


本站文章版权归原作者及原出处所有 。内容为作者个人观点, 并不代表本站赞同其观点和对其真实性负责。本站是一个个人学习交流的平台,并不用于任何商业目的,如果有任何问题,请及时联系我们,我们将根据著作权人的要求,立即更正或者删除有关内容。本站拥有对此声明的最终解释权。
12 个评论
这样也可以呀
代码部分可以弄插入代码格式看着更舒服。
最近都玩R
简单,明了,实用
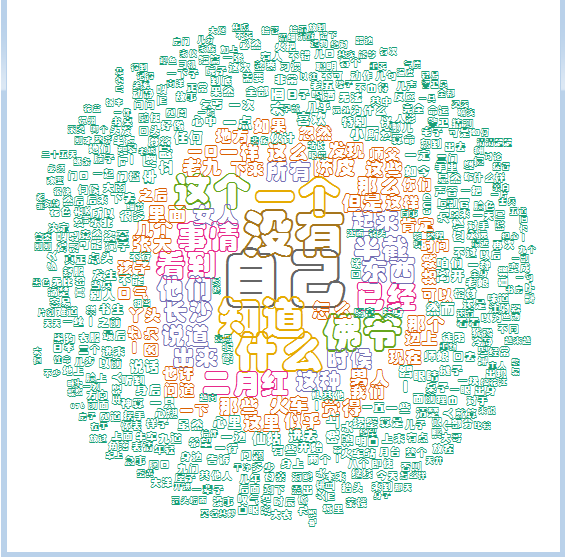
楼主方便把词云的csv文件 共享下
最后一句执行有错,改成wordcloud(myfile.freq$word,myfile.freq$freq.Freq,min.freq=3,random.order=FALSE,random.color=FALSE,colors=mycolors,family="myFont")
请楼主指教哈~
请楼主指教哈~
如果时间充裕,还可以增加些维度去分析,就会非常深层了,加油
wordcloud(myfile.freq$word,myfile.freq$freq.Freq,min.freq=3,random.order=FALSE,random.color=FALSE,colors=mycolors,family="myFont"), 最后一句有错,改了一下
只有900多行的原始数据分析的准不准啊