在前文— Numpy 中不得不知的4个重要函数中,我们分享过Numpy中几个特别实用的功能,今天再和大家分享Pandas中的几个重要函数。当然,Pandas提供了apply函数,使我们几乎可以将任何自定义函数应用在列的所有值上,但是这些内建函数,通常都是基于C语言实现,具有更高的运行效率,并且能够帮助我们提高代码的整洁性,减少重复造轮子。
idxmin() 和 idxmax()
Pandas 里面的 idxmin 、idxmax函数与Numpy中 argmax、argmin 用法大致相同,这些函数将返回第一次出现的最小/最大值的索引。在下面代码中,我们构建了一个DataFrame,通过idxmin() 函数帮助我们找到了每列的最小值所对应的索引。
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(12).reshape(3,4),columns=list('abcd'))
df
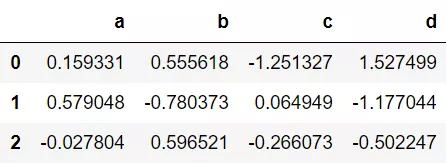
df.idxmin(axis=0)
idxmin() 函数接受一个可选参数axis, 可以用来控制是按照行还是列的维度查找最小值的索引,默认是axis=0。
a 2
b 1
c 0
d 1
dtype: int64
nsmallest() 和 nlargest()
在pandas库里面,我们常常关心的是最大的前几个,比如销售最好的几个产品。head()函数只能看到看到DataFrame的前几行,如果需要看到最大或者最小的几行就需要先进行排序。max()和min()可以看到最大或者最小值,但是只能看到一个值。
假设我们有一份活动的费用表:
data = {
'Name': ['Bob','Bob','Bob', 'Mark', 'Jess', 'Jess','Jhon'],
'Activity': ['A', 'A', 'B','A','C','C','D'],
'Spend': [121, 98, 51,94,145,93,137],
}
df = pd.DataFrame(data)
df
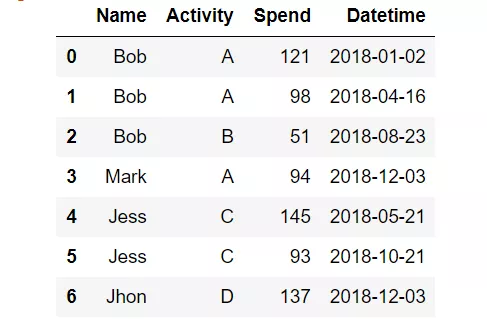 活动费用表
活动费用表
现在,让我们康康最费钱的三次活动?
df.nlargest(n=3,columns='Spend')
 花费最高的三次活动
花费最高的三次活动
cumcount() 和 cumsum()
这是两个非常酷的内建函数,用于分组累加计数和累加求和,可以为您提供许多帮助。我们还是基于上一节中的活动费用表,来进行演示。
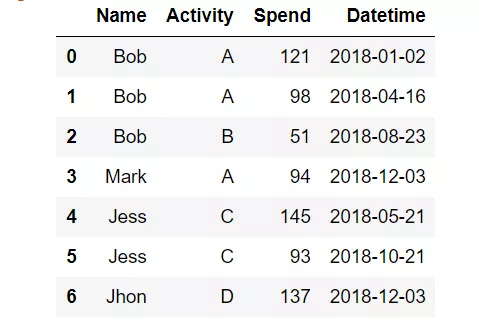 活动费用表
活动费用表
现在我们想完成以下几个功能:
•按照Name分组统计,每个人累计参加活动次数•按照Name分组统计,每个人累计参加活动费用
df['Activity_count'] = df.groupby('Name')['Activity'].cumcount()
df['Activity_sum'] = df.groupby('Name')['Spend'].cumsum()
df

我们可以看到,我们的累计计数和累加求和都是在分组的维度上进行聚合的,是不是十分方便呢?
其实,pandas中相关的函数还有cummax()、cummin() 、cumprod() 等,这里就不一一介绍了,感兴趣的可以自行查找pandas官方文档。
欢迎关注我的公众号“数据科学杂谈”,原创技术文章第一时间推送。

