目前非代码的数据挖掘工具很多,但非开源,weka是一款开源软件。只要安装jdk环境就可使用(具体安装jdk可以百度)
本文将论述如何不用代码,使用weka操作,通过与文档频数与单词权的特征选择方法进行文本聚类(数据为附件)
第一步:将weka创建NetBeans文件目录中
将weka导入NetBeans软件中,
1 在某处新建一个WEKA-Rebuild目录,在它下面建一个目录叫src。在WEKA的安装目录中找到weka-src.jar,用winrar之类的解压缩软件打开,并把其中的目录weka解压缩到刚才建立的src目录下。 现在的目录结构应该是 WEKA-Rebuild -> src-> weka -> associations, attributeSelection, ... 打开NetBeans,“文件”菜单 - “新建项目” - 选择“常规”中的“基于现有源代码的Java项目” - “下一步”。“项目文件夹”选择WEKA-Rebuild目录,“项目名称”写weka-rebuild, “下一步”。在“源包文件夹”那里“添加文件夹”,找到src目录“打开”,“完成”。
2现在NetBeans左上方项目那一栏应该有粗体的“weka-rebuild”,这就是我们要编译的weka项目。右键点它,“生成项目”。下方会出现很多警告,不用管,不出意外的话最后会提示你生成项目成功。仍然右键点击“weka-rebuild”,“运行项目”。会弹出一个对话框让你设置主类。WEKA的主类可设置成weka.gui.Main。选中合适的主类后“确定”,不一会儿WEKA的界面就会出现在你面前,和开始菜单里运行的WEKA效果一样。
打开NetBeans软件。点击源包-weka.gui.,找到Main.java文件。双击,结果如下图所示。
第二步:执行weka
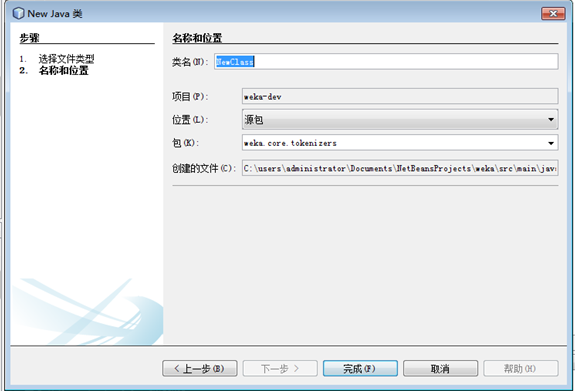
1.点击 源包-weka core tokenizers,右键 选择 新建java类。
修改类名为:CHWordTokenizer
选择包为:weka core tokenizers
点击完成 。结果见下图。
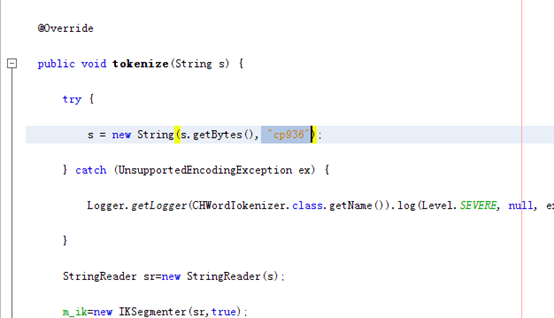
2.修改代码。将已给资料中的代码复制到文本中。
并将原橘黄色部分“Utf-8”改成“cp936”。如下图所示。
3.点开之前已经打开过的Main.java界面
点击 运行-运行文件
出现下图所示界面。

在该界面中,点击 application-explorer。返回weka界面,点击open file,载进中文文档。
第三步:创建中文文本文件。
1.将已有中文文本资料 sample 文件夹放入D盘。
2.打开weka - SimpleCLI。
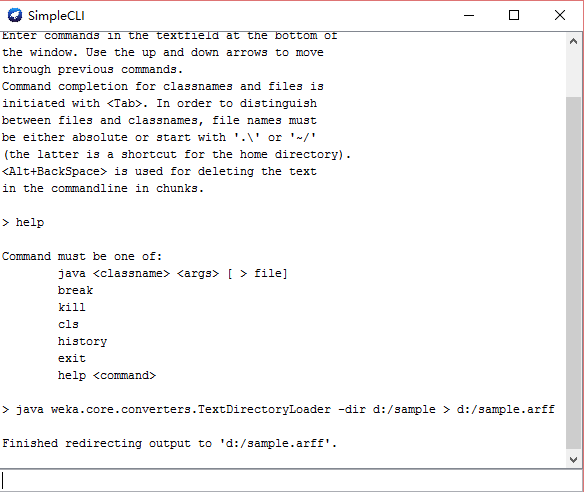
3.在输入栏输入 【java weka.core.converters.TextDirectoryLoader-dir d:/sample > d:/sample.arff】点击回车键运行。如下图所示。
4.D盘出现sample.arff文件。
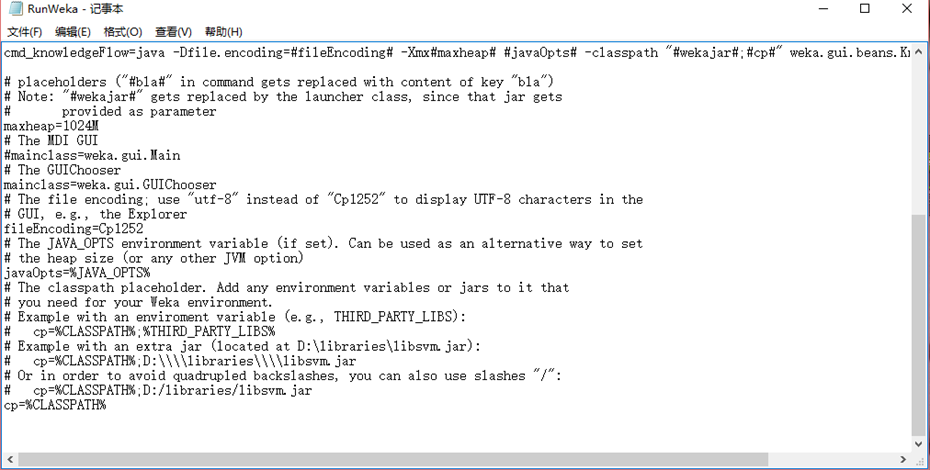
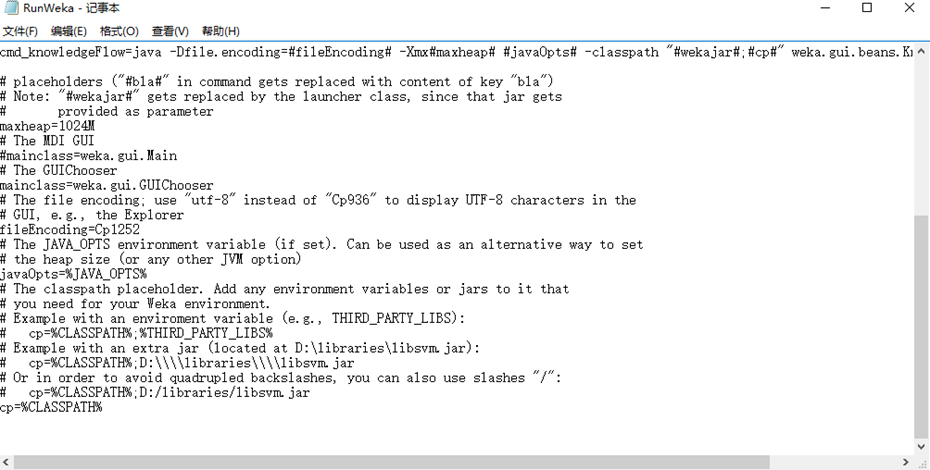
5.打开C盘weka的安装文件夹,找到RunWeka.ini文件
将cp1252替换成cp936(简体中文)
保存文件
第四步:改分词。
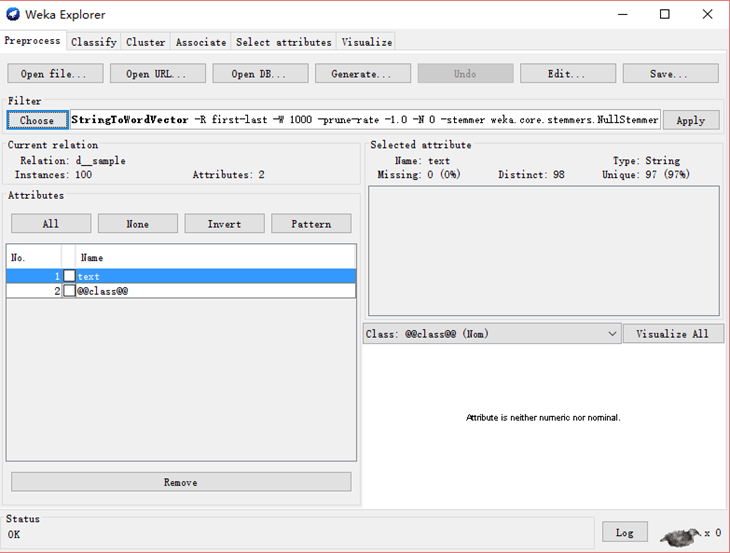
1.打开 weka-explorer-open file-sample .arff
2.Filter-choose-unsupervised-attribute-StringToWordVector
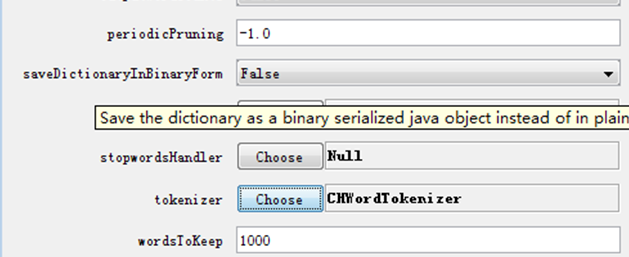
3.双击修改StringToWordVector 的参数。
将 tokenizer 改成 CHWordTokenizer
点击ok
4.点击apply,点击save,查看word形式(命名:sampleword1)的成果。
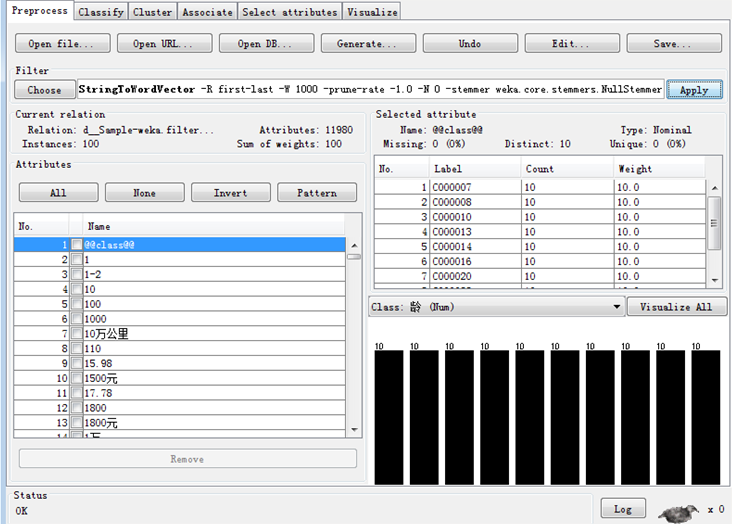
5.由下图可以看出,第1个的权重是1,第3个权重是1,第15个权重是1……

6.返回weka,重新加载sample.arff原始文件
再次打开Filter-choose-unsupervised-attribute-StringToWordVector
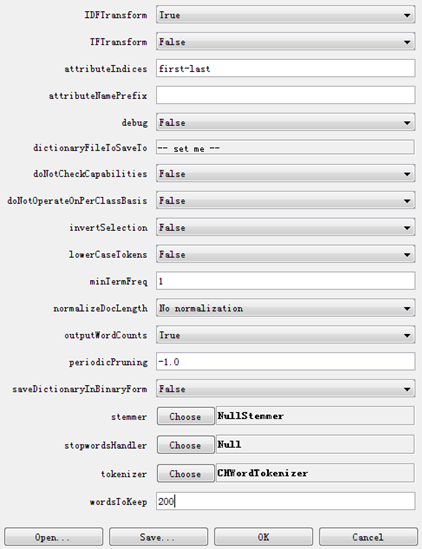
双击修改 StringToWordVector 的参数。
将 IDFTransform 改为 True (调平滑)
outputWordCounts 改为 True
minTermFreq改为 1
wordToKeep 改为 200
点击 OK 运行
7.点击apply,点击save,查看word形式(命名:sampleword2)的成果。
8.由下图可以看出,第1个的权重变成1。660731,第2个权重是2.040221,第5个权重是2.278869……
权重结果和sampleword1 不同。

9.返回weka,重新加载sample.arff原始文件
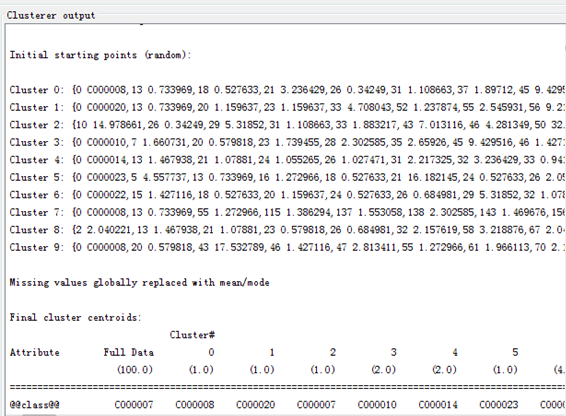
10.点击 Cluster-simpleMeans,双击调整参数。
11.点击 distanceFunction ,选择第二项 欧氏距离。
将 numClusters 改为 10
点击OK

12.点击start运行查看分析结果。