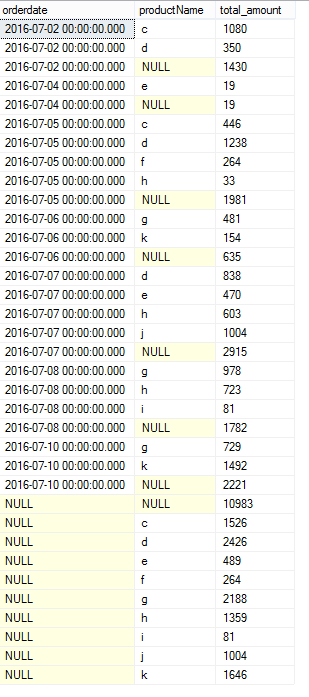
从结果可以看出,CUBE是对group by 后面的所有字段都分别进行组内统计,然后再给出总的合计。
三、GROUPING用法:
Grouping(字段名) 用来区分当前行是不是cube 或 rollup产生的统计行,一般和cube 或 rollup同时使用
Grouping(字段名)=1 说明是统计行,Grouping(字段名)=0 说明不是统计行
SELECT CASE WHEN GROUPING(orderdate) = 1 THEN N'小计'
ELSE CONVERT(VARCHAR(10), orderdate, 120)
END AS orderdate,
CASE WHEN GROUPING(productName) = 1 THEN N'小计'
ELSE productName
END AS productName,
SUM(amount) / SUM(quantity) AS avg_price,
SUM(quantity) AS total_quantity,
SUM(amount) AS total_amount
FROM t_test
GROUP BY orderdate, productName
WITH CUBE;
结果如下: